在經歷了前面的模型建立、訓練、評估與優化過程後,我們最終得到了滿意的模型。這些步驟的最終目的是希望模型能夠在真實世界中產生準確且有價值的預測結果。本章將介紹如何在部署給使用者前運用測試集進行預測測試,並分析如何通過檢查模型在測試集上的表現來分辨過擬合(overfitting)和欠擬合(underfitting)問題。

[Dall-E]
之前提過,我們會把數據分為訓練集、驗證集和測試集。訓練集用於訓練模型,驗證集用來調整模型參數,而測試集則保留到最終階段,專門用於檢驗模型的實際預測能力。
為什麼我們要使用測試集來進行預測測試呢?因為測試集是模型在訓練和調參過程中從未見過的數據。它可以有效地模擬模型在真實環境中的表現。當我們隨時拿到新數據並輸入到模型中,得到的預測結果即為模型的最終輸出,提供給用戶。
在實際預測中,我們只需要輸入特徵,就可以得到輸出結果。舉個例子,假設我們使用一個訓練好的模型來預測房地產價格,我們會將測試集中的房屋特徵(如面積、地段、房齡等)輸入給模型,模型會根據這些特徵預測房屋的價格。這些預測結果將直接影響房地產投資決策,因此它們必須既準確又具有解釋性。除了預測價格,我們還可以提供模型對預測結果的解釋,如哪些特徵對預測結果影響最大,以幫助使用者更好地理解模型的預測並提高對模型的信任。
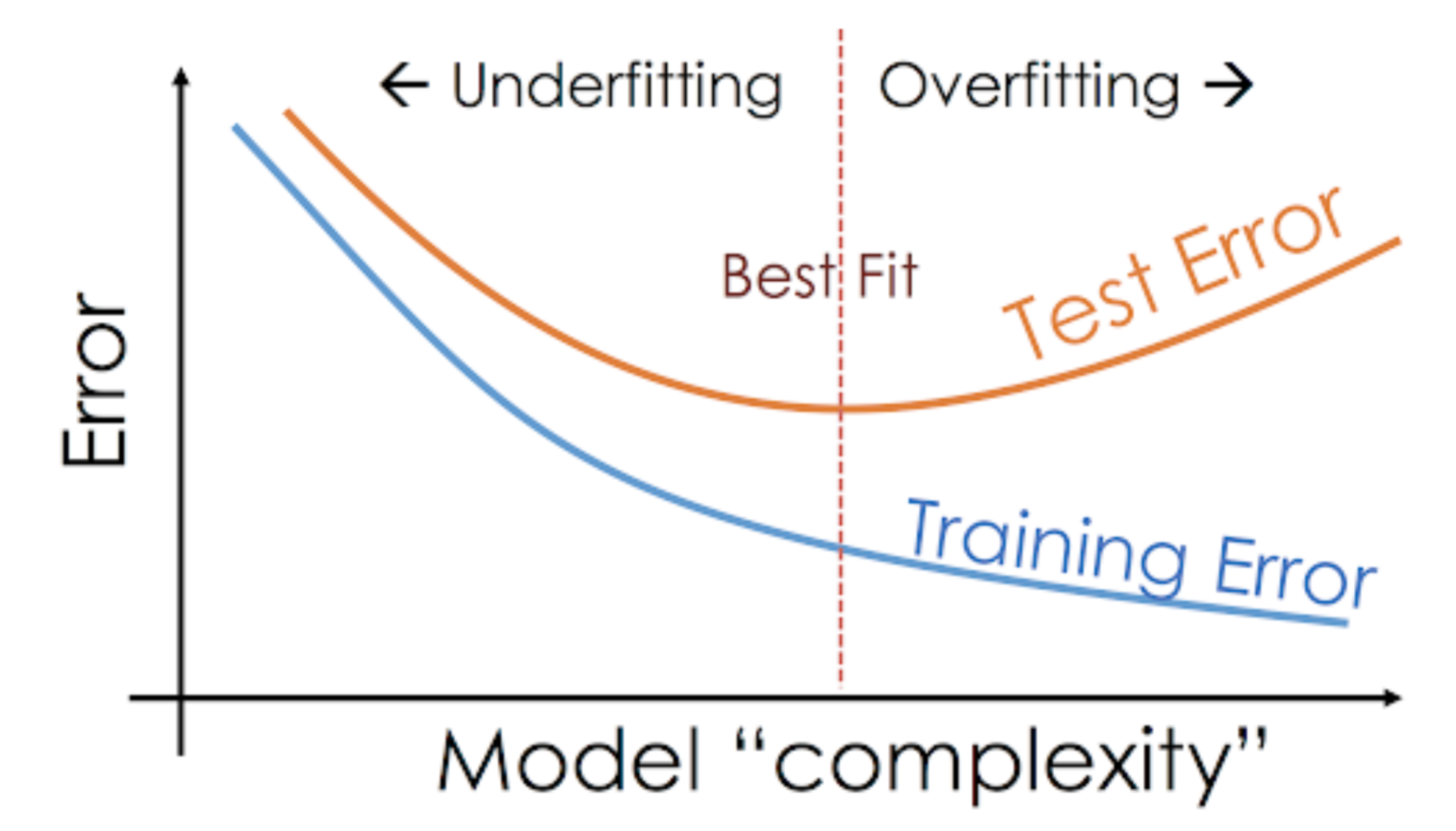
在模型預測過程中,我們需要特別注意檢查模型是否存在過擬合或欠擬合的問題,這直接影響模型在未見數據上的表現。我們再複習一下這兩者的解釋吧!
模型預測是機器學習應用中的目的地,它將我們訓練好的模型與實際應用場景連接起來。通過使用測試集來進行預測測試,我們可以有效評估模型的泛化能力,並檢查模型是否存在過擬合或欠擬合的問題。最終,確保模型在實際應用中能夠產生準確、穩定且具有解釋性的預測結果。

[Dall-E]


{kind=link}