選擇演算法後,我們通常會發現還有許多設定可以進行調整。模型優化就像是對一台精密儀器進行校準,想像你正在調整一台望遠鏡🔭,即使是很小的調整,也可能讓你看到更清晰、更遠的景象。在機器學習中,這種調整主要集中在「超參數」上,每一個微小的改變都可能帶來顯著的性能提升📈。為了理解什麼是超參數,我們先來區分兩個概念:
理解這兩者的區別很重要,因為在模型優化中,我們主要關注超參數的調整。接下來,我們將深入探討各種優化方法,解釋它們的使用步驟和適用場景及優缺點。
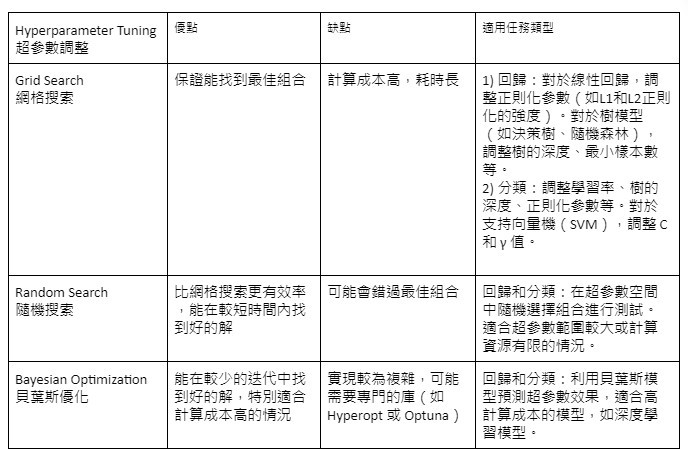
超參數調整是模型優化中最常用的方法之一。它就像是調整一台複雜機器的各個旋鈕,直到找到最佳的設定組合。常見的超參數包括學習率(決定每次更新模型權重的步長)、樹的深度(對於決策樹算法來說)、以及正則化強度(控制模型的複雜度)。微調這些超參數可以顯著提高模型的預測準確性。常見的超參數調整方法包括:
🔍網格搜索(Grid Search):系統地測試所有可能的超參數組合,以找到最佳設定。這種方法可以確保找到全局最優解,但計算量大,時間消耗高。
1) 定義要調整的超參數及其可能的值範圍
2) 生成所有可能的超參數組合
3) 對每種組合訓練一個模型並評估其性能
4) 選擇性能最佳的超參數組合
🎲隨機搜索(Random Search):在超參數空間中隨機選擇若干組合進行測試。這種方法比網格搜索更高效,能夠在較短的時間內找到良好的超參數組合。
1) 定義每個超參數的可能值範圍或分佈
2) 隨機生成預定數量的超參數組合
3) 對每種組合訓練模型並評估性能
4) 選擇性能最佳的組合
📈貝葉斯優化(Bayesian Optimization):貝葉斯優化使用機率模型來預測哪些超參數可能會有好的效果,然後優先嘗試這些參數。
1) 定義超參數空間
2) 選擇初始的幾個超參數組合進行評估
3) 基於已有的結果,使用高斯過程等方法建立超參數與模型性能之間的關係模型
4) 使用這個模型來預測哪些超參數組合可能會有好的效果
5) 評估這些新的超參數組合
6) 更新模型,重複步驟 4-5 直到達到停止條件
正則化技術是用來防止模型過擬合的關鍵手段。過擬合指的是模型在訓練數據上表現很好,但在未見數據上表現不佳。正則化通過在模型的損失函數中添加懲罰項來限制模型的複雜度,從而提升模型的泛化能力。常見的正則化技術包括之前演算法文章提過的:
📐L1 正則化(Lasso):通過添加參數的絕對值和作為懲罰項,來驅使某些參數變為零,實現特徵選擇的效果。這有助於簡化模型並提高其可解釋性。
1) 在模型的損失函數中添加 λ∑|w_i| 項,其中 λ 是正則化強度,w_i 是模型參數
2) 訓練模型時最小化新的損失函數
3) 根據需要調整 λ 值
🏔️L2 正則化(Ridge):通過添加參數的平方和作為懲罰項,來防止模型過度擬合。這種方法能夠平滑模型的學習過程,使其更加穩定。
1) 在模型的損失函數中添加 λ∑(w_i)^2 項
2) 訓練模型時最小化新的損失函數
3) 根據需要調整 λ 值
適用任務類型:
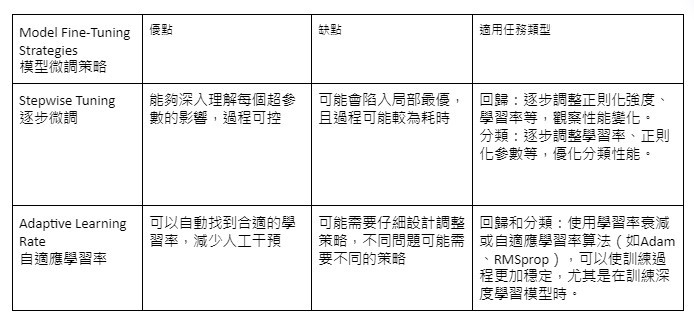
模型微調策略是針對模型訓練過程中的細節進行調整,以進一步提升模型的性能。這些策略包括:
📈逐步微調(Stepwise Tuning):逐步調整一個或少數幾個模型的超參數,並觀察每次調整對模型性能的影響,然後決定下一步的調整方向。這種方法可以幫助找到最佳的超參數組合,逐步提高模型的效果。
1) 選擇一個初始的超參數組合
2) 選擇一個要調整的超參數
3) 在一個小範圍內調整該超參數,評估模型性能
4) 如果性能提升,則保留新的值;否則,嘗試其他方向的調整
5) 重複步驟 2-4,直到性能不再顯著提升
📊自適應學習率(Adaptive Learning Rate):根據訓練過程的變化動態自動調整學習率。例如,使用學習率衰減策略來逐步減小學習率,這樣可以在訓練的後期提高模型的穩定性和收斂速度。
1) 設定初始學習率和調整策略(如學習率衰減)
2) 在訓練過程中監控性能指標(如驗證集損失)
3) 根據性能變化自動調整學習率
4) 如果性能停滯,降低學習率
5) 如果性能快速提升,可以略微提高學習率
模型優化是一個需要耐心和創造力的過程。通過調整超參數、應用正則化技術、採用適當的微調策略,我們可以顯著提升模型的性能。不同的問題可能需要不同的優化策略,持續實驗、學習和調整是提高模型性能的關鍵。隨著你在這個領域積累更多經驗,你會逐漸培養出一種直覺,知道在什麼情況下應該使用哪種優化技術。

