在資料分析過程中,我們經常需要對資料進行型態轉換,以便後續的處理和分析。資料的型態可以是數字型、字串型、布林型等,進行正確的型態轉換能確保資料處理的準確性。
這裡的檔案沿用 Day 12 的檔案,其檔名為 iris_lock。直接點擊 +text,然後輸入以下內容。
首先,我們可以使用 Pandas 的 dtypes 屬性來查看資料集每個欄位的型態。
# 檢查資料型態
print(iris_df.dtypes)
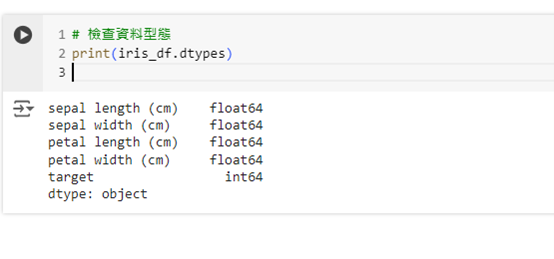
這段程式碼會顯示每個欄位的資料型態,幫助我們了解目前資料的結構。
有時候,我們需要將資料型態進行轉換。例如,將某個數值型欄位轉換為字串型。可以使用 astype() 函數來進行型態轉換。
我們可以將 sepal length (cm) 的數值轉換為字串型:
# 將數值型欄位轉換為字串型
iris_df['sepal length (cm)'] = iris_df['sepal length (cm)'].astype(str)
# 檢查轉換後的資料型態
print(iris_df.dtypes)
這樣可以將原本為數字的欄位轉換為字串格式。
有時候,資料集中的數值可能被錯誤地存為字串格式,我們可以將這些欄位轉換回數值型:
# 將字串型欄位轉換為數值型
iris_df['sepal length (cm)'] = iris_df['sepal length (cm)'].astype(float)
# 檢查轉換後的資料型態
print(iris_df.dtypes)
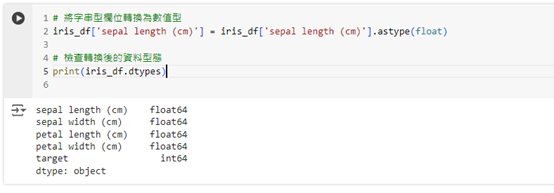
這樣可以將字串型資料正確轉換為數字型,方便後續進行數學運算或統計分析。
在機器學習中,類別型資料(例如分類標籤)通常需要轉換為數字型,這樣才能用於模型訓練。這可以通過 Pandas 的 get_dummies() 函數來實現,將類別型資料轉換為一組二進制變數。
# 將類別型資料轉換為數值型虛擬變數
iris_df = pd.get_dummies(iris_df, columns=['target'])
# 顯示轉換後的資料集
print(iris_df.head())
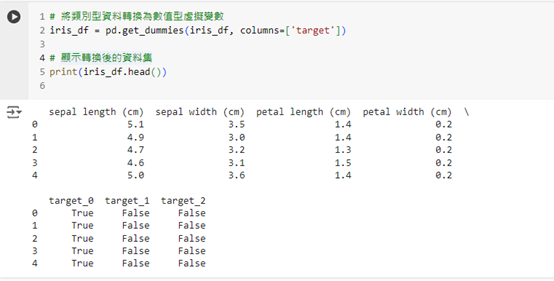
這段程式碼會將 target(花卉類型)的類別型資料轉換為數值型虛擬變數。
有時候,我們會遇到資料中存在缺失值或不正確的資料型態。我們可以使用 pd.to_numeric() 來強制將資料轉換為數字,並同時處理錯誤資料。
# 將資料轉換為數值型,並處理錯誤資料
iris_df['sepal length (cm)'] = pd.to_numeric(iris_df['sepal length (cm)'], errors='coerce')
# 檢查是否有任何資料被轉換為 NaN
print(iris_df['sepal length (cm)'].isnull().sum())
這段程式碼會將無法正確轉換的資料轉換為 NaN,我們可以在後續的資料清理中處理這些缺失值。
今天我們學習了資料型態轉換的基本操作,包括:
這些資料型態的轉換與處理是進行資料分析的基礎,正確處理資料型態將為後續的分析和建模提供準確的基礎。接下來,我們將進一步學習如何對資料進行分組和彙總分析。

