day19、day20我們獲取了我們資料的來源,並且儲存成txt檔案,那麼接下來我們會運用這些外部資料源來進行LLM的提示工程RAG,再配合LnagChain框架以及修改Prompt,使他可以精準的呈現架構圖程式碼。
先根據我們之前獲取的本地資料源來進行處理
這部分和之前一樣,主要引入Model以及定義DocumentLoader 的class
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
# 1. Create model
os.environ["OPENAI_API_KEY"] = ""
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
from typing import Iterator
# 2. DocumentLoader
class CustomDocumentLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]:
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number,
"source": self.file_path},
)
line_number += 1
這部分我們先手動的寫入要引入的文件,當然這個做法我們會在後面進行改進
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 3. LoaderFile And Split And Save
print("chunk長度: ", end="")
chunk_size = 1200
print(chunk_size)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=100)
loader = CustomDocumentLoader("Dac_Guides/Diagram.txt")
docs = list(loader.lazy_load())
all_text = "".join(doc.page_content for doc in docs)
print("文件1長度: ", end="")
print(len(all_text))
splits = text_splitter.split_documents(docs)
loader2 = CustomDocumentLoader("Dac_Guides/Node.txt")
docs2 = list(loader2.lazy_load())
all_text2 = "".join(doc2.page_content for doc2 in docs2)
print("文件2長度: ", end="")
print(len(all_text2))
splits2 = text_splitter.split_documents(docs2)
loader3 = CustomDocumentLoader("Dac_Guides/Cluster.txt")
docs3 = list(loader3.lazy_load())
all_text3 = "".join(doc3.page_content for doc3 in docs3)
print("文件3長度: ", end="")
print(len(all_text3))
splits3 = text_splitter.split_documents(docs3)
loader4 = CustomDocumentLoader("Dac_Guides/Edges.txt")
docs4 = list(loader4.lazy_load())
all_text4 = "".join(doc4.page_content for doc4 in docs4)
print("文件4長度: ", end="")
print(len(all_text4))
splits4 = text_splitter.split_documents(docs4)
loader5 = CustomDocumentLoader("Dac_Nodes/GCPNode.txt")
docs5 = list(loader5.lazy_load())
all_text5 = "".join(doc5.page_content for doc5 in docs5)
print("文件5長度: ", end="")
print(len(all_text5))
splits5 = text_splitter.split_documents(docs5)
vectorstore = Chroma.from_documents(
documents=splits+splits2+splits3+splits4+splits5, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
# 4. Create chain
template = """你將成為一個雲端架構圖設計師,使用 Python 的 diagrams 函式庫,生成GCP的雲端架構圖。
請依照使用者的需求,設計一個安全、高效的雲端架構,並確保使用相關的雲端服務,如 VPC、負載均衡、Kubernetes、儲存服務、資料庫等。
你可以自由發揮,但每個服務的選擇都需要合理解釋,並考慮擴展性、安全性和效能優化。
以下是一個基本範例,你可以基於此來自訂使用者的需求:
```python
from diagrams import Cluster, Diagram
from diagrams.gcp.network import VPC, LoadBalancing, Armor, CDN, DNS,VPN
from diagrams.gcp.compute import KubernetesEngine
from diagrams.gcp.database import Firestore, SQL, Memorystore
from diagrams.gcp.storage import Filestore, Storage
from diagrams.gcp.operations import Monitoring
from diagrams.gcp.security import Iam, KeyManagementService, SecurityCommandCenter
from diagrams.onprem.client import Users
# 使用者可調整這個架構設計
with Diagram("Secure Website System Architecture", show=False):
# 定義使用者、網路、計算、資料庫、儲存、運營和安全等模組
# 添加每個服務的設計思路
```
請你自動根據使用者給定的架構需求,進行設計,並解釋每個服務的選擇理由。
有以下簡單的規則請注意
- 將每個雲端服務分別定義,並使用合適的 `Cluster` 來組織它們。
- 每個 `Cluster` 的 `graph_attr` 應該設置顏色。
- 請用 ``` ``` 來包裹程式碼,並確保裡面只有程式碼。
- security這類別是自由的!,不需要連結到其他服務
以下是參考資料:
{context}
最後是重要的使用者要求:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
這裡我們請他生成一個網站系統,當作範例
rchain_response = rag_chain.invoke("我想要一個保證安全性的網站系統雲端架構圖")
print(rchain_response)
# langChain
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from typing import Iterator
# 1. Create model
os.environ["OPENAI_API_KEY"] = ""
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. DocumentLoader
class CustomDocumentLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]:
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number,
"source": self.file_path},
)
line_number += 1
# 3. LoaderFile And Split And Save
print("chunk長度: ", end="")
chunk_size = 1200
print(chunk_size)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=100)
loader = CustomDocumentLoader("Dac_Guides/Diagram.txt")
docs = list(loader.lazy_load())
all_text = "".join(doc.page_content for doc in docs)
print("文件1長度: ", end="")
print(len(all_text))
splits = text_splitter.split_documents(docs)
loader2 = CustomDocumentLoader("Dac_Guides/Node.txt")
docs2 = list(loader2.lazy_load())
all_text2 = "".join(doc2.page_content for doc2 in docs2)
print("文件2長度: ", end="")
print(len(all_text2))
splits2 = text_splitter.split_documents(docs2)
loader3 = CustomDocumentLoader("Dac_Guides/Cluster.txt")
docs3 = list(loader3.lazy_load())
all_text3 = "".join(doc3.page_content for doc3 in docs3)
print("文件3長度: ", end="")
print(len(all_text3))
splits3 = text_splitter.split_documents(docs3)
loader4 = CustomDocumentLoader("Dac_Guides/Edges.txt")
docs4 = list(loader4.lazy_load())
all_text4 = "".join(doc4.page_content for doc4 in docs4)
print("文件4長度: ", end="")
print(len(all_text4))
splits4 = text_splitter.split_documents(docs4)
loader5 = CustomDocumentLoader("Dac_Nodes/GCPNode.txt")
docs5 = list(loader5.lazy_load())
all_text5 = "".join(doc5.page_content for doc5 in docs5)
print("文件5長度: ", end="")
print(len(all_text5))
splits5 = text_splitter.split_documents(docs5)
vectorstore = Chroma.from_documents(
documents=splits+splits2+splits3+splits4+splits5, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
# 4. Create chain
template = """你將成為一個雲端架構圖設計師,使用 Python 的 diagrams 函式庫,生成GCP的雲端架構圖。
請依照使用者的需求,設計一個安全、高效的雲端架構,並確保使用相關的雲端服務,如 VPC、負載均衡、Kubernetes、儲存服務、資料庫等。
你可以自由發揮,但每個服務的選擇都需要合理解釋,並考慮擴展性、安全性和效能優化。
以下是一個基本範例,你可以基於此來自訂使用者的需求:
```python
from diagrams import Cluster, Diagram
from diagrams.gcp.network import VPC, LoadBalancing, Armor, CDN, DNS,VPN
from diagrams.gcp.compute import KubernetesEngine
from diagrams.gcp.database import Firestore, SQL, Memorystore
from diagrams.gcp.storage import Filestore, Storage
from diagrams.gcp.operations import Monitoring
from diagrams.gcp.security import Iam, KeyManagementService, SecurityCommandCenter
from diagrams.onprem.client import Users
# 使用者可調整這個架構設計
with Diagram("Secure Website System Architecture", show=False):
# 定義使用者、網路、計算、資料庫、儲存、運營和安全等模組
# 添加每個服務的設計思路
```
請你自動根據使用者給定的架構需求,進行設計,並解釋每個服務的選擇理由。
有以下簡單的規則請注意
- 將每個雲端服務分別定義,並使用合適的 `Cluster` 來組織它們。
- 每個 `Cluster` 的 `graph_attr` 應該設置顏色。
- 請用 ``` ``` 來包裹程式碼,並確保裡面只有程式碼。
- security這類別是自由的!,不需要連結到其他服務
以下是參考資料:
{context}
最後是重要的使用者要求:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
rchain_response = rag_chain.invoke("我想要一個保證安全性的網站系統雲端架構圖")
print(rchain_response)
python day21.py
chunk長度: 1200
文件1長度: 2378
文件2長度: 3556
文件3長度: 1750
文件4長度: 1996
文件5長度: 3253
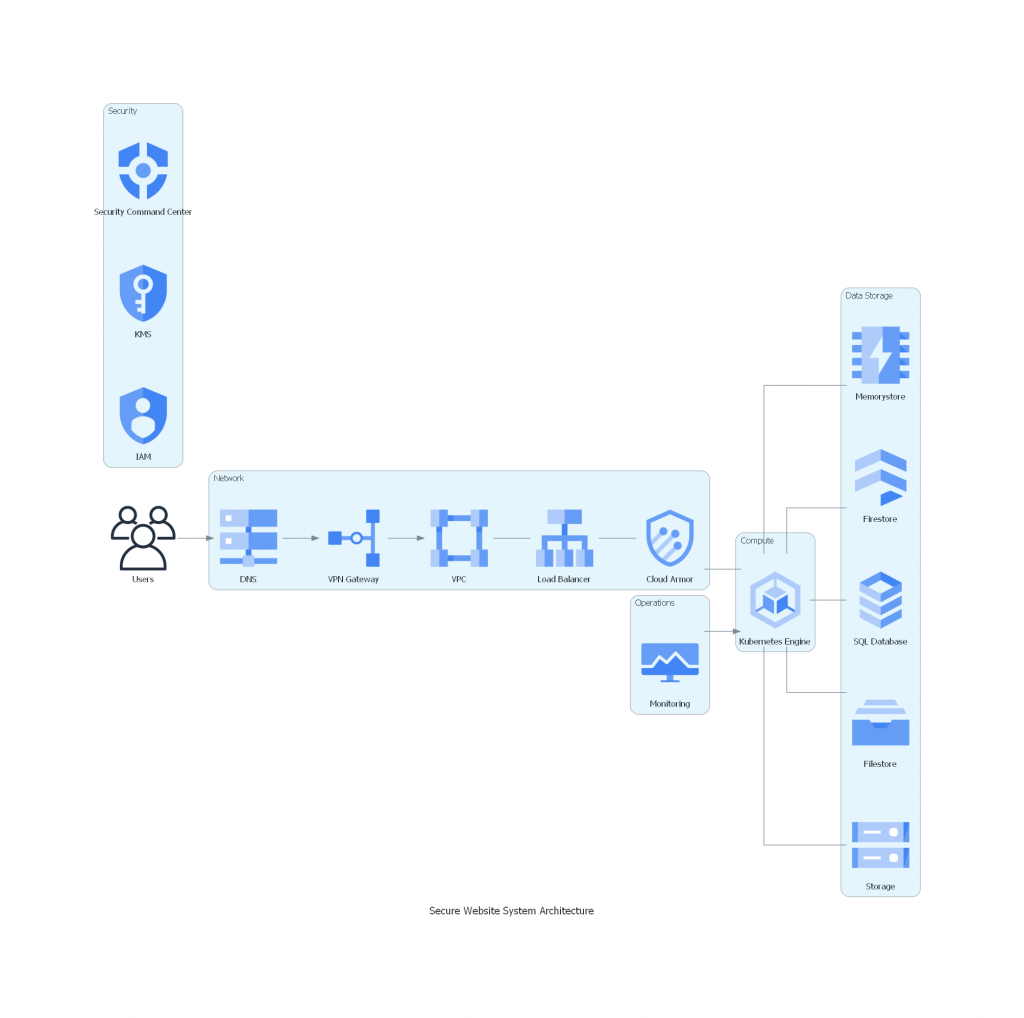
```python
from diagrams import Cluster, Diagram
from diagrams.gcp.network import VPC, LoadBalancing, Armor, DNS, VPN
from diagrams.gcp.compute import KubernetesEngine
from diagrams.gcp.database import Firestore, SQL, Memorystore
from diagrams.gcp.storage import Filestore, Storage
from diagrams.gcp.operations import Monitoring
from diagrams.gcp.security import Iam, KeyManagementService, SecurityCommandCenter
from diagrams.onprem.client import Users
# 定義網站系統的安全雲端架構
with Diagram("Secure Website System Architecture", show=False):
users = Users("Users")
with Cluster("Network", graph_attr={"color": "lightblue"}):
vpc = VPC("VPC")
load_balancer = LoadBalancing("Load Balancer")
dns = DNS("DNS")
vpn = VPN("VPN Gateway")
cdn = Armor("Cloud Armor")
vpc - load_balancer
load_balancer - cdn
with Cluster("Compute", graph_attr={"color": "lightgreen"}):
gke = KubernetesEngine("Kubernetes Engine")
cdn - gke
with Cluster("Data Storage", graph_attr={"color": "orange"}):
storage = Storage("Storage")
filestore = Filestore("Filestore")
database = SQL("SQL Database")
firestore = Firestore("Firestore")
memorystore = Memorystore("Memorystore")
gke - [storage, filestore, database, firestore, memorystore]
with Cluster("Operations", graph_attr={"color": "lightyellow"}):
monitoring = Monitoring("Monitoring")
monitoring >> gke
with Cluster("Security", graph_attr={"color": "red"}):
iam = Iam("IAM")
kms = KeyManagementService("KMS")
security_command_center = SecurityCommandCenter("Security Command Center")
# they work independently to ensure security and compliance
users >> dns
dns >> vpn
vpn >> vpc
```
### 解釋每個服務的選擇理由:
- **VPC (Virtual Private Cloud)**: 提供隔離的網路環境,確保服務之間的通信安全。
- **Load Balancing**: 分散流量,提高系統的可靠性與效能。
- **DNS**: 提供域名解析服務,讓用戶可以通過域名訪問網站。
- **VPN**: 保證內部網路的安全通信,尤其適用於管理員訪問。
- **Cloud Armor (CDN)**: 提供防火牆功能,保護應用免受DDoS攻擊,同時加快內容分發。
- **Kubernetes Engine**: 高效管理和運行應用的容器化服務,提供自動擴展和高可用性。
- **Storage 和 Filestore**: 用於存儲靜態文件和數據備份。
- **SQL Database 和 Firestore**: 提供結構化和非結構化數據存儲解決方案,滿足不同的應用需求。
- **Memorystore**: 提供緩存服務,加快數據讀取速度,提高應用性能。
- **Monitoring**: 實時監控系統運行情況,及時發現和解決問題。
- **IAM (Identity and Access Management)**: 管理用戶權限,確保只有授權人員可以訪問資源。
- **Key Management Service (KMS)**: 管理加密密鑰,保護數據在傳輸和存儲中的安全。
- **Security Command Center**: 提供集中化的安全管理,檢測和響應潛在威脅。
因為目前LLM回應的程式碼,我們還沒在程式中去編譯和錯誤處理,我們先手動編譯