在資料分析中,分組和彙總分析是非常重要的步驟。它可以幫助我們更深入地了解資料中的不同類別特徵,並進行統計分析。今天,我們將學習如何使用 Pandas 的 groupby() 函數來進行分組和彙總操作。
一樣沿用 Day 13 的檔案,並輸入以下程式碼。
target_0、target_1 和 target_2 分組我們可以根據這三個目標欄位對資料進行分組,並計算每個分組的特徵平均值。
# 根據 target_0、target_1、target_2 進行分組,並計算平均值
grouped = iris_df.groupby(['target_0', 'target_1', 'target_2']).mean()
# 顯示分組後的平均值
print(grouped)

這段程式碼會顯示每個分組(即不同的花卉種類)對應的平均特徵值。
agg() 進行多重彙總分析除了計算平均值,我們還可以使用 agg() 函數對每個特徵應用多種彙總函數,例如 mean、max、min 等。
# 使用多重彙總函數進行分析
grouped = iris_df.groupby(['target_0', 'target_1', 'target_2']).agg({
'sepal length (cm)': ['mean', 'max', 'min'],
'sepal width (cm)': ['mean', 'max', 'min'],
'petal length (cm)': ['mean', 'max', 'min'],
'petal width (cm)': ['mean', 'max', 'min']
})
# 顯示彙總結果
print(grouped)
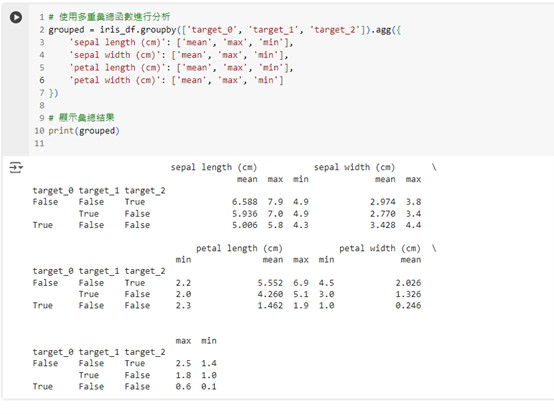
這段程式碼將對每個分組的各個特徵進行平均值、最大值和最小值的計算。
我們可以使用 size() 函數來計算每個分組中包含多少筆資料,這有助於了解資料集中每種花卉類別的分佈情況。
# 計算每個分組的大小
group_size = iris_df.groupby(['target_0', 'target_1', 'target_2']).size()
# 顯示每個分組的大小
print(group_size)
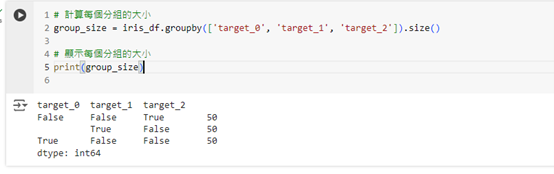
這段程式碼會顯示每個分組(花卉種類)對應的資料筆數。
transform() 進行分組轉換有時我們需要基於分組計算每個資料點的相對變化。例如,計算每個資料點相對於其分組內特徵的偏差。我們可以使用 transform() 函數來實現。
# 計算每個資料點相對於分組平均值的偏差
iris_df['sepal length deviation'] = iris_df['sepal length (cm)'] - iris_df.groupby(['target_0', 'target_1', 'target_2'])['sepal length (cm)'].transform('mean')
# 顯示結果
print(iris_df[['sepal length (cm)', 'sepal length deviation', 'target_0', 'target_1', 'target_2']].head())

這段程式碼將計算每個資料點相對於其分組平均值的偏差。
今天我們學習了如何使用 Pandas 進行資料的分組與彙總分析,包括:
groupby() 進行分組並計算平均值。agg() 函數進行多個彙總函數的應用。size() 計算每個分組的大小。transform() 計算每個資料點的相對變化。這些技巧能夠幫助我們快速深入了解不同類別資料的特徵和分佈情況。接下來,我們將進一步探討如何使用 Numpy 進行進階數學運算。

