在更深入研究之前,我想先補一些前面沒有拉出來細讀的觀念或背景知識,有些小缺塊漏掉還是會影響對整體的了解,畢竟它們運作的模式也是一環扣一環。
線性回歸用於分析線性問題,而激勵函數通常就是處理非線性的任務,這讓神經網路可以處理更複雜的問題。
以下是幾種常見的激勵函數類型 :
1.Sigmoid函數: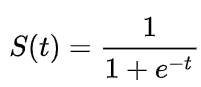
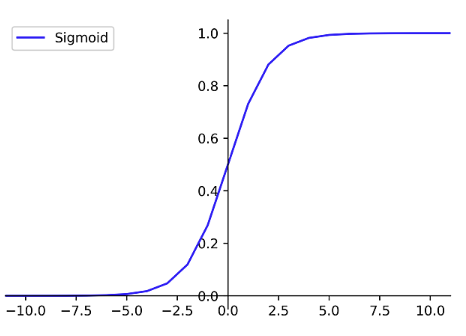
它常用於二分法,可以把輸出限制在0和1之間。雖然它是深度學習領域開始時使用頻率最高的激勵函數,卻存在著三大缺點:
(1)容易出現梯度消失(gradient vanishing)。
(2)函數輸出均值並沒有趨近於零的特性,表示它不是zero-centered 。
(3)指數運算較為耗時。
2.ReLU函數:
ReLU=max(0,x)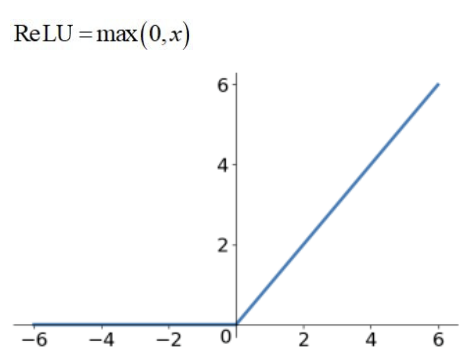
均為正值,若值為負數,則輸出為0,計算簡單且高效,廣泛應用在隱藏層。它就有很多優點:
(1)解決梯度消失問題
(2)計算量大幅降低
(3)類神經網路的稀疏性
3.Leaky ReLU函數:
ReLU=max(0.01x,x)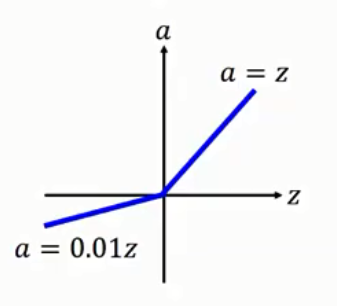
Leaky ReLU 是將 ReLU 前半段的輸出設為0.01x,這樣能防止值為負號時無法被激活的問題。理論上來說,Leaky ReLU 擁有 ReLU 所有優點,也避免負號值問題無法激活,但是使用上,無法完全證明Leaky ReLU永遠優於ReLU。
4.ELU函數: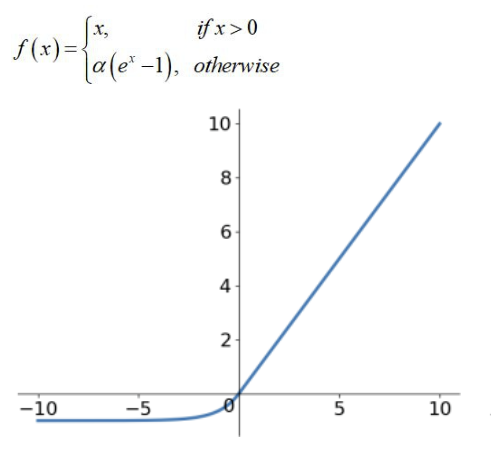
它是為了解決ReLU的問題而被提出,像是在輸入負值時有提供非零的輸出,或是相較於ReLU,在訓練過程中能更快地收斂。它也一樣理論上來說繼承了 ReLU 所有優點,卻也同樣無法保證完全優於 ReLU。

