以下文章,有任何問題。都歡迎私訊我的IG
點我私訊
在資料分析過程中,排序和排名是非常常見的操作。通過對資料進行排序,我們可以輕鬆地找出最大值、最小值或前幾名的資料。建立排名表則可以幫助我們快速了解每個資料點在整體中的相對位置。今天,我們將學習如何對資料進行排序並建立排名表,以便進行比較分析。
請在之前同一個資料夾,建立一個名稱叫做sort的檔案
並先執行下段程式碼
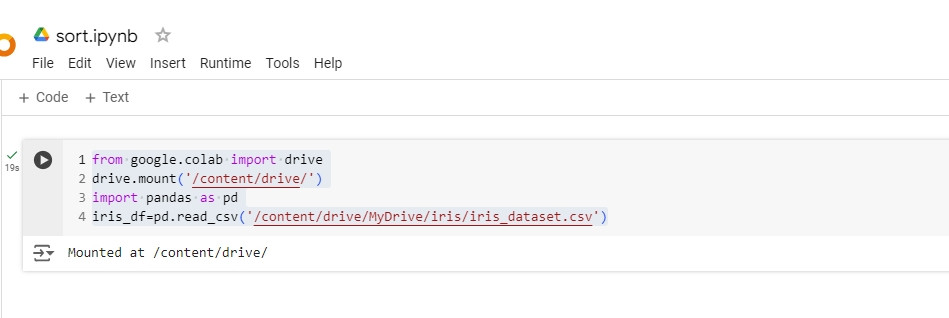
from google.colab import drive
drive.mount('/content/drive/')
import pandas as pd
iris_df=pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
Pandas 提供了 sort_values() 和 sort_index() 函數來對資料進行排序:
sort_values():根據某個或多個欄位的值進行排序。sort_index():根據索引進行排序。我們可以使用 sort_values() 根據某個欄位進行升序或降序排序。
# 根據花瓣長度進行升序排序
sorted_by_petal_length = iris_df.sort_values(by='petal length (cm)', ascending=True)
print("Results sorted by petal length in ascending order:")
print(sorted_by_petal_length.head())
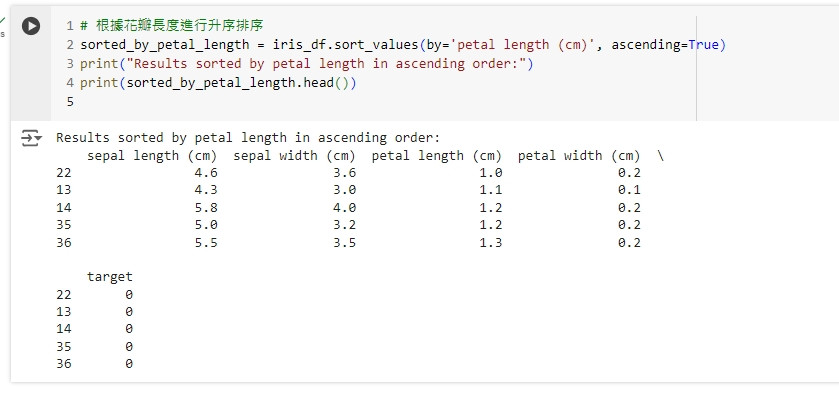
這段程式碼將資料集根據花瓣長度進行升序排序,並顯示前幾筆資料。
我們也可以根據多個欄位進行排序,例如先根據花卉種類進行排序,再根據花瓣長度排序。
# 根據花卉種類和花萼寬度進行排序
sorted_by_species_and_sepal_width = iris_df.sort_values(by=['target_0', 'sepal width (cm)'], ascending=[True, False])
print("根據花卉種類和花萼寬度進行排序的結果:")
print(sorted_by_species_and_sepal_width.head())
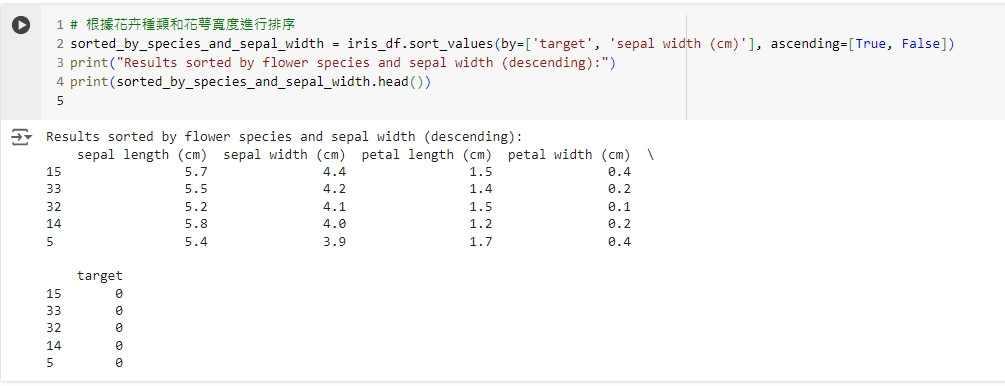
這段程式碼會先根據花卉種類升序排序,再根據花萼寬度降序排序。
有時我們需要根據索引來對資料進行排序,例如當資料順序被打亂時,可以使用 sort_index() 將其恢復。
# 根據索引進行排序
sorted_by_index = iris_df.sort_index(ascending=True)
print("Results sorted by index in ascending order:")
print(sorted_by_index.head())
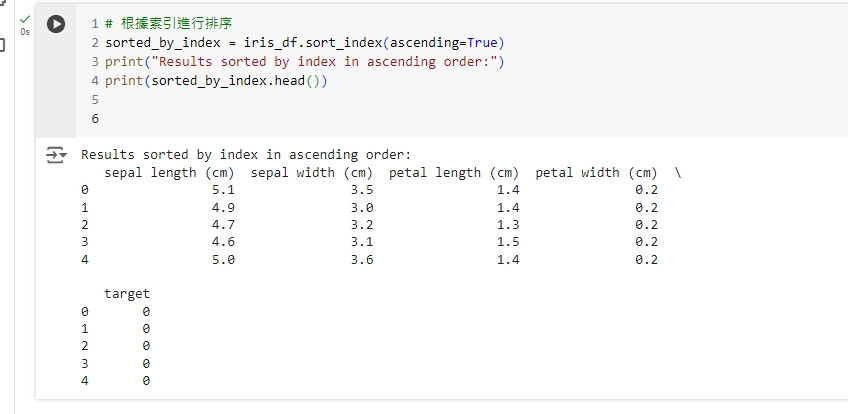
這段程式碼會將資料集根據索引進行升序排序。
Pandas 提供了 rank() 函數來對資料進行排名。排名可以用來找出某個資料點在整個資料集中的相對位置,例如前幾名或倒數第幾名。
我們可以使用 rank() 函數對資料進行排名,並使用 ascending 參數設置升序或降序。
# 根據花萼長度進行排名
iris_df['sepal length rank'] = iris_df['sepal length (cm)'].rank(ascending=False)
print("Results ranked by sepal length (in descending order):")
print(iris_df[['sepal length (cm)', 'sepal length rank']].head())
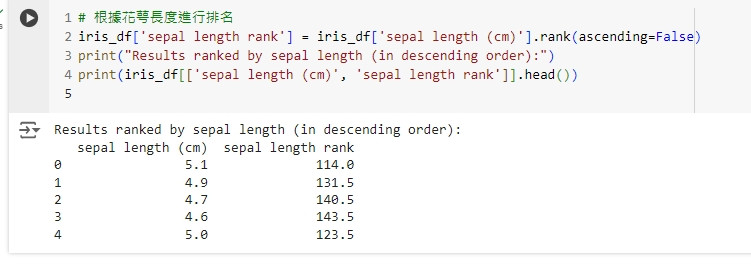
這段程式碼會根據花萼長度進行排名,並將排名結果儲存在新的欄位 sepal length rank 中。
有時我們希望在不同的分組中進行排名,例如每個花卉種類內的花瓣長度排名。我們可以使用 groupby() 來實現分組排名。
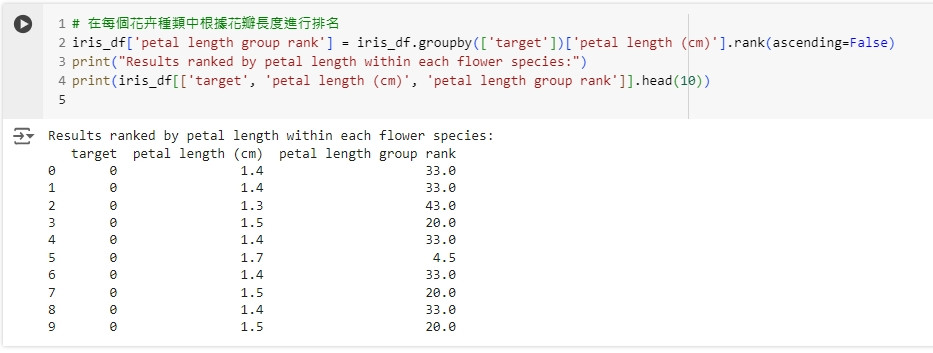
# 在每個花卉種類中根據花瓣長度進行排名
iris_df['petal length group rank'] = iris_df.groupby(['target'])['petal length (cm)'].rank(ascending=False)
print("Results ranked by petal length within each flower species:")
print(iris_df[['target', 'petal length (cm)', 'petal length group rank']].head(10))
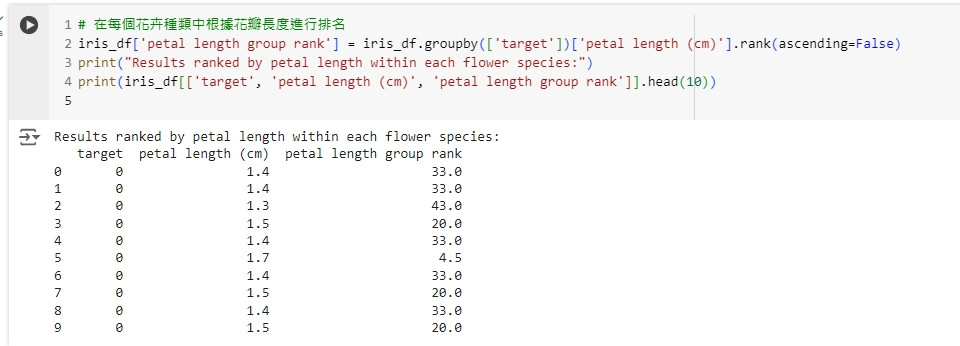
這段程式碼會在每個花卉種類內根據花瓣長度進行排名,幫助我們了解每個花卉在其種類內的相對位置。
rank() 函數支持多種排名方法,例如 average、min、max 等。我們可以通過 method 參數來設置不同的排名方法。
# 使用不同的排名方法進行排名
iris_df['rank_average'] = iris_df['sepal width (cm)'].rank(method='average')
iris_df['rank_min'] = iris_df['sepal width (cm)'].rank(method='min')
iris_df['rank_max'] = iris_df['sepal width (cm)'].rank(method='max')
print("使用不同排名方法的結果:")
print(iris_df[['sepal width (cm)', 'rank_average', 'rank_min', 'rank_max']].head())
這段程式碼會展示 average(平均值排名)、min(最小排名)和 max(最大排名)三種排名方法的差異。
nlargest() 和 nsmallest() 找出最大值和最小值有時我們希望快速找到資料集中的前幾名最大值或最小值,可以使用 nlargest() 和 nsmallest() 函數來實現。
# 找出花萼長度最大的五筆資料
top5_sepal_length = iris_df.nlargest(5, 'sepal length (cm)')
print("Top 5 records with the largest sepal length:")
print(top5_sepal_length[['sepal length (cm)', 'sepal length rank']])
# 找出花萼寬度最小的三筆資料
bottom3_sepal_width = iris_df.nsmallest(3, 'sepal width (cm)')
print("Bottom 3 records with the smallest sepal width:")
print(bottom3_sepal_width[['sepal width (cm)']])
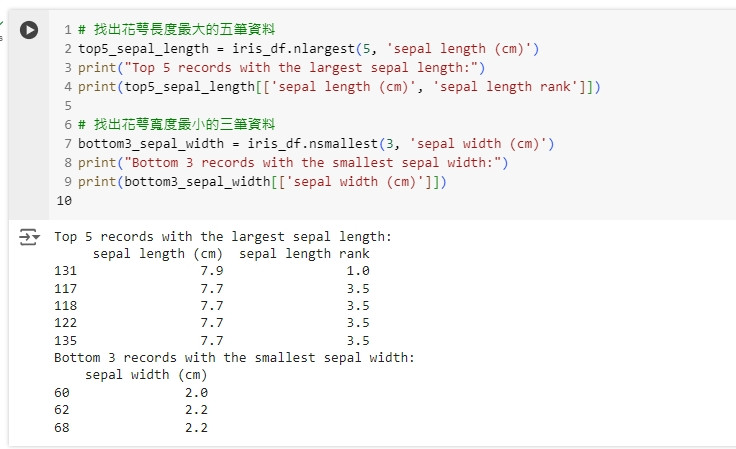
這段程式碼會找出花萼長度最大的五筆資料和花萼寬度最小的三筆資料,方便我們進行快速比較分析。
今天我們學習了如何對資料進行排序與排名,包括:
sort_values() 進行單個或多個欄位的排序。rank() 函數建立資料的排名表。nlargest() 和 nsmallest() 找出資料集中的最大值和最小值。排序和排名是資料分析中非常重要的操作,它們可以幫助我們更好地理解資料的分佈情況,並進行有效的比較分析。接下來,我們將學習如何使用餅圖來展示資料的比例分佈。


 iThome鐵人賽
iThome鐵人賽