最後幾天了,我想學自己有興趣的部分,所以今天來認識word2vec。
基本簡介
Word2vec是一群用來產生詞向量的相關模型,這些模型為淺層雙層的神經網路,用來訓練以重新建構語言學之詞文本。網路以詞表現,並且需猜測相鄰位置的輸入詞,在word2vec中詞袋模型假設下,詞的順序是不重要的。且訓練完成之後,word2vec模型可以把每個詞映射到一個向量,來表示詞與詞之間的關係,而該向量為神經網路的隱藏層。
它主要有兩種訓練方法: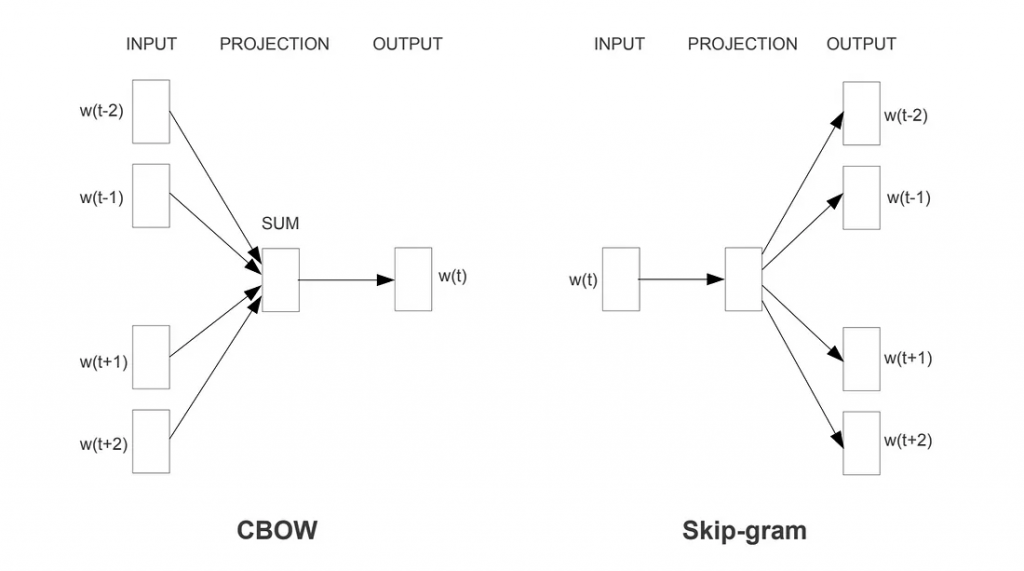
1.CBOW(Continuous Bag of Words):
訓練過程:
1.語料準備:選擇一個大規模的文本語料,通常越多越好,以便捕捉豐富的語義信息。
2.預處理:清洗文本(去除標點、轉小寫、去除停用詞等),然後將其分詞。
3.模型選擇:選擇使用 CBOW 或 Skip-Gram 進行訓練。
4.訓練:使用反向傳播等方法對模型進行訓練,更新詞向量。


 iThome鐵人賽
iThome鐵人賽