以下參考課程 LLM Twin: Building Your Production-Ready AI Replica 撰寫
在探討完設計模式後,我們將聚焦第三堂課中提及的 Change Data Capture (CDC) 技術。在構建 GenAI 服務時,由於來源資料會不斷更新,比如在課程案例中,我們需要確保來自 LinkedIn、Medium 和 GitHub 等多個平台的資料和資料庫保持同步和最新,而 CDC 正是解決這一問題的方法。
接下來的三天,我將逐步由淺入深地介紹 CDC 技術。
Change Data Capture (CDC) 是一種用於捕捉資料庫變更的技術。CDC 的主要功能包括:
CDC 在現代數據系統中的應用非常廣泛。首先,它通過實時同步變更至目標資料庫,確保服務之間的一致性。其次,CDC 只處理變更數據,優化了系統效能。此外,CDC 支援事件驅動架構,將數據變更視為觸發系統操作的事件,統一接收端介面。
在分佈式系統中,CDC 解決了一致性問題:它解耦了資料庫更新和消息發送,將資料庫的變動作為觸發事件,即使應用程序故障,也能可靠地發送消息。這些特性提升了系統的靈活性、效率和可靠性,使 CDC 特別適合複雜的分佈式環境。
透過課程的圖片,我們可以拆解 CDC 的工作流程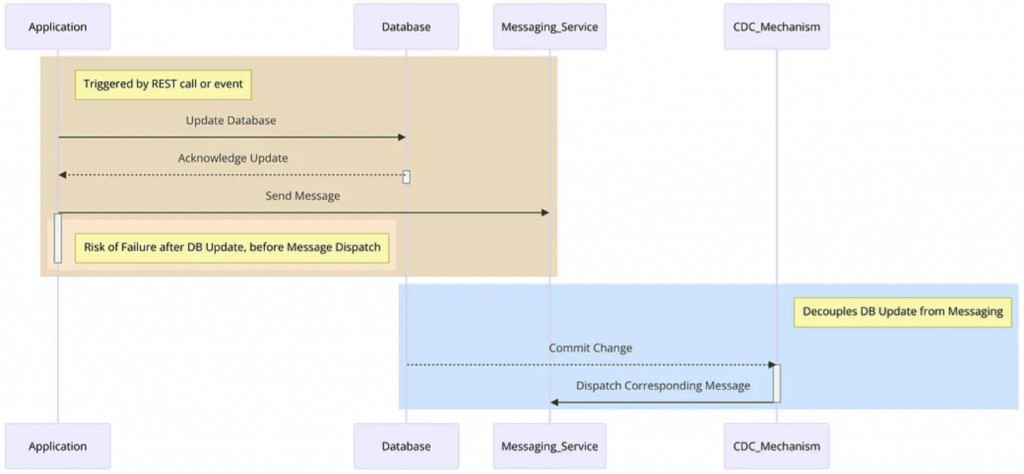
在 GenAI 系統中,特別是在實現**檢索增強生成(RAG)**時,CDC 扮演著關鍵角色:
# 偽代碼範例
def on_document_change(change_event):
doc = change_event['fullDocument']
embeddings = generate_embeddings(doc['content'])
vector_db.upsert(doc['id'], embeddings)
cdc_stream.watch(on_document_change)
def on_training_data_change(change_event):
data = change_event['fullDocument']
training_queue.push(data)
if training_queue.size > THRESHOLD:
trigger_model_fine_tuning()
cdc_stream.watch(on_training_data_change)
def on_image_change(change_event):
image = change_event['fullDocument']
description = generate_image_description(image['url'])
text_db.update(image['id'], {'description': description})
cdc_stream.watch(on_image_change)


 iThome鐵人賽
iThome鐵人賽