昨天和前天我們知道了對話決策學習將資料庫查詢的結果整理成狀態,
輸入並預測要回覆的對話行為。
但對話行為為一個[對話意圖、對話領域、槽、槽值]組成的串列,
使用者未必能了解這一坨東西。
那這個時候就需要一個翻譯員,來將對話行為轉換成對話。
而這就是今天我們要介紹的,自然語言生成NLG(Natural Language Generation)
NLG的輸入輸出很單純,輸入對話行為
在LLMs和生成模型百家爭鳴的現在,我們可以使用Prompt加上簡單的例子,
以one-shot做對話的生成。
我們一樣以crossWOZ為範例,來示範如何以LLMs做one-shot的NLG。
首先我們先將DPL輸出的[對話意圖、對話領域、槽、槽值]串列轉換成字串,程式碼為以下:
for da_type in turn['dialogue_acts']: # 若一句話有多個對話行為
for da in turn['dialogue_acts'][da_type]: # 依據取得意圖、領域、槽及槽值
intent, domain, slot, value = da.get('intent'), da.get('domain'), da.get('slot', ''), da.get('value', '')
das.append((intent, domain, slot, value))
example += '<DA>'+json.dumps(das)+'</DA>'+'\n'
example += turn['speaker']+': '+'<UTT>'+turn['utterance']+'</UTT>'+'\n\n'
我們像下面這樣,以詳細的Prompt請LLMs依據對話行為生成對話:
system_instruction = "\n\n".join([
"""您是一台出色的写作机器。你可以根据给定的对话行为生成流畅、准确的自然语言。对话行为是一个元组列表,每个元组的形式为(意图、域、槽、值)。意图“、”域 “和 ”槽 "的定义如下:""",
'"intents": '+json.dumps(intents, indent=4),
'"domain2slots": '+json.dumps(slots, indent=4),
"""下面是一些例子:""",
example,
"""现在请看下面的对话行为。请生成一个能准确表达给定对话行为的 {} 语篇。以 <UTT> 标记开始,以 </UTT> 标记结束。例如 “<UTT>口语</UTT>"。请勿生成与给定对话行为无关的意图、域和槽。""".format(self.speaker)
])
是不是非常簡單呢~?
最後,我們再來講個古,在ChatGPT出現以前,我們能不能使用Text-to-Text等生成模型做NLG呢?
可以!那就是基於GPT-2的SC-GPT(Semantically Conditioned Generative Pre-trained Transformer)!
SC-GPT是屬於條件生成(Conditional Generation)的一種,使用方法與LLM相同,
輸入Chatbot的對話行為,輸出就是Chatbot的對話。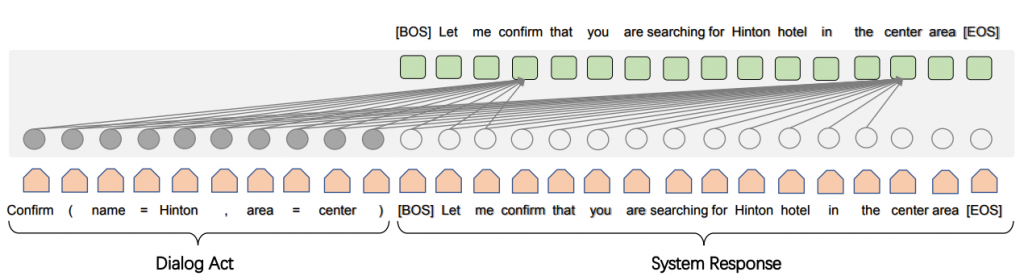
與LLMs不同的是,SC-GPT在一個大規模的標註NLG語料庫上進行預訓練,
(看了一下論文,用了400k組的語料做預訓練,意外的少...)
Referance.
EMNLP2020-Few-shot Natural Language Generation for Task-Oriented Dialog

