之前在第三天的內容中提過了卷積神經網絡CNN,作為計算機視覺的核心技術之一,正在幫助機器「看見」並理解這個世界。無論是自動駕駛、醫學影像診斷還是圖像分類,CNN都扮演著重要角色。今天,我們將深入探討CNN的運作原理,並且手把手帶你實作一個基於CIFAR-10數據集的圖像分類模型,來看看AI如何透過「眼睛」認識世界吧!
一、解構卷積神經網絡(CNN)
<卷積核Kernel>
卷積核的大小通常是3x3或5x5,它定義了提取特徵的範圍、也會影響特徵圖的尺寸和輸出的分辨率,每個卷積核所學習的特徵不同:
例如一個卷積核可以學習檢測水平邊緣,另一個可以檢測垂直邊緣或更復雜的圖像紋理。
最大池化
最常用的一種池化方法,將輸入圖像分成不重疊的小區塊,並從每個區塊中選擇最大值作為輸出。這有助於保留最強的激活信號,並忽略無關的噪聲,像是2x2的最大池化會將4個像素中的最大值作為池化結果。
平均池化
取區塊內所有值的平均值。這種方法更平滑,但在某些情況下,可能會降低模型的識別精度。
二、實作基於CIFAR-10數據集的CNN圖像分類模型
什麼是CIFAR-10數據集?
由10個類別的60000張彩色圖像組成的,圖像尺寸為32x32,每個類別有6000張圖片,這些類別包括:飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船和卡車。它是一個常見的圖像分類基準數據集,適合用於測試卷積神經網絡的性能。
實作訓練CNN
接下來我們就依據CIFAR-10作為資料庫,用python3寫出一個CNN模型讓他可以辨別資料庫中的內容,並實測他的準確率有多少。
我用的是Jupyter Notebook並使用tensorflow的虛擬環境:
STEP 1 加載CIFAR-10數據集
註:數據集中的照片為32x32像素,放大至電腦上看就會是模糊的可以看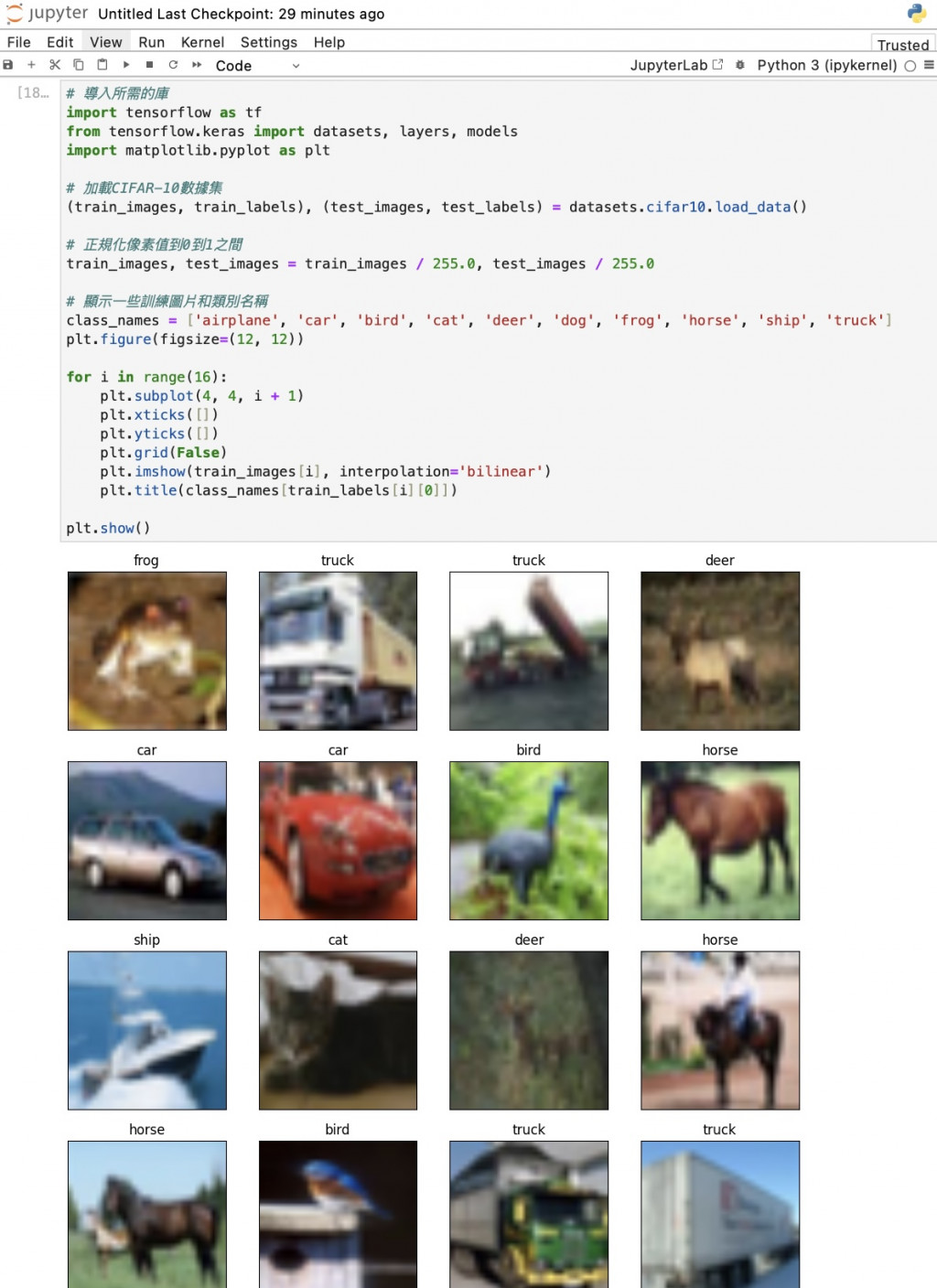
STEP 2 定義、編譯、訓練CNN模型

會看到訓練模型時的準確度越來越高、損失越來越低
STEP 3 評估模型
對數據進行評估,可以得到它最終訓練完的損失以及準確度
STEP 4 查看成果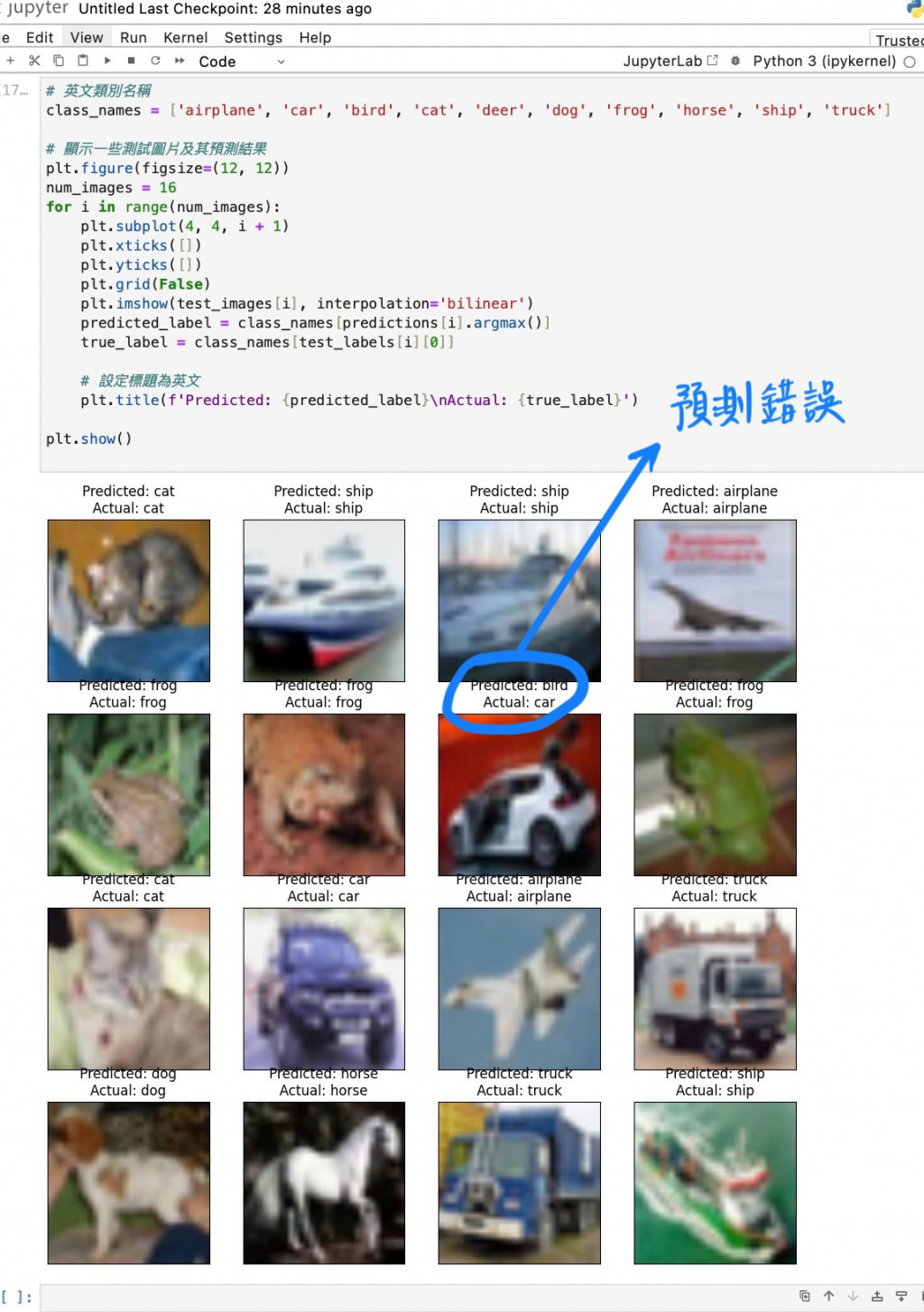
儘管CIFAR-10數據集的圖像相對簡單,CNN的強大能力依然展露無遺。隨著模型的優化和更多數據的引入,AI在圖像分類上的準確度會持續提高。在未來,這樣的技術將會越來越成熟,不妨多嘗試不同的數據集和模型結構,不僅對CNN的應用更加熟練深入還能探索CNN更多領域的應用潛力。****

