為方便觀看,以下將音界咒零・一版全部語法定義縮排後寫在一起,並加入一條音界咒檔 = 音界咒・檔案結尾,以生成檔案結尾(EOF)而完整描述音界咒檔案。
音界咒檔 = 音界咒・檔案結尾
音界咒 = 句
| 句・音界咒
句 = 變數宣告式
| 算式
變數宣告式 = "元"・"・"・變數・"="・算式
算式 = 變數
| 數字
| "("・算式・")"
| 算式・運算子・算式
運算子 = "+"
| "−"
| "*"
| "/"
前文寫出的語法定義,定義的是如何生成合乎語法的字串,而非如何將字串的語法剖析出來。
這意思是說,當吾人想生成出所有(長度小於 n)的算式時,可以遍歷算式的兩個分支得到變數宣告式、算式兩種語法,這兩種語法又可以繼續分支下去,如此遞迴,便能得出所有(長度小於 n)的算式。
但是在遞迴遍歷的過程中,不同路徑很可能會造出重複的句子。
以1+2*3為例,其生成方式可能是算式 => 算式+算式 => 算式+算式*算式,先以+展開,接著展開後的第二個再以*展開,也可能是算式 => 算式*算式 => 算式+算式*算式,初始算式先以*展開,展開後的第二個算式再以+展開,如圖:
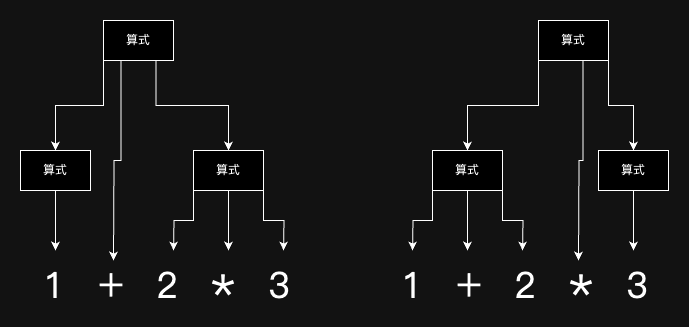
一種語法出現不同展開過程但同結果這種情況,該語法就是「有歧義的」,亦有人稱「模糊」、「模稜兩可」、「二義性」。
歧義是一項不良性質,若對上圖中得到的兩棵語法樹做後序運算求值,所得將會不相同,一個是先乘除後加減,另個則是先加減後乘除。
即使語法存在歧義,還是有辦法剖析的,舉個例子,透過回溯來得到所有可能的語法樹,再依照某種方式挑選,如此還是能用一套算法總是從一套源碼中得到相同的語法樹。
遇到歧義與法時,也可以嘗試直接修原語法定義,寫出一套無歧義的語法。算式的例子可以透過額外增加乘除式、原子式兩層級來迫使先乘除後加減:
算式 = 乘除式
| 算式・+・乘除式
| 算式・−・乘除式
乘除式 = 原子式
| 乘除式・*・原子式
| 乘除式・/・原子式
原子式 = 數字
| 變數
| "("・算式・")"

