發現
在實踐 Velocity 時,總認為要像 Veloicty 這樣,使用工作量為基數才能準確預測,用張數會因為工作量大小不一樣,而產生交付時間不同,進而影響到 Velocity。
但當我在實務上導入 Lead Time 計算去搭配時,卻發現了一個有趣的現象,我的平均交付點數,與平均交付張數的趨勢線是一致的。
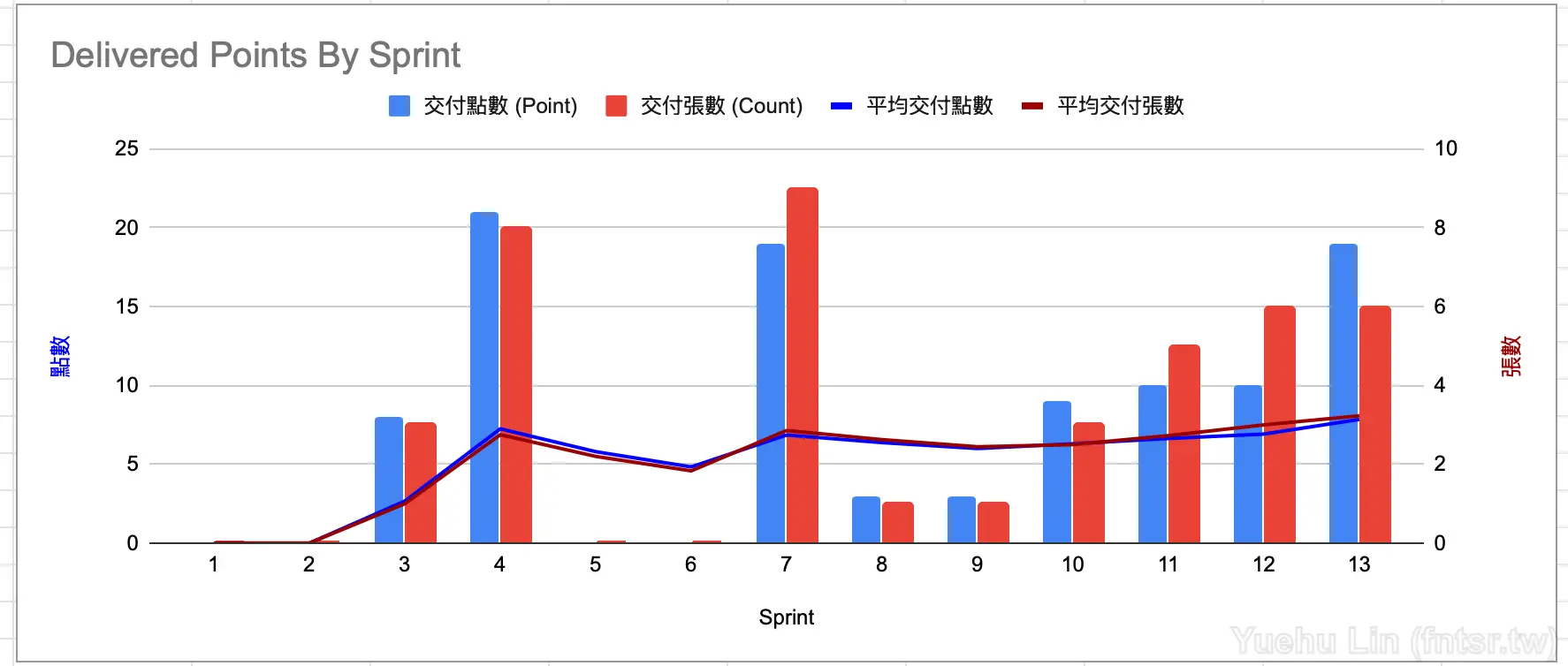
簡單推論
正如前面定義 Velocity 所描述,是使用該 Sprint 的工作量的故事點去計算。如果是用 Sprint 的張數去計算,我會借用 Thoughput 這個指標名稱去區別。也就是說:
這就時若回到前面公路作為開發流暢度的比喻,突然就會有個突發奇想:
所以在一定條件下,Velocity 與 Throughput 可以協助預測的準度是相似的,而前者因為要估算,需要的成本大於後者,那為什麼不直接使用 Thoughput 就好?
切換回來軟體開發的情境,這個「一定的條件」會是什麼?
可以思考如何自己開發的環境,是否有符合這幾點?如果是的話,你的交付張數與總工作量的故事點數,是不是趨勢很相似?那還有需要特別為了預測準度去重新估算嗎?還是維持一定的顆粒度大小就好?
這是不是一個很有意思的想法?
如果認為這個因果關係還無法信服,我這邊再羅列幾種因果關係供讀者思考。之後有時間我會再把完整的推論會涵蓋的因果關係貼上來,以及附上一個因果圖供參考。
因果關係之一:單次載貨量與總載貨量關係成正比
因果關係之二:單次載貨量與總載貨量關係成反比
因果關係之三:單次載貨量受可接受交付時間限制
因果關係之四:交貨量越高,客戶滿意度越高
因果關係之五:車輛數與路況的關係


 iThome鐵人賽
iThome鐵人賽