Prometheus 是目前主流的指標收集工具,指標可以透過專用的 PromQL 語法查詢,並且提供 Web UI 與告警機制。Prometheus 起源於 2012 年,由音樂分享平台 SoundCloud 開發,當時該公司面臨著管理數百個微服務和數千個 Process 的挑戰,因此開發出替代 StatsD 和 Graphite 的監控解決方案。

Prometheus Metrics 以文字檔的方式揭露,並透過 Exporter 或 Prometheus Client Library 生成,格式如下:
# HELP container_memory_usage_bytes Current memory usage in bytes
# TYPE container_memory_usage_bytes gauge
container_memory_usage_bytes{image="prom/prometheus:v2.54.0",name="prometheus"} 6.4237568e+07
container_memory_usage_bytes{image="grafana/grafana:11.2.0",name="grafana"} 1.08425216e+08
container_memory_usage_bytes{image="gcr.io/cadvisor/cadvisor:v0.49.1",name="cadvisor"} 8.8117248e+07
# HELP fastapi_requests Total count of requests by method and path.
# TYPE fastapi_requests counter
fastapi_requests_total{method="GET",path="/"} 10.0
fastapi_requests_total{method="GET",path="/cpu_task"} 10.0
fastapi_requests_total{method="GET",path="/io_task"} 10.0
# HELP fastapi_responses Total count of responses by method, path and status codes.
# TYPE fastapi_responses counter
fastapi_responses_total{method="GET",path="/random_status",status_code="200"} 5.0
fastapi_responses_total{method="GET",path="/random_status",status_code="300"} 2.0

Prometheus 會定期從服務中抓取指標資料,並標上時間戳後儲存。這樣的機制能幫助我們觀察指標的變化趨勢與異常狀況。
Grafana Explore Metrics 是 Grafana 11 在 GrafanaCON 2024 宣布的新功能,提供使用者一個更直觀的方式來探索 Prometheus 指標,即使不了解 PromQL 也能輕鬆使用。
在左側選單選擇 Explore,並進入 Metrics 頁籤。
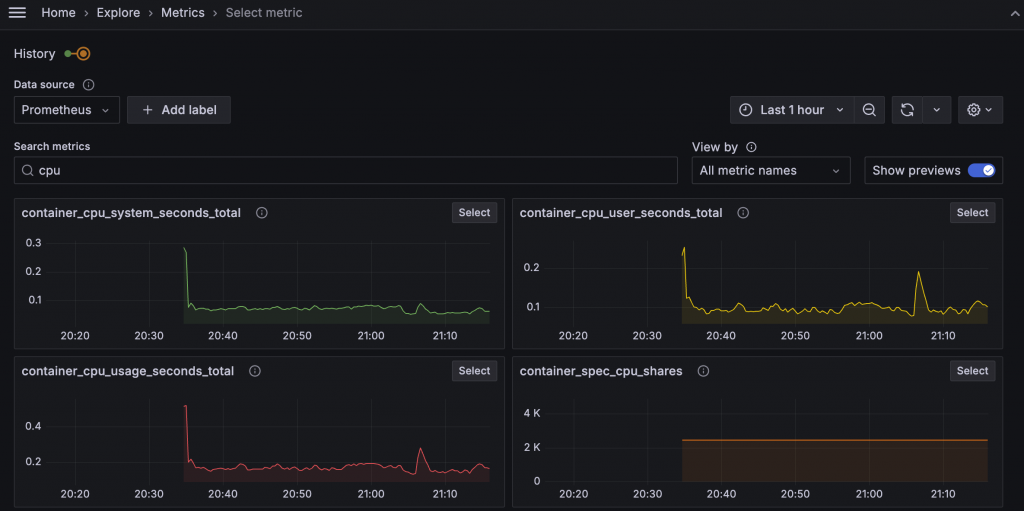
建立新的 Metrics Exploration,輸入文字篩選 Prometheus 指標,部分匹配的結果將會顯示下方。
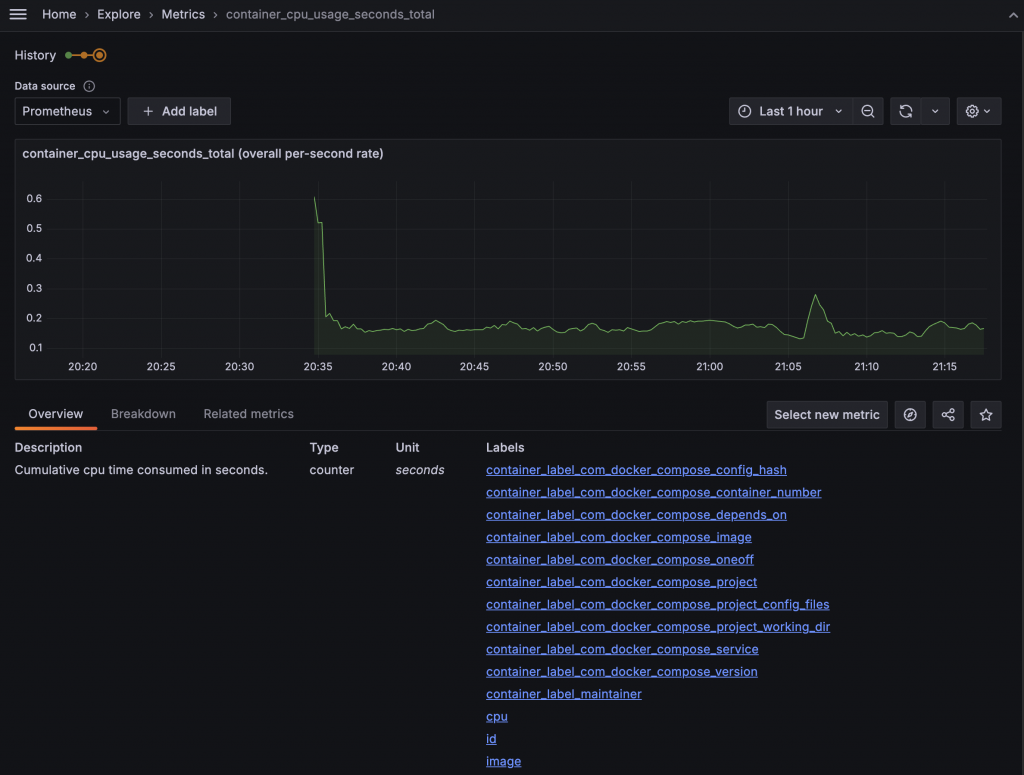
選擇後,顯示可查詢的 Label。
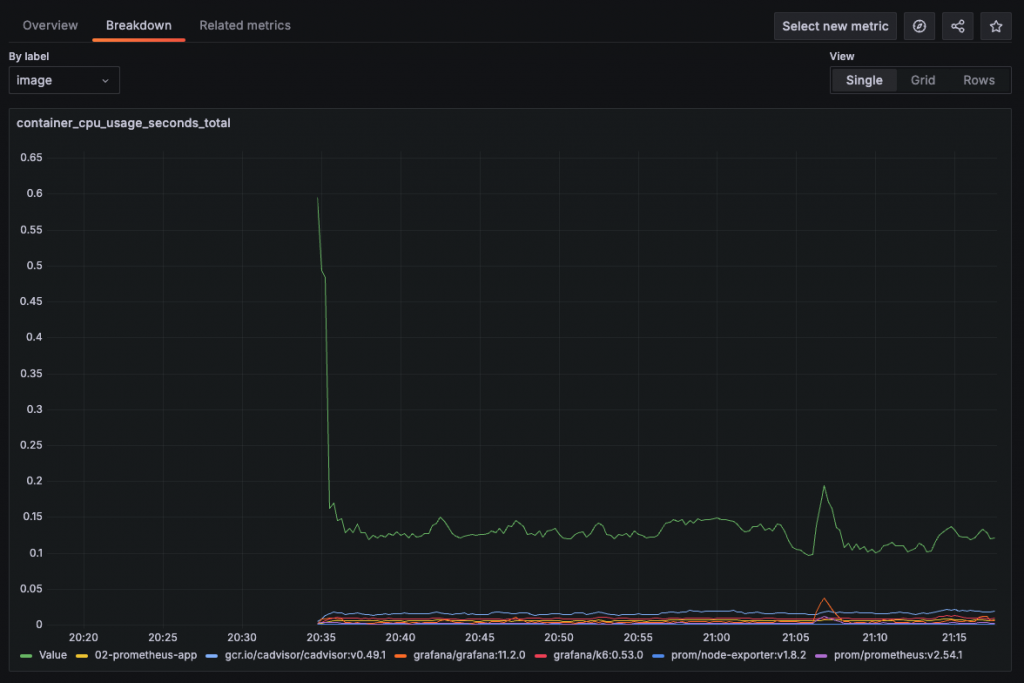
點擊 Label 後進入 Breakdown 頁籤,並將選擇的 Label 作為 Legend 顯示。呈現方式可以選擇單一圖表(Single)或分開繪製(Grid)。
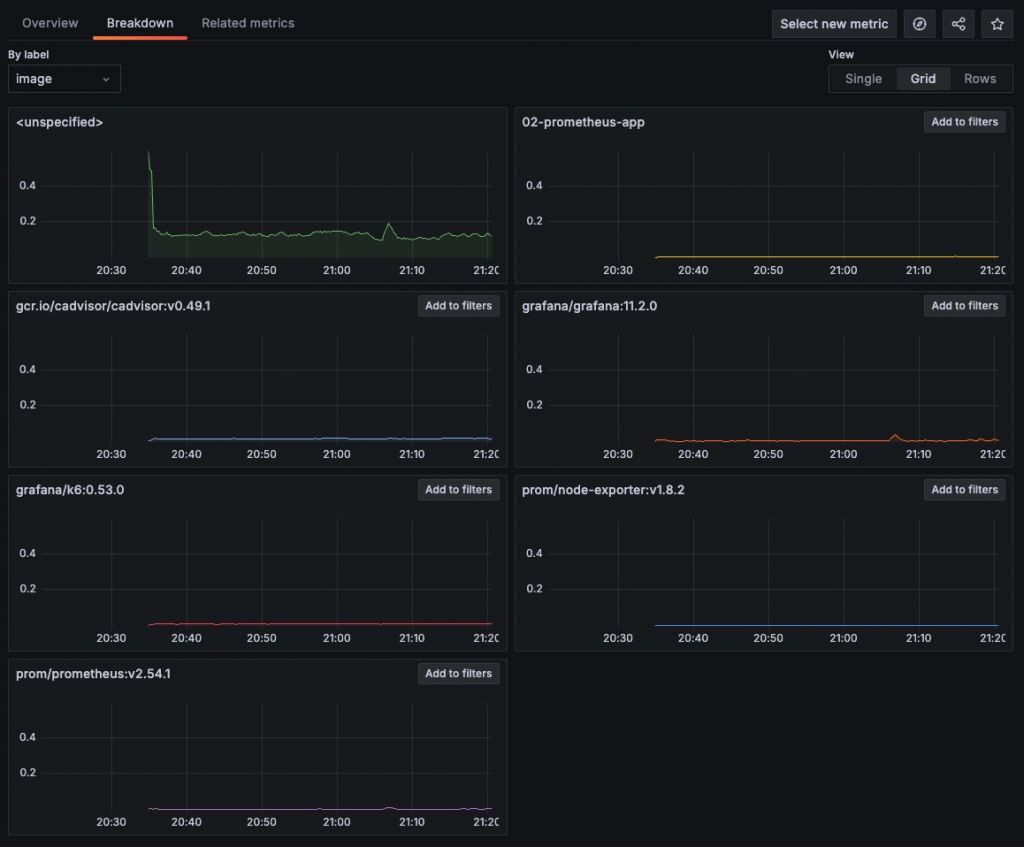
Grafana 可以將 Prometheus Metrics 的查詢結果顯示為 Time series 或 Table,時間序列圖更適合觀察趨勢,而表格則能清楚顯示每個 Label 與其值。
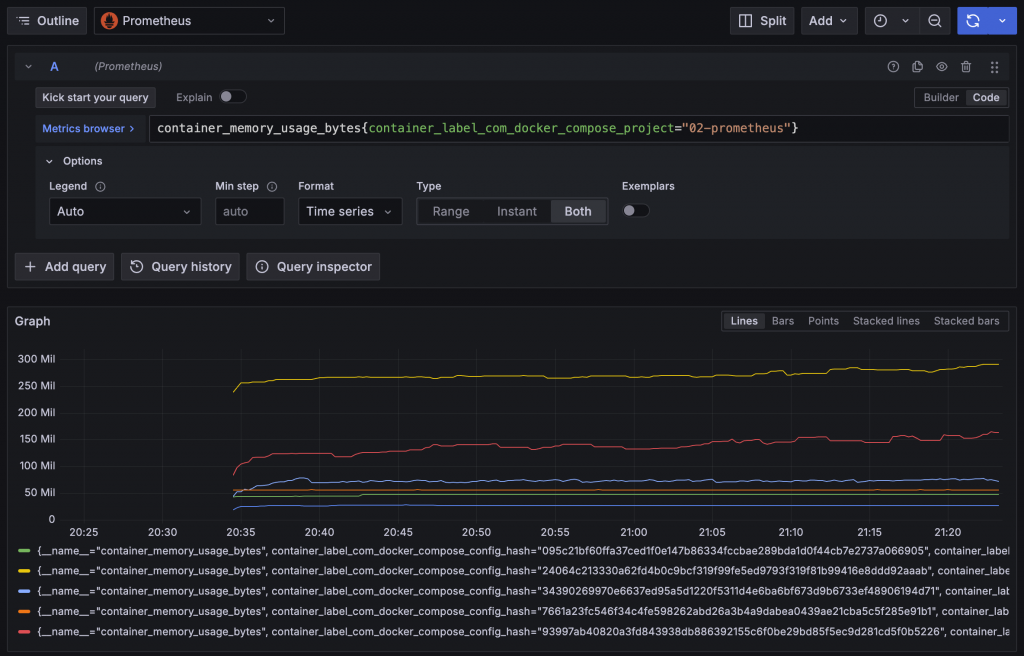
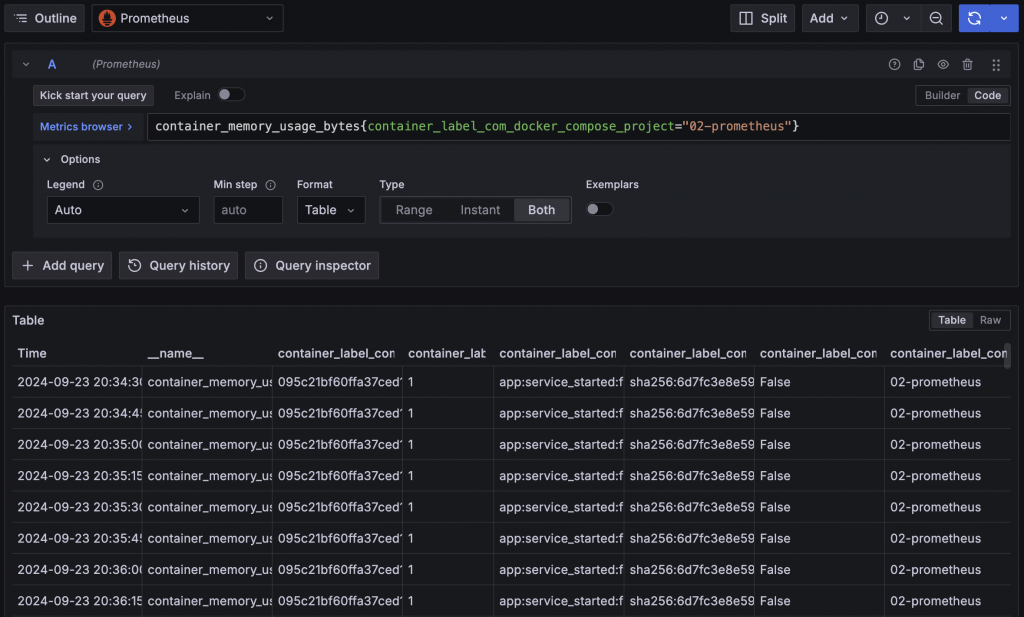
在執行 PromQL 查詢 Prometheus Metrics 在時,可以選擇要查詢指定區間 Range 或是者是指查詢當下的值 Instant,如果只查詢 Instant 能夠更快取得結果。在 Dashboard 或 Explore 中選擇的時間區間會作為 Range 的範圍,而查詢 Instant 時則會取得時間區間的結束點資料。
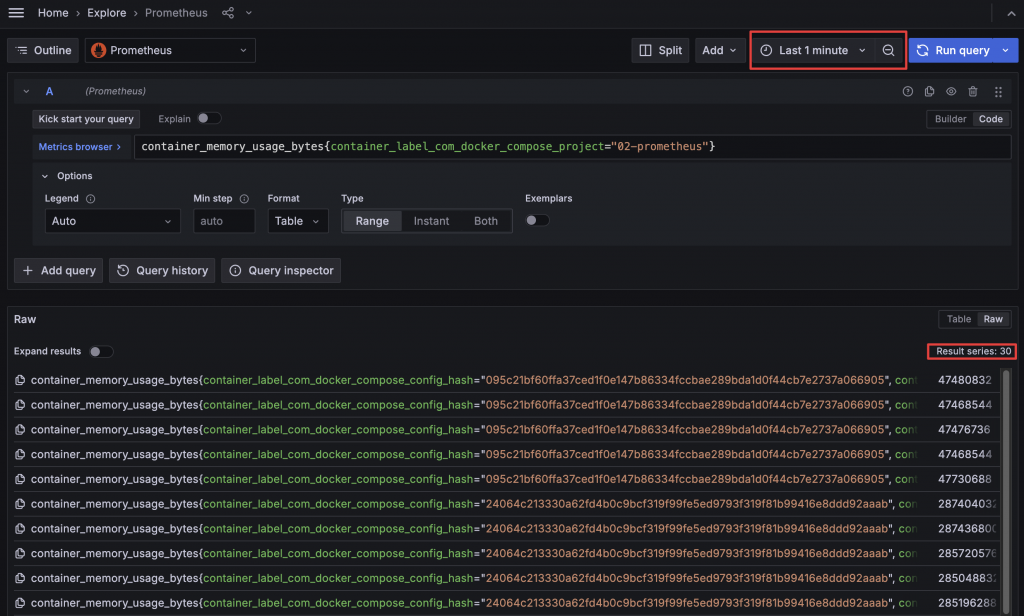
查詢範圍
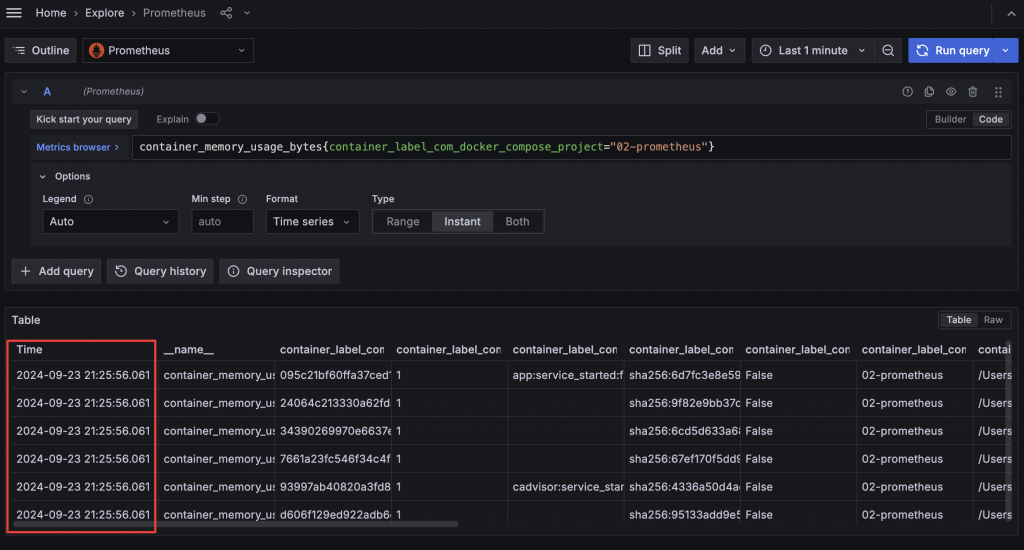
查詢當下值
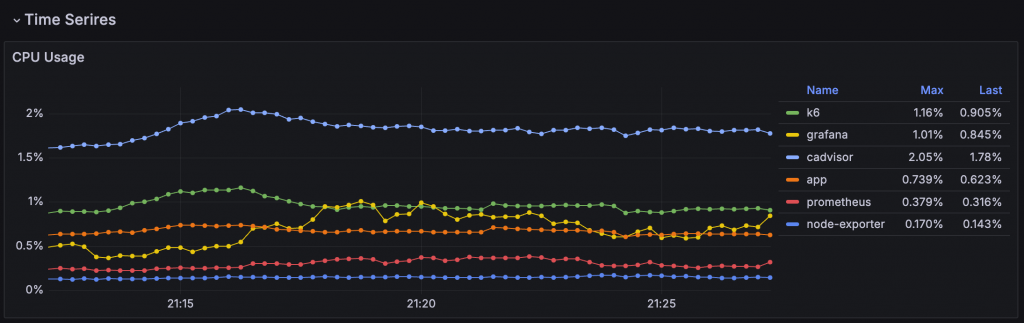
適合用來展示如 CPU 使用率、Queue Size 等資源的使用情況,利用 Time Series 的折線圖可以發現趨勢、異常或指標間的關聯性。
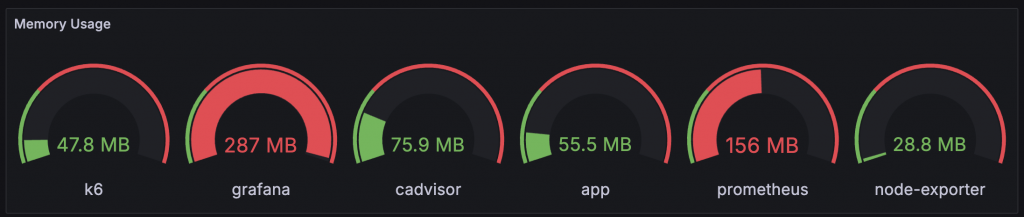
能直接顯示當下的值,並搭配 Threshold 進行快速判斷是否在合理範圍內。
Stat 如果只顯示當下值的話其實效果和 Gauge 差不多,所以通常會搭配趨勢圖使用。但因為 Grafana 對 Prometheus 發送的 PromQL 會有特別的調整,當加大時間區間時,最後一個資料點不一定會取得時間序列中最新的一筆,所以有時候會發現預期應該要相同的累計值如 Request Count 卻會變小。如果要解決這個問題,Type 可以選擇查詢 Both 同時取得 Range 與 Instant 的結果,並透過 Transform 將資料合併與排序,這樣就可以保證會有一筆最新的時,也有時間序列資料可以繪製出趨勢圖。
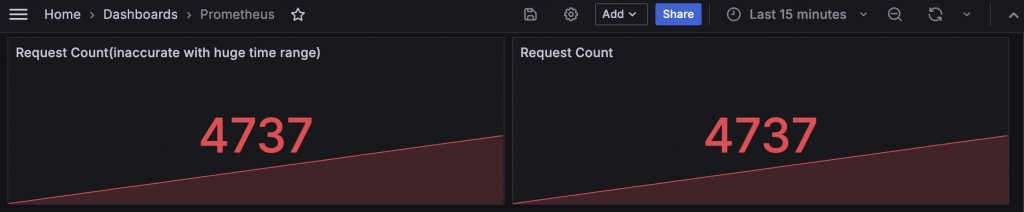
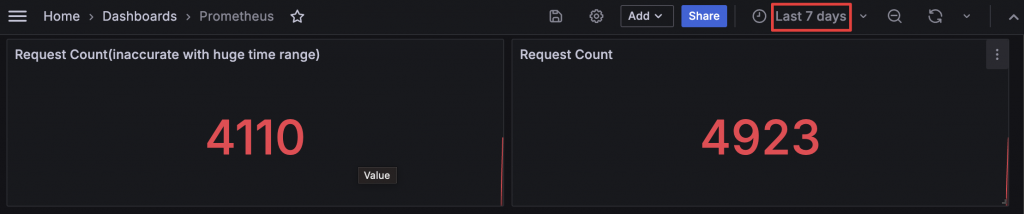
前一張圖在查詢區間小時左右相同,但當查詢區間大時左邊只使用 Range 的資料則不回符合預期
在查詢設定中 Format 選擇 Table 後就可以將資料轉換成表格,並搭配只查詢 Instant 取得最新的資訊,使用 Table Visualization 就能夠清楚看到各個 Label 的資訊與指標值。如果覺得無用的 Label 很多或是對 Label 名稱不滿意,可以再搭配 Transform Organize fields by name 調整。
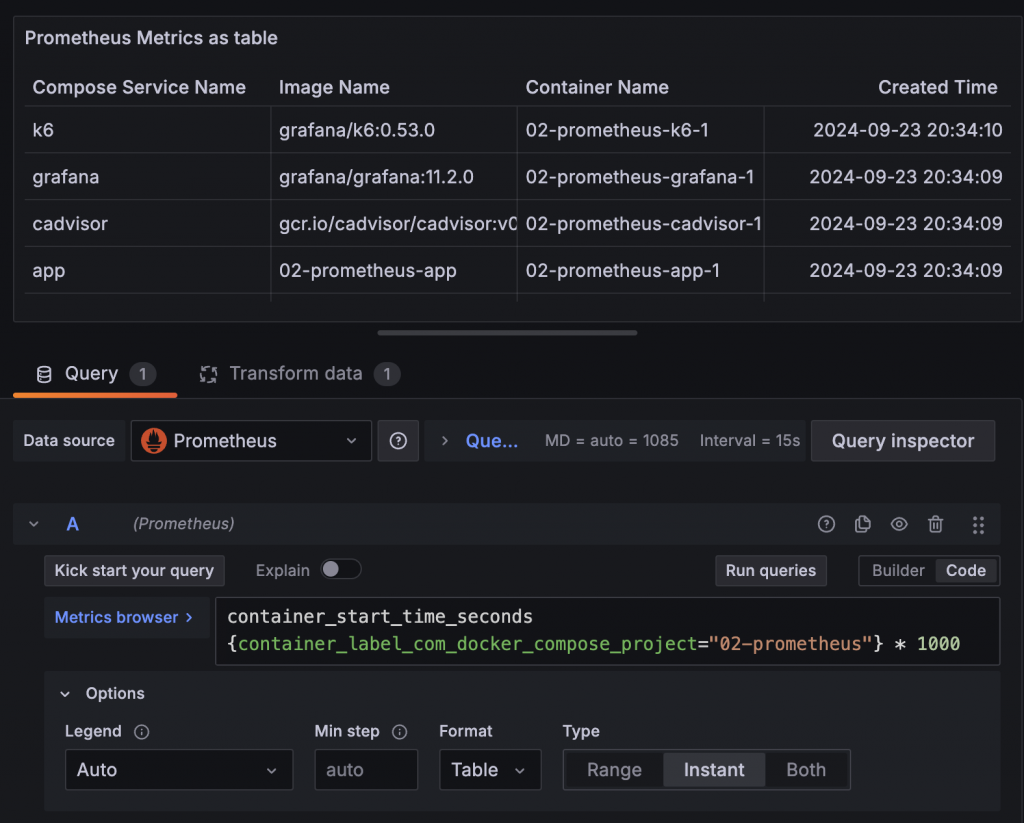
但如果覺得 Label 數量實在太多,使用 Organize fields by name 也還是不易修改,可以考慮使用 Prometheus group、sum、count 這類 Aggregation operators,他們在計算時能夠設定 by 根據選定的 Label 將資料聚合,計算出來的結果就只會有選定的 Label。
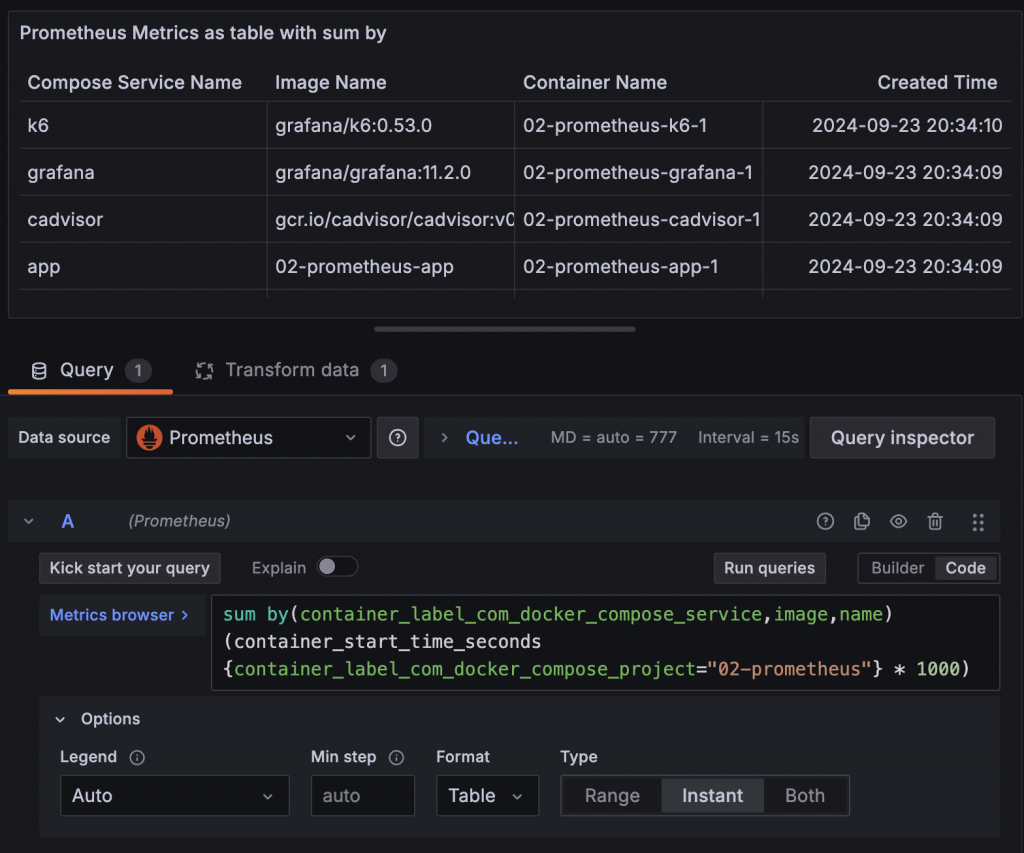
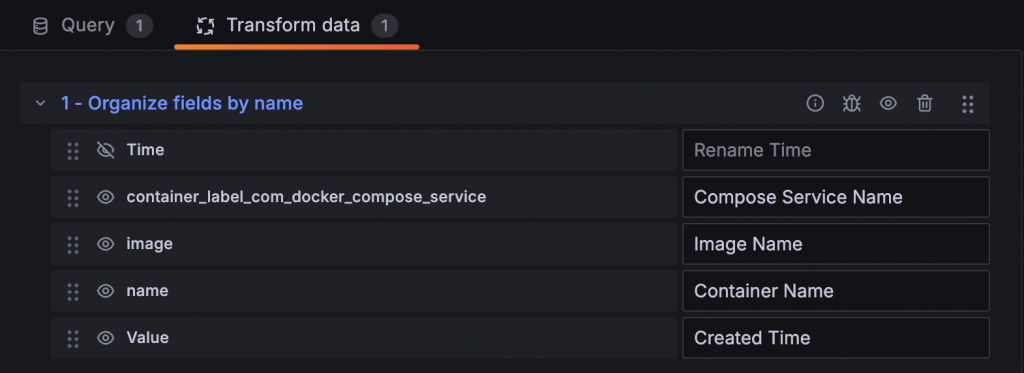
Sum by 後的 Table 就只剩下選定的 Label
使用 Transform Join by field 可以將兩個有相同 Label 的 Prometheus Metrics 合併成一個 Table。
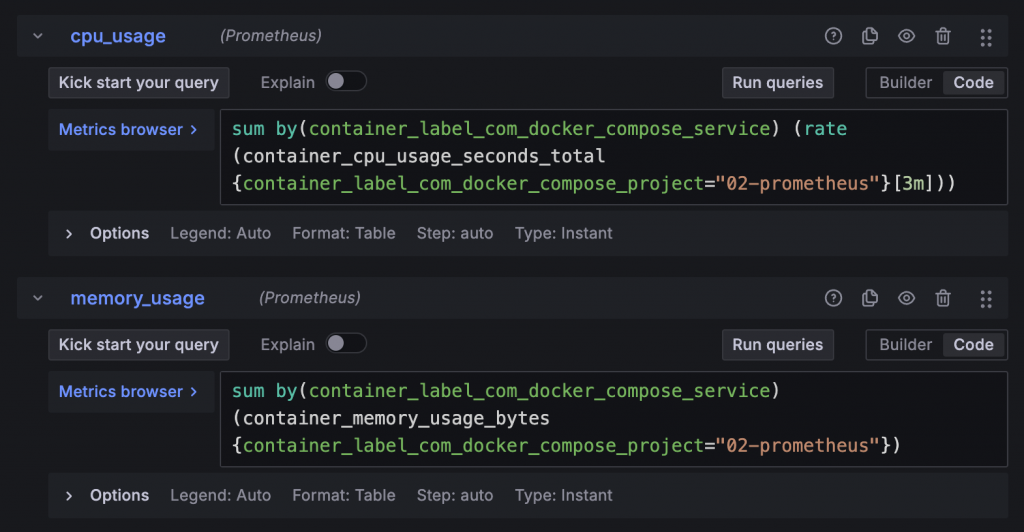
先將 Label 縮減
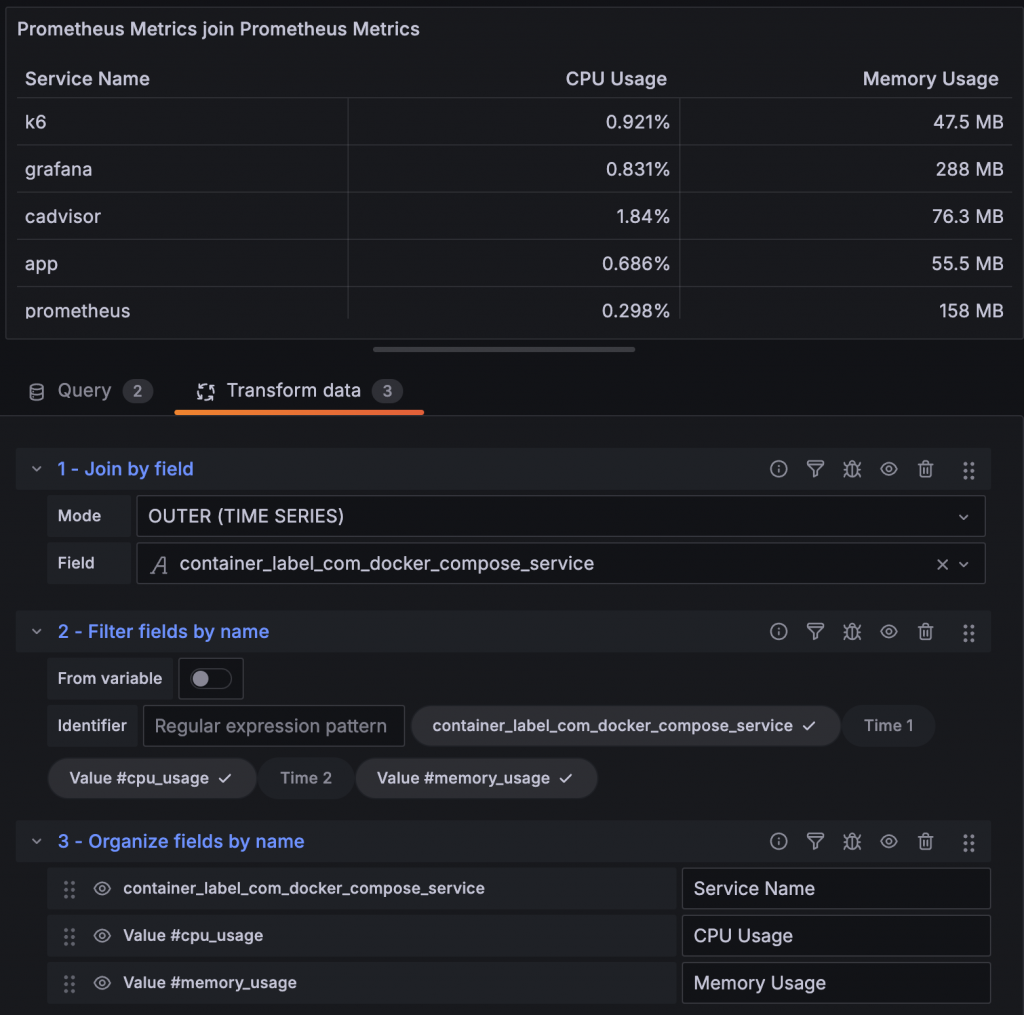
再用 Join by field 合併
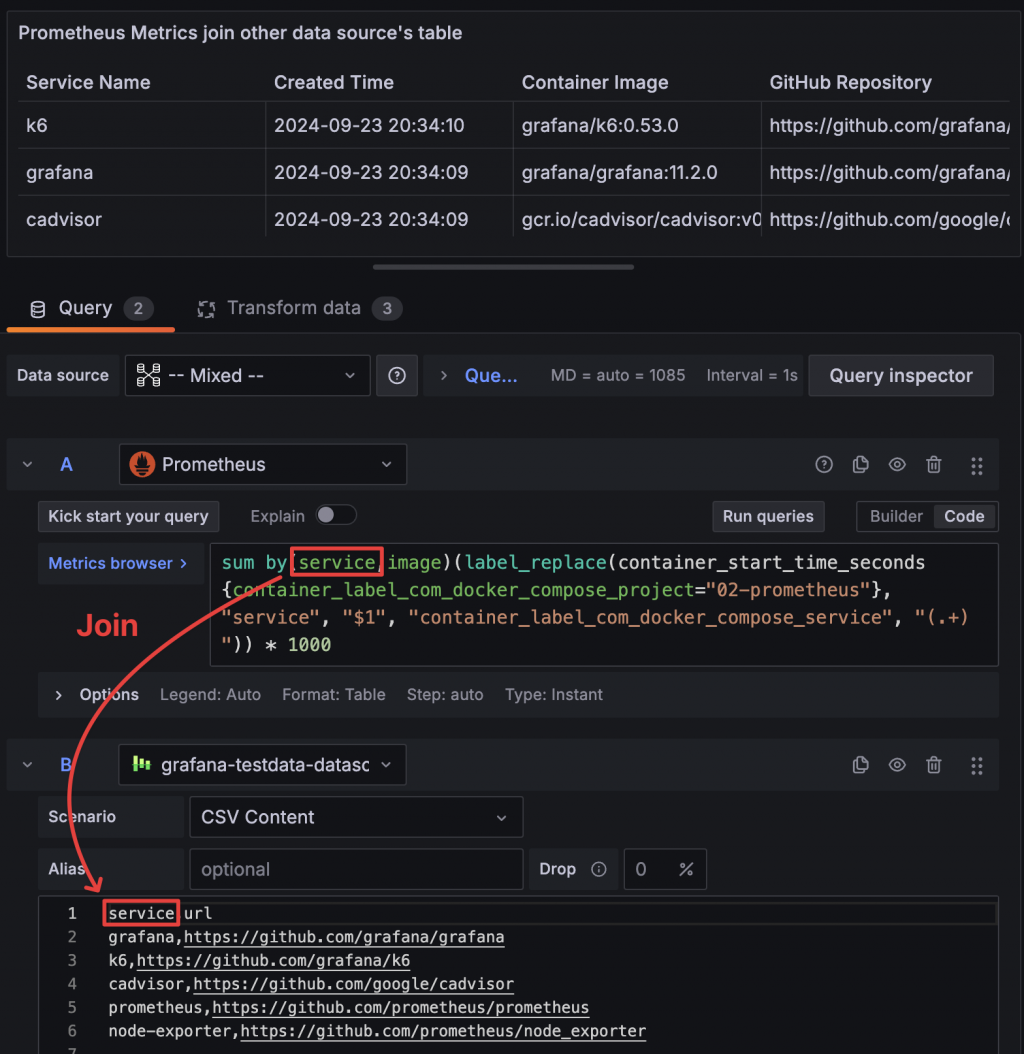
雖然 Join by field 很萬用,但能使用的前提是兩個欄位名稱或 Label 名稱必須要相同。Prometheus Metrics 的 label_replace 能夠複製選定的舊有 Label 值並給予新的 Label Name,透過這個功能我們就能夠預先將預期要配對的 Label 轉換成我們需要的名稱。
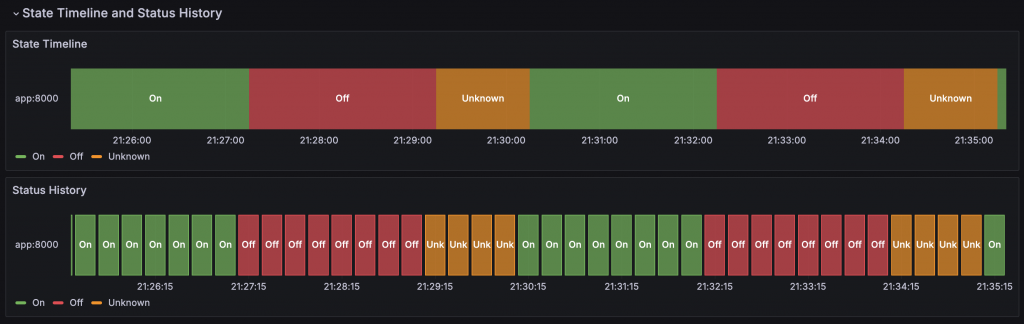
Prometheus Metrics 除了用數值來表達狀態外,將狀態的列舉文字放在 Label 中也是一種常見的做法,這些列舉的文字可以搭配 Filter fields by name、Grouping to Matrix 與 Convert field type 轉換,再透過 State Timeline 與 Status History 來呈現,直接觀察到狀態變化的時間點。
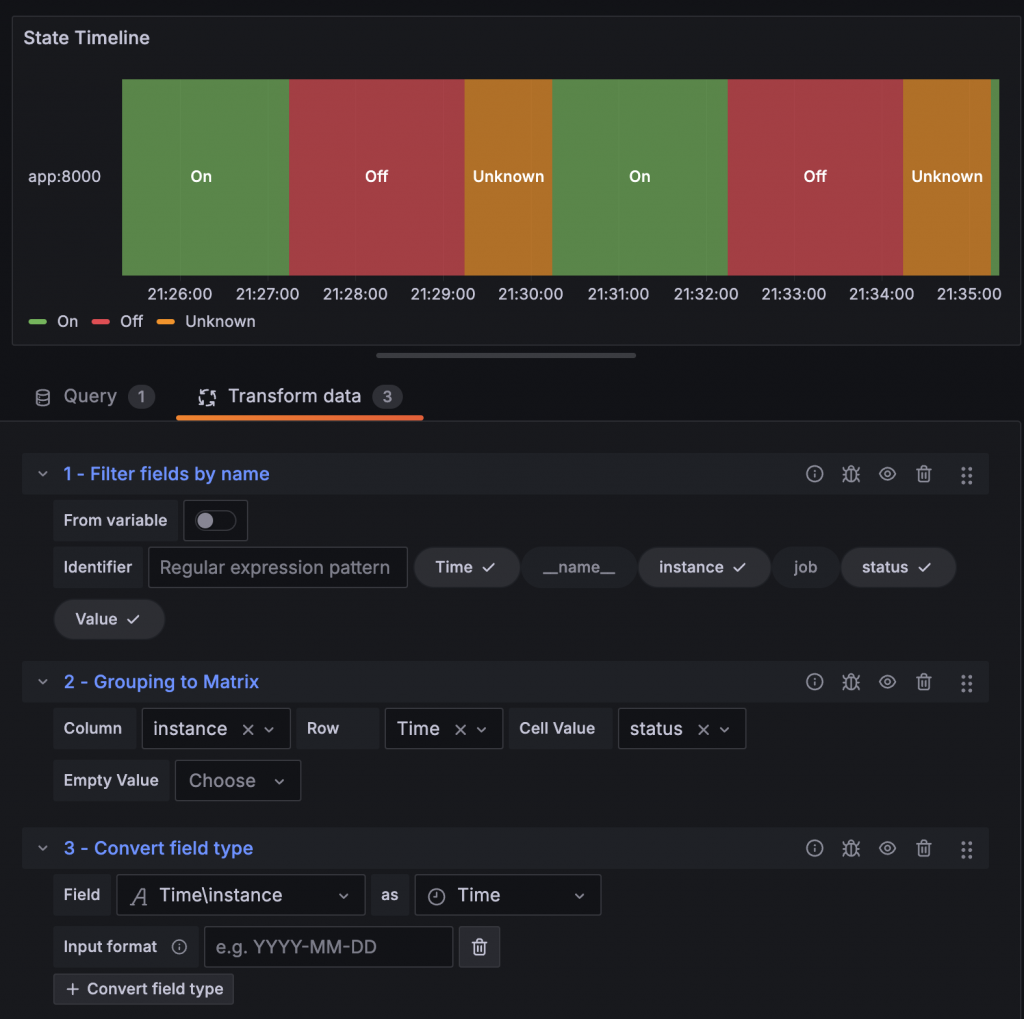
範例程式碼:https://github.com/blueswen/grafana-zero-to-hero/tree/main/04-datasource/02-prometheus
此 Lab 會建立
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
關閉所有服務
docker-compose down

