
在現代資料驅動的世界中,可靠的監控和可視化工具是保持系統健康運行的關鍵。Grafana 作為一款成熟的開源資料可視化平台,廣泛應用於各種領域,從 IT 基礎設施到業務指標監控。然而,隨著應用場景的擴大和資料量的增加,確保 Grafana 的高可用性成為了必須考量的議題。本文將深入探討如何在 Kubernetes 環境中配置高可用的 Grafana,並解釋其架構、適用場景及帶來的好處。
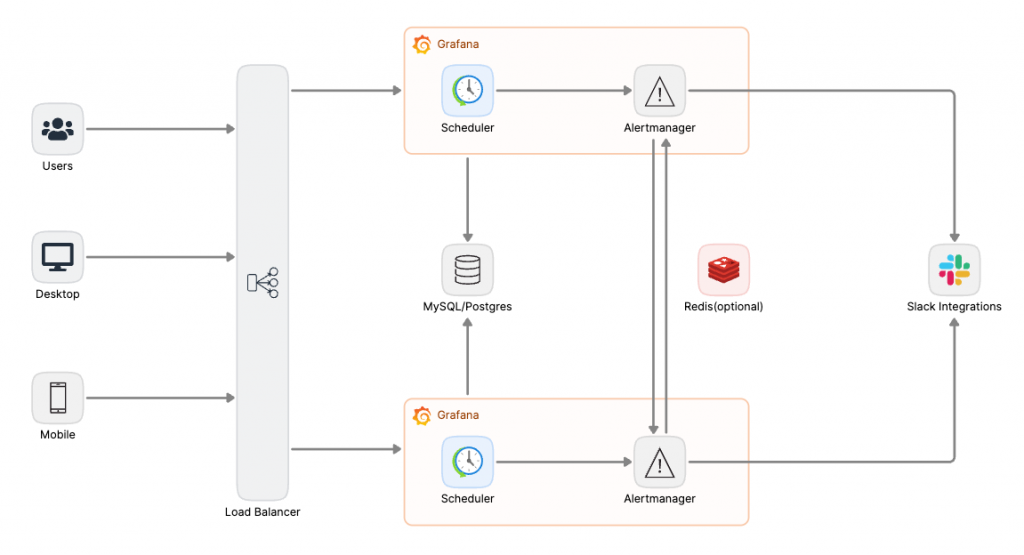
借助 Kubernetes 和容器化技術的彈性特性,在 Kubernetes 中實現高可用的 Grafana 是一個優雅且高效的解決方案。實現這一目標的關鍵在於以下幾個核心要點:
在預設情況下,單體式的 Grafana 使用內建的 SQLite 作為其資料庫。如果僅僅擴展 Grafana 的副本數量,那麼使用者的操作和資料存取將無法在所有副本之間同步,這取決於當前使用者訪問的是哪一個副本。這樣的情況會導致資料不一致的問題,尤其是儀表板設定、使用者偏好等無法統一。
為了解決這個問題,我們必須將資料庫獨立出來,作為所有 Grafana 副本的統一持久層。這可以通過將 SQLite 替換為支持多副本的關聯式資料庫,如 MySQL 或 PostgreSQL。這樣,每個 Grafana 副本都能共享同一個資料來源,保證資料的一致性,並避免因不同副本的使用者操作而導致的錯誤數據。
Grafana 中的 AlertManager 負責處理來自 Grafana 的告警通知和路由。當部署多個 Grafana 副本時,可能會出現每個副本都獨立對告警規則進行評估,並各自發送告警的情況。這種情況下,會導致相同的告警被多次發送,造成重複告警問題。
為了解決這個問題,可以採用幾種策略來確保告警的同步性:
要在 Kubernetes 中實現高可用的 Grafana,以下是關鍵的步驟:
在接下來的實戰中,我們將從頭開始在 Kubernetes 上構建一個具備高可用性的 Grafana 系統。此次實作的重點將集中在兩個核心部分:首先,我們將部署 MySQL,以支援高可用的 Grafana 架構;接著,我們會配置 grafana.ini,確保 Grafana 的高可用性設置正確無誤。最後,我們將設置 Alerting 的高可用性,並說明如何透過 grafana.ini 的關鍵設定來實現這些功能。
以下為一個 standalone 並且配置好預設使用者的簡易設定。
# values.yaml
image:
registry: docker.io
repository: bitnami/mysql
tag: 8.4.2-debian-12-r2
architecture: standalone
auth:
createDatabase: true
database: "grafana"
username: "admin"
password: "admin"
在這裡們將使用 MySQL Helm Chart 11.1.15 版本。
helm upgrade --install mysql oci://registry-1.docker.io/bitnamicharts/mysql -n mysql --version 11.1.15 -f values.yaml
---
Release "mysql" does not exist. Installing it now.
Pulled: registry-1.docker.io/bitnamicharts/mysql:11.1.15
Digest: sha256:9c2a566b01e4ca8cb0b2163710b8e280c5aed6f905381bf86adef8b03a3b4976
NAME: mysql
LAST DEPLOYED: Fri Aug 30 00:00:50 2024
NAMESPACE: mysql
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: mysql
CHART VERSION: 11.1.15
APP VERSION: 8.4.2
以下設定將會替我們設定預設管理者帳號密碼,另外我們在此指定使用外部的 MySQL 作為全局資料庫,並且將 replicas 設定為 3 來驗證。
# values.yaml
adminUser: admin
adminPassword: admin
replicas: 3
grafana.ini:
database:
url: mysql://admin:admin@mysql.mysql:3306/grafana
persistence:
enabled: false
在這裡們將使用 Grafana Helm Chart 8.5.0 版本。
helm upgrade --install grafana grafana/grafana -n grafana --version 8.5.0 -f values.yaml
---
Release "grafana" has been upgraded. Happy Helming!
NAME: grafana
LAST DEPLOYED: Fri Aug 30 00:16:05 2024
NAMESPACE: grafana
STATUS: deployed
REVISION: 24
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.grafana.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace grafana -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace grafana port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
#################################################################################
###### WARNING: Persistence is disabled!!! You will lose your data when #####
###### the Grafana pod is terminated. #####
#################################################################################
查看 Grafana pod 的日誌將會發現相關 MySQL 連接資訊:
logger=sqlstore t=2024-08-29T16:04:32.592991186Z level=info msg="Connecting to DB" dbtype=mysql
logger=migrator t=2024-08-29T16:04:32.594788005Z level=info msg="Locking database"
logger=migrator t=2024-08-29T16:04:32.594948587Z level=info msg="Starting DB migrations"
logger=migrator t=2024-08-29T16:04:32.599670507Z level=info msg="migrations completed" performed=0 skipped=595 duration=280.122µs
logger=migrator t=2024-08-29T16:04:32.600468375Z level=info msg="Unlocking database"
實際連接上後,我們可以看到 Grafana 已經順利將 Migrate 資料到 MySQL:
# values.yaml
adminUser: admin
adminPassword: admin
replicas: 3
headlessService: true
grafana.ini:
database:
url: mysql://admin:admin@mysql.mysql:3306/grafana
unified_alerting:
enabled: true
ha_listen_address: "${POD_IP}:9094"
ha_advertise_address: "${POD_IP}:9094"
ha_peers: grafana-headless.grafana:9094
alerting:
enabled: false
接下來,我們將進一步實現 Grafana Alerting 的高可用性設定,這部分將重點放在以下幾個方面:
helm upgrade --install grafana grafana/grafana -n grafana --version 8.5.0 -f values.yaml
---
Release "grafana" has been upgraded. Happy Helming!
等到更新完成後,沒有意外的話我們將可以在日誌中看到相關 gossip settled 字眼,代表一致性演算法成功運作:
logger=ngalert.multiorg.alertmanager component=clustering t=2024-08-29T16:16:16.821119536Z level=warn received="unknown state key" len=1172 key=silences:1
logger=ngalert.multiorg.alertmanager component=clustering t=2024-08-29T16:16:16.821183159Z level=info msg="Waiting for gossip to settle..." interval=2s
logger=ngalert.multiorg.alertmanager component=clustering t=2024-08-29T16:16:18.842030555Z level=info msg="gossip not settled" polls=0 before=0 now=4 elapsed=2.020786397s
logger=ngalert.multiorg.alertmanager component=clustering t=2024-08-29T16:16:26.844127521Z level=info msg="gossip settled; proceeding" elapsed=10.022909237s
也可以透過 Grafana /metrics 端點中的 alertmanager_cluster 相關指標來判斷,看看 alertmanager_cluster_members 是否等於 Alertmanager Replica 數量:
# HELP alertmanager_cluster_alive_messages_total Total number of received alive messages.
# TYPE alertmanager_cluster_alive_messages_total counter
alertmanager_cluster_alive_messages_total{peer="01J6FGR9FVM9QG7V45MXXNZKBX"} 9
alertmanager_cluster_alive_messages_total{peer="01J6FGR9H02J42NXY617RSDEQ8"} 10
alertmanager_cluster_alive_messages_total{peer="01J6FGRKG2RM1B2T11552A9ZMN"} 9
# HELP alertmanager_cluster_failed_peers Number indicating the current number of failed peers in the cluster.
# TYPE alertmanager_cluster_failed_peers gauge
alertmanager_cluster_failed_peers 0
# HELP alertmanager_cluster_health_score Health score of the cluster. Lower values are better and zero means 'totally healthy'.
# TYPE alertmanager_cluster_health_score gauge
alertmanager_cluster_health_score 0
# HELP alertmanager_cluster_members Number indicating current number of members in cluster.
# TYPE alertmanager_cluster_members gauge
alertmanager_cluster_members 3
到此,我們已經成功實踐了通過一致性演算法,省去對 Redis 服務依賴的負擔了。此舉大大減輕我們維護資料庫的成本!
透過這次的實戰,我們成功在 Kubernetes 環境中部署了一個具備高可用性的 Grafana 系統。從 MySQL 的高可用配置到 Grafana 本體的一致性,再到 Alerting 系統的高可用性設置,我們逐步構建了一個穩定且可靠的監控平台。這些設置不僅確保了資料的一致性,還有效避免了因多副本運行而可能出現的告警重複發送問題。
在實作過程中,我們展示了如何使用 Kubernetes 的彈性特性來達成這些目標,並通過一致性演算法取代了對 Redis 的依賴,從而簡化了系統的維護。這樣的架構設計不僅提升了系統的可靠性,也為企業的資料監控和告警處理提供了更強大的支持。
無論是在日常運營還是面對突發狀況,這套高可用的 Grafana 設置都能確保系統的穩定運行,讓團隊能夠持續進行關鍵資料的監控和分析,從而快速作出正確的業務決策。隨著系統規模的擴展,這樣的高可用架構將成為實務中不可或缺的一部分。

