
今天會帶大家一步一步解析本賽題第一名🥇的思路🤩,在過程中可以學到如何使用 LLM 生成 high quality 的假資料,並用 Meta pseudo labeling 的技巧來擴增訓練資料集。最後再結合文本與數值類型的資料,利用多模態模型訓練的策略拔得頭籌!✨✨
昨天我們帶大家嘗試用LGBM根據我們挖掘出的 feature ,學習預測學生的 content 與 wording 分數。這個 LGBM baseline 在 Private Score 上得到 0.53956 分,排在 Leaderboard 的大概 50% 的地方。沒想到在這個動不動就上語言模型的時代,LGBM的表現沒有想像中來得差嘛~
❓❓如果是你,在嘗試完 LGBM baseline 之後,下一步你會從哪個方向著手改進呢❓❓
沒錯,前面提到在這個萬物皆靠語言模型的時代,我們應該也會好奇這次賽題如果上語言模型會有什麼樣的效果。
跟上一個賽題一樣,大家普遍都以 Debertav3 作為他們的首選。
首先我們可能會想直接嘗試把學生寫的摘要text 當作 input,然後訓練兩個Debertav3模型,一個學習預測 content score,另外一個學習預測 wording score (完整代碼可以參考 1)。這個方法在 LB 上得到0.53450分,只比 LGBM 的方法好 0.5% 而已。
由於我們前面做的 EDA 已經發現,原題幹(包含原文以及要求學生回答的問題等)和摘要的相似度也是一個重要的 feature,所以接下來我們可以嘗試輸入 prompt 相關的 feture 到 Debertav3 一起訓練(完整代碼可以參考2)。
模型架構圖說明如下(圖片來源2):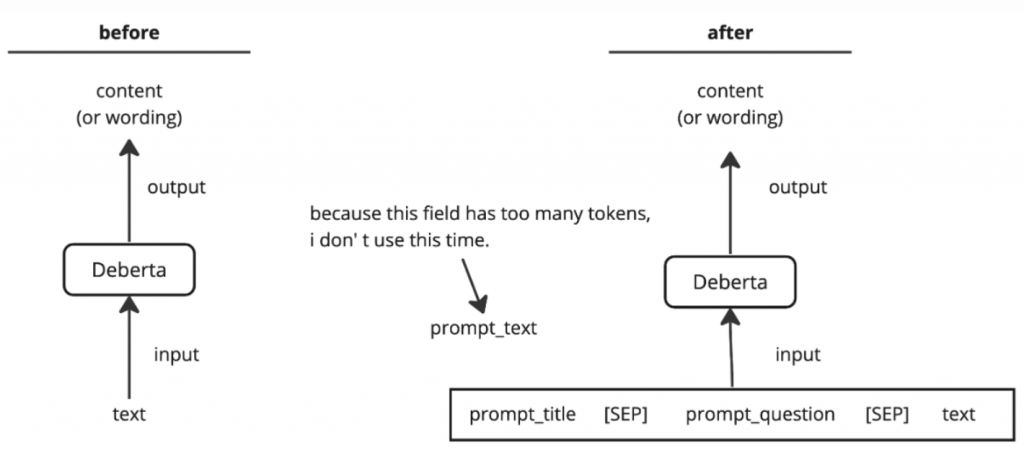
(由於 prompt_text 也就是原文的字數過多,會超過 512 個字,所以這邊先只放 prompt_text 和 prompt_title 等字數較短的資訊。)
這個方法在 LB 上得到0.52971分,這次效果就比較明顯了,相較 LGBM,LB分數下降了 1% 左右,自然也比只輸入 text 到 Debertav3 還要好。
在此,我們先整理一下現在有的實驗數據:(LB 分數要越低越好)
| Method | LB | Improvement |
|---|---|---|
| LGBM Baseline | 0.53956 | 0% |
Debertav3 w/ text |
0.53450 | 0.9% |
Debertav3 w/ text & prompt title & prompt question |
0.52971 | 1.8% |
到這邊如果照著 notebook 在本地做交叉驗證(Cross-Validation)的話,會發現 content_rmse 和 wording_rmse 的數值相比,明顯 wording_rmse 的數值較差,通過改善這個拖後腿的有望提升整體分數。而 wording 又是跟用字遣詞相關的評分標準有關係,也就是評估用字的專業性、豐富性等等的水平,感覺上似乎和我們前面人工挖掘文本特徵如:n_gram overlap, spell check 看是否有錯別字等特徵有關係。
因此接下來我們可以檢查看看,是否可以通過結合語言模型Debertav3與 NLP 相關的特徵來提升 wording 分數的準確性,進而提升整體表現。
但問題來了,要怎麼把 prompt_title, prompt_question, text 等文字訊息,結合相似度、重疊率這些數值特徵(numerical feature)一起送到 deberta 呀?deberta 在 pretrained 的時候,可都是用文本資料來訓練,沒有人在輸入這些數值資料的呀 🤔 ?
那如果我們結合 deberta 處理文本資料的能力,以及 LGBM 處理數值型資料的能力呢?
好主意!也許你心中會想到兩種結合的方式:
deberta 先訓練它根據輸入文本資料預測 content 與 wording 的分數。訓練好之後,取得 deberta 最後一層的 output 當作文本資料的 representation,再將這個 representation 結合其他數值資料送入 LGBM 再次訓練 LGBM 預測 content, wording 的數值,並以 LGBM 的輸出當作最終結果。deberta 先訓練它根據輸入文本資料預測 content 與 wording 的分數。但是訓練好之後,取出 deberta 預測的分數,把這些預測的分數當作一種 feature,連同其他數值型 feature 一起當作 LGBM 的輸入,訓練 LGBM 預測分數,並以 LGBM 的輸出當作最終結果。這兩種方法都可以,只是第一種方法會因為 deberta 的 last hidden representation 的維度有 768 個 dimension,使得 input feature 變成一大串,資料操作上有點不方便,所以這邊我們採用第二種做法(完整代碼請參考3)。
下面是模型架構說明圖(圖片擷取自3):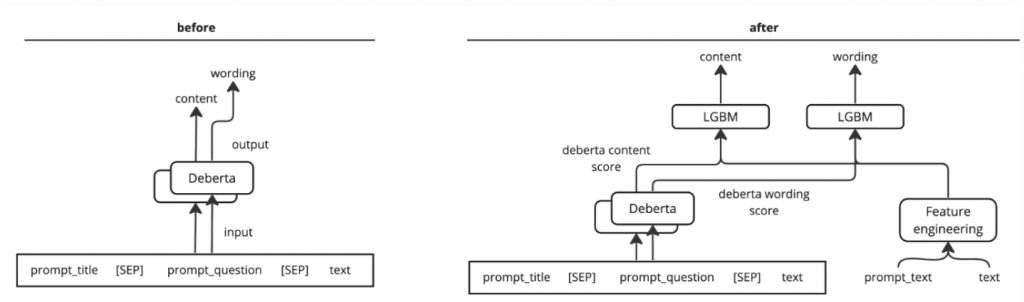
我們使用以下這些數值型特徵:
我們剛剛有提到 deberta 在 pre-trained 的時候都是用文本類型的資料,而且大多是 correct 、拼寫正確的文本資料。如果用帶有錯別字的句子進行學習或輸入,Deberta 可能無法正確理解其含義。
但握回到我們的賽題,如果我是評分者(人類),在發現錯別字時,我會針對錯別字進行扣分。接著,我會默認修正錯別字,再對文章中的其他方面進行評分。如果評分過程是按這樣的邏輯進行,那麼,通過計算錯別字並修正後再輸入到 Deberta,Deberta 可能就能更準確地抓住除了錯別字之外的特徵。
所以我們下一步的策略是,先矯正學生摘要作文裡的錯別字,把沒有錯別字的文本輸入到 Deberta,一方面是為了對齊(alignment)deberta在預訓練時的資料,一方面也是希望 deberta 不要配錯字影響,專注在整體文章的架構與邏輯等比較抽象、卻也正是語言模型擅長捕捉的方面;至於剩下那些錯字率等等特徵,我們就一樣手動計算之後,交給 LGBM 去處理。
所以這一個版本的模型架構如下(圖片取自4,完整代碼可以參考4):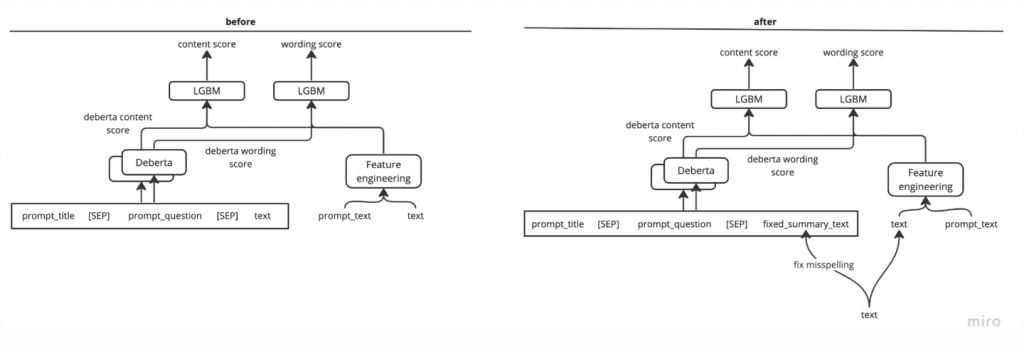
這次,我將確認在補正錯別字後再輸入到 Deberta,能否通過盡可能將錯別字和其他特徵分開來進行模型評價,從而提高分數。
這次的效果更好了,LB 分數來到 0.48865 分!
一樣,我們整理一下目前做過的實驗及其結果,幫助我們制定下一步優化方向:
| Method | LB | Improvement |
|---|---|---|
| LGBM Baseline | 0.53956 | 0% |
Debertav3 w/ text |
0.53450 | 0.9% |
Debertav3 w/ text & prompt title & prompt question |
0.52971 | 1.8% |
| Debertav3 + LGBM w/o spell auto correct | 0.49594 | 8.1% |
| Debertav3 + LGBM w/ spell auto correct | 0.48865 | 9.4% |
有意思的事情是,你會發現我們目前輸入 deberta 的內容都只有prompt title & prompt question 和 text,如果我們改成輸入 prompt_text(也就是原文)和 text 是不是應該效果更好? 因為 deberta 可以直接讀取學生寫的摘要內容和他的原文並進行比較。
可是結果發現: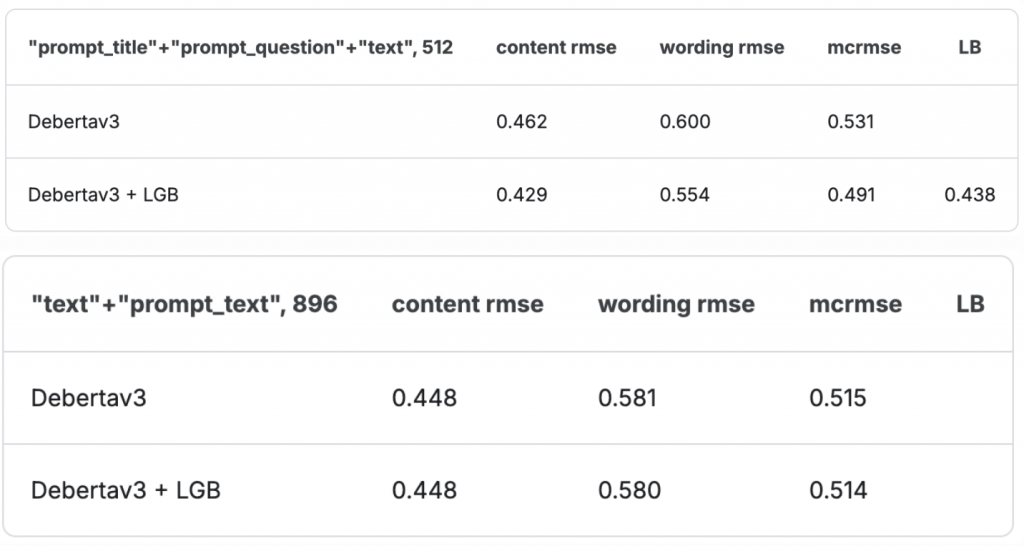
如果我們只靠訓練 deberta 來預測最後的分數,確實改成輸入原文和摘要,mcrmse 會降低;但如果同時結合 LGBM 的話,這樣做反而效果變差(mcrmse 從 0.491 上升到 0.514)。
我認為一個比較合理的解釋是,我們輸入給 LGBM 的很多 feature 都是透過比對 text(摘要)以及 prompt_text(原文)得來的,例如:N-grams Co-occurrence, Quotes Overlap 等等,所以原本的輸入配置會讓 deberta 能看到 prompt_title, prompt_question 等 LGBM 那些 feature 不會考慮到的東西,兩個可以互相結合;但後來改成 text, prompt_text 代表 deberta 和 LGBM 看到的資訊會有重疊,資訊量反而不如原始的輸入配置多了,才導致 mcrmse 上升。
但不管如何,到這邊我們可以很清楚地發現,deberta和LGBM不需要二選一,兩者結合才是YYDS,帶來大幅度的 improvement。
另外我們關於錯字的觀察也是正確的,將輸入 deberta 的文字先糾正一遍,也可以帶來明顯的增益。
第一名也是採用這種將 auto spell correct 過的文字輸入進 deberta 結合 LGBM 的做法呦!(參考5)
透過上面一步一步的觀察和推理,應該就能理解他們為什麼會選擇這樣設計了吧!
但是除此之外,還記得我們在 [Day 6] 介紹賽題的時候有提到:
訓練集只有來自四個題目的摘要練習作文,但是完整的測試集有大量的題目(prompt)!
這代表我們無法取得的測試資料其實是非常多元的、來自不同題目的要求,並且還和訓練資料沒有任何一題重疊,所以我們的 model 要如何從訓練資料 transfer 到測試資料會是很大的挑戰。
因此第一名的 team 他們從提升訓練資料的 quality 和 diversity 著手!
由於訓練數據只包含四個主題,但從經驗來看,訓練學生的寫作能力需要大量不同的作文題目等等來達到。因此,在真實的測試場景中,模型對不同題目的理解是最重要的!
為了讓模型可以 transfer 到不同的題目 prompt 上,第一名5 他們設計利用 LLM 生成許多不同的 prompt_title, prompt_question 與 prompt_text 等等,再利用 LLM 根據剛剛生成的不同 prompt ,模擬不同學生的程度,產生不同程度的學生會寫出來的摘要。
具體流程如下:
生成不同的 prompt: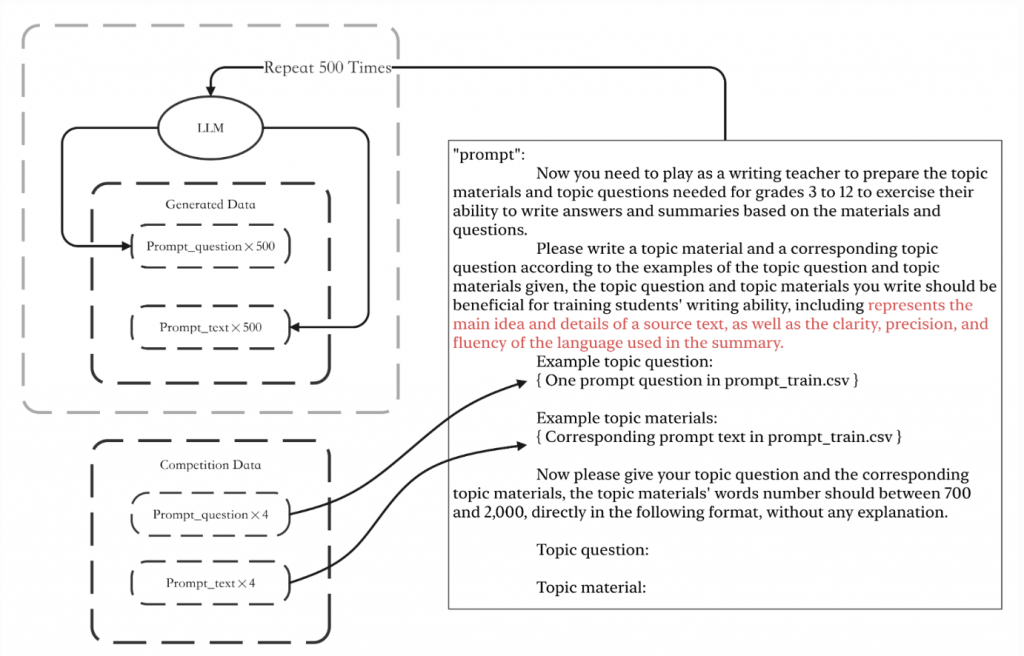
其實就是給 LLM training data 有提到的那四個 prompt 的資訊,然後叫 LLM 仿照類似的格式產生另外 500 個不同的問題(prompt_text 和 prompt_question)。
生成不同程度的學生寫出來的摘要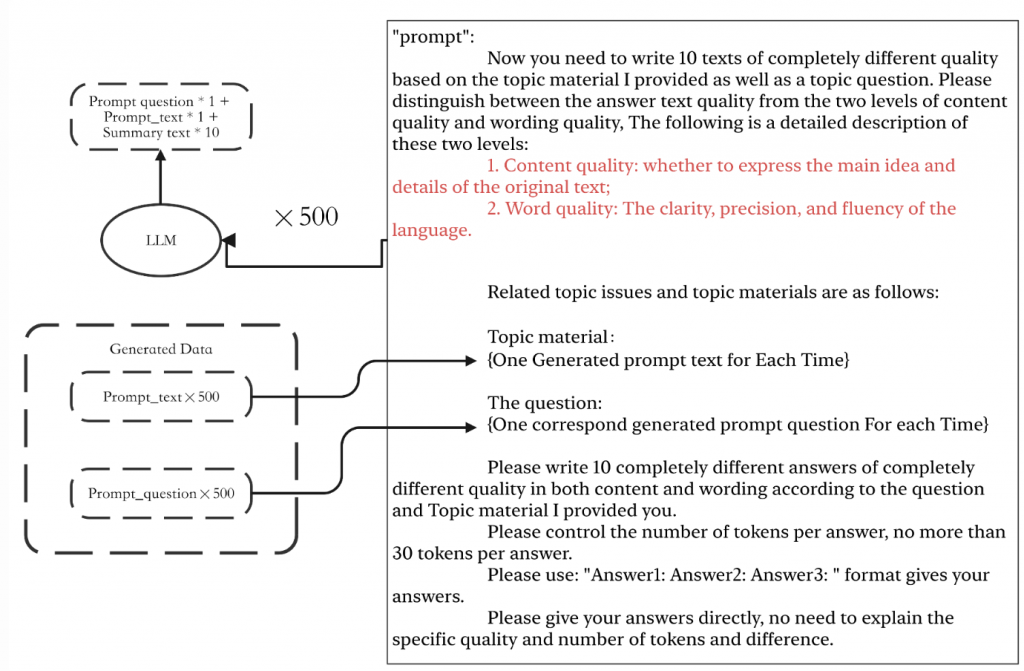
這邊就是給他剛剛生成出來的 prompt_text 與 prompt_question,叫 LLM 根據這些 prompt 的資訊,模擬不同學生的程度,產生10個在 content 與 wording 上面的表現都截然不同的 10 種不同學生的回答。
到這邊,就可以擴增 500 個不同的 prompt 以及 5000 個不同學生寫出來的摘要練習作文。
現在問題來了,要如何為這些 LLM 生成的假摘要打分呢?
因為擴增的這些資料,最終也是要拿去訓練 Deberta 和 LGBM,但是沒有 label(也就是 content 和 wording score) 又該怎麼訓練?
你說叫 LLM 順便打分嗎? 但要是 LLM 打分的標準和人類教師不一樣的話,這樣一起訓練應該會讓效果變更差吧?
為了解決這個問題,作者這邊使用 Meta Pesudo Label 的技巧。
Meta Pseudo Labels 是由 Google 提出的一種半監督學習技術,該方法是在經典的**假標籤(Pseudo Labeling)**技術上進行改進的一種方法,旨在更好地利用未標註數據來提高模型的泛化性能。該技術由 Google 在 2020 年的一篇論文 “Meta Pseudo Labels” 中提出。
(Medium 上有一篇介紹 MPL 的詳細原理,推薦大家看看:Meta Pseudo Label: ImageNet Top1 Accuracy 90% 達成!)
Pseudo Labeling 是一種半監督學習技術,該方法通過訓練一個教師模型來對未標註的數據進行預測,將這些預測的結果作為“假標籤”來引導學生模型的學習。這樣可以使模型充分利用未標註的數據,進一步提高模型的性能。
Meta Pseudo Labels 將這一過程進行了優化,引入了元學習的概念,具體而言,它通過同時訓練一個教師模型(Teacher Model)和一個學生模型(Student Model),並且使用學生模型的性能來調整教師模型的參數。
整體的流程如下圖(左邊是 pseudo-label, 右邊是 meta pseudo-label 的流程):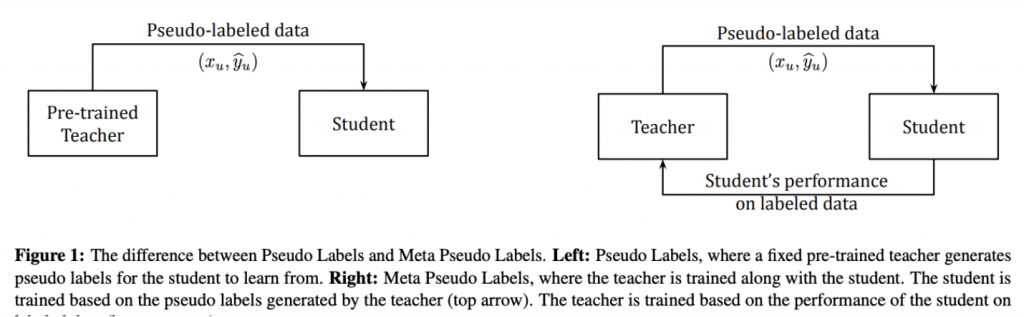
🤔 也許你會想問,為什麼樣這樣做?為什麼要設計根據學生的反饋來改變教師模型? 通常教師模型都是先train在一個由人類標注好的資料及,也就是ground truth 上,那又為什麼還要被不成熟的學生模型影響呢?
傳統的 Pseudo Labeling 方法確實像你所提到的那樣,教師模型通常會先在由人類標註的數據(也就是 ground truth)上進行訓練。訓練好的教師模型接著用來預測未標註數據的「假標籤」(pseudo labels),這些假標籤再被用來訓練學生模型。整個過程中,教師模型一旦訓練完成,它的權重通常就不再改變。
但是,這裡有一個潛在的問題:
教師模型生成的假標籤可能不夠準確:即使教師模型在標註數據上訓練表現得很好,但當它應用到未標註數據時(例如我們這邊用訓練好的 deberta+LGBM 在 LLM 新生成的摘要 text 上做標註),生成的假標籤可能並不總是準確的(由於這個模型沒看過這些根據新的題目寫的摘要)。這些不準確的假標籤會導致學生模型在訓練過程中學到錯誤的知識,甚至可能使學生模型表現變差。
所以我們需要有一種方式,可以改善這個教師模型在這些未標注的數據上所犯的錯誤。但就因為這些資料沒有被標註,我們就沒有相對應的回饋,可以用來改善這個教師模型了呀!
這時候,meta pseudo labeling 的教師和學生模型互相訓練的想法就誕生了--透過學生模型的反饋來改善教師模型,也就是說,如果學生表現得很差,那是不是代表老師教得很爛,老師也要檢討呢?
如果學生用教師模型標的那些假資料學習之後,在那些已標注的數據上測試的表現很差,那是不是代表老師標的那些假資料根本就有問題!老師自己趕快修正一下吧~
MPL大概的構想就是上面那樣,但因為第一名沒有給他們的 training code,我這邊自己根據他們的 write-up ,還原一下使用 MLP 幫 LLM 生成的假資料打標籤的做法:(他們生成的假資料可以參考6)
import torch
from transformers import DebertaTokenizer, DebertaForSequenceClassification
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score
from datasets import Dataset
# 定義超參數
BATCH_SIZE = 16
EPOCHS = 3
LEARNING_RATE = 1e-5
PSEUDO_LABEL_THRESHOLD = 0.8
# 加載DeBERTa模型和分詞器
tokenizer = DebertaTokenizer.from_pretrained('microsoft/deberta-base')
teacher_model = DebertaForSequenceClassification.from_pretrained('microsoft/deberta-base', num_labels=2)
student_model = DebertaForSequenceClassification.from_pretrained('microsoft/deberta-base', num_labels=2)
# 準備優化器
optimizer = torch.optim.AdamW(student_model.parameters(), lr=LEARNING_RATE)
# 模型訓練函數
def train_model(model, dataloader, optimizer):
model.train()
total_loss = 0
for batch in dataloader:
inputs = batch['input_ids'].to('cuda')
labels = batch['labels'].to('cuda')
outputs = model(inputs, labels=labels)
loss = outputs.loss
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
return total_loss / len(dataloader)
# 評估函數
def evaluate_model(model, dataloader):
model.eval()
predictions, true_labels = [], []
with torch.no_grad():
for batch in dataloader:
inputs = batch['input_ids'].to('cuda')
labels = batch['labels'].to('cuda')
outputs = model(inputs)
preds = torch.argmax(outputs.logits, dim=-1).cpu().numpy()
predictions.extend(preds)
true_labels.extend(labels.cpu().numpy())
return accuracy_score(true_labels, predictions)
# 創建DataLoader
def create_dataloader(dataset, tokenizer, batch_size):
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True, return_tensors="pt")
dataset = dataset.map(tokenize, batched=True)
dataset.set_format(type='torch', columns=['input_ids', 'labels'])
return DataLoader(dataset, batch_size=batch_size)
# Pseudo-labeling 函數
def generate_pseudo_labels(model, dataloader, threshold=PSEUDO_LABEL_THRESHOLD):
model.eval()
pseudo_labels = []
with torch.no_grad():
for batch in dataloader:
inputs = batch['input_ids'].to('cuda')
outputs = model(inputs)
probs = torch.softmax(outputs.logits, dim=-1)
conf, preds = torch.max(probs, dim=-1)
# 只選擇超過信心門檻的 pseudo-labels
for i, confidence in enumerate(conf):
if confidence > threshold:
pseudo_labels.append((batch['text'][i], preds[i].item()))
return pseudo_labels
# 加載你的數據集
labeled_data = Dataset.from_dict({'text': ["your labeled text"], 'labels': [0 or 1]})
unlabeled_data = Dataset.from_dict({'text': ["LLM generated text"]})
# DataLoader
labeled_dataloader = create_dataloader(labeled_data, tokenizer, BATCH_SIZE)
unlabeled_dataloader = create_dataloader(unlabeled_data, tokenizer, BATCH_SIZE)
# MPL 主流程
for iteration in range(3):
print(f"Iteration {iteration + 1}/3")
# 1. 教師模型為未標記數據生成 pseudo-labels
pseudo_labels = generate_pseudo_labels(teacher_model, unlabeled_dataloader)
pseudo_dataset = Dataset.from_dict({'text': [text for text, label in pseudo_labels], 'labels': [label for text, label in pseudo_labels]})
pseudo_dataloader = create_dataloader(pseudo_dataset, tokenizer, BATCH_SIZE)
# 2. 學生模型在 pseudo-labeled 數據上進行訓練
pseudo_loss = train_model(student_model, pseudo_dataloader, optimizer)
print(f"Student Model Training Loss: {pseudo_loss}")
# 3. 在標註數據集上評估學生模型
accuracy = evaluate_model(student_model, labeled_dataloader)
print(f"Evaluation Accuracy: {accuracy}")
# 4. 根據評估結果更新教師模型權重
teacher_model.load_state_dict(student_model.state_dict())
print("MPL 完成!")
到這邊,第一名的做法就介紹完啦!
他們最耗時的部分是在用 LLM 生成假資料並用 MPL 打上標籤的部分。準備好資料後,他們一樣是丟到 debertaV3 + LGBM 的組合,以 prompt_id 分成 4 個 folds,ensemble 4 個 deberta 模型的輸出。這部分就跟之前介紹的方法差不多了。
明天我們會繼續介紹第二名到第四名的優勝作法,這些得獎組別也都有使用 LLM 擴增資料的技巧,其中第二名的做法又簡潔又優雅!讓我們期待一下吧!
我們明天見~
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - CommonLit - Evaluate Student Summaries 解法分享系列)
