昨天介紹了word2vec的基本資訊,今天就要來實作看看。
先安裝 Gensim :
pip install gensim

開始建立模型之前,要先準備一些文本數據,以下是一個簡單的例子:
sentences = [
"I love natural language processing",
"Word embeddings are very useful",
"Word2Vec is a great tool",
"I enjoy learning about deep learning",
]
要將文本做預處理,分詞並轉換為列表格式,將句子轉換為詞列表:
sentences = [sentence.lower().split() for sentence in sentences]
訓練模型:
from gensim.models import Word2Vec
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=1)
訓練完成後,可以用模型來得到詞的向量,計算詞之間的相似度,或查找相似的詞:
word_vector = model.wv['love']
print("Vector for 'love':", word_vector)
similarity = model.wv.similarity('love', 'enjoy')
print("Similarity between 'love' and 'enjoy':", similarity)
similar_words = model.wv.most_similar('love', topn=3)
print("Most similar words to 'love':", similar_words)
保存後啟動模型:
# 保存模型
model.save("word2vec.model")
loaded_model = Word2Vec.load("word2vec.model")
最後附上完整的實作與結果:
from gensim.models import Word2Vec
sentences = [
"I love natural language processing",
"Word embeddings are very useful",
"Word2Vec is a great tool",
"I enjoy learning about deep learning",
]
sentences = [sentence.lower().split() for sentence in sentences]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=1)
word_vector = model.wv['love']
print("Vector for 'love':", word_vector)
similarity = model.wv.similarity('love', 'enjoy')
print("Similarity between 'love' and 'enjoy':", similarity)
similar_words = model.wv.most_similar('love', topn=3)
print("Most similar words to 'love':", similar_words)
model.save("word2vec.model")
最後我得到了這樣的結果: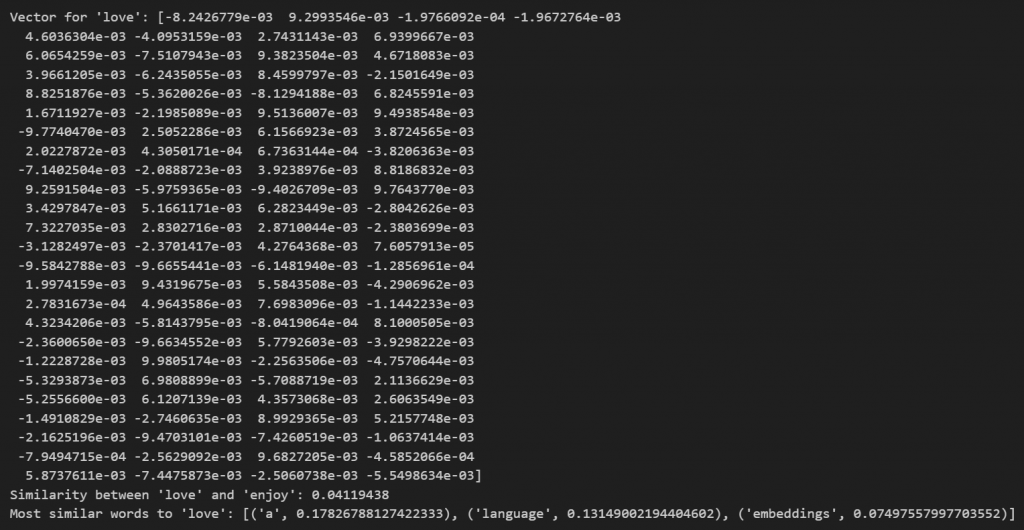
這邊補充一個我這次模型沒有做到的東西,它叫主成分分析(Principal components analysis,簡稱 PCA),
它是一種統計分析、簡化數據集的方法,會利用正交轉換來對一系列可能相關的變量的觀測值進行線性轉換,而投影為一系列線性不相關變量的值,這些不相關變量就稱為主成分,主成分可以看做一個線性方程式,其包含一系列線性係數來指示投影方向。
PCA 可以用來可視化和分析 word2vec 生成的詞嵌入,當有大量的詞向量時,PCA 可以幫助我們將這些高維度的向量投影到低維空間(通常是 2D 或 3D),這樣可以更直觀地理解詞語之間的關係。
但我才剛認識 word2vec ,一直到做完了才看到還有這個好用的東西,那這就保留給我以後自己實做看看!


 iThome鐵人賽
iThome鐵人賽