在學每一個新的程式語言的時候,相信大家第一個寫的一定都是Hello World!吧,那在深度學習領域中,最經典的就是MNIST手寫辨識了。
今天我們會透過tensorflow並基於CNN來打造一個簡單的訓練,如果忘記CNN是什麼的可以複習一下喔。
MNIST 包含了 60,000 個訓練範例和 10,000 個測試範例。每個範例都是一個28x28像素的灰階影像,代表一個0-9的手寫數字。每個影像都有一個對應的標籤,表示那個影像的數字。
TensorFlow是一個用於機器學習和人工智慧的免費的開源軟體庫,用於各種機器學習與數據處理任務,特別是深度神經網路的訓練和推理。 TensorFlow是由Google Brain團隊開發,最初主要用於Google內部的研究和生產,如語音識別、Gmail、相冊和搜索等
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
from tensorflow.keras import datasets:
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data():

train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255:
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255:

這些步驟是訓練卷積神經網路(CNN)之前常見的數據預處理方法,目的是確保數據形狀和數據範圍適合神經網路的輸入要求。
接著再往下會使用到一個叫做激勵函數的東西,那我們先來了解激勵函數是甚麼吧。
由於類神經網路在訓練時,會以線性的模式進行求解,但實際的問題經常為非線性的,因此需要使用激勵函數。激勵函數的作用是增加類神經網路的非線性特徵,使得網路能夠更準確地分析和預測複雜的數據模式。常見的激勵函數包括 ReLU、SeLU、Softmax 和 Sigmoid 函數。
下面我只介紹最常用的ReLU激勵函數
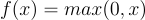

在這個圖片可以更清楚的發現,ReLU 的優點在於它在正值區間保持線性,且在負值區間輸出為零,這使得它在前向傳播時能夠保留梯度訊息,避免梯度消失問題
梯度消失問題的形成:
結果:
今天我們先到這裡吧,透過了解基本引入資料及激勵函數,明天我們就可以繼續打造我們的數字預測囉。

