在微服務架構中,會同時存在多個服務,這些服務各自使用不同的技術、存在於不同的主機、有各自的生命週期,這使系統的 複雜度大幅提升,同時也讓 維運成本大幅提升,也因此建立起良好的 監控機制 是十分重要的,可以透過監控來定位問題、觀測潛在問題等,確保整個系統運作穩定。
雖然說監控很重要,但它要面對的挑戰也不少,像是:
Prometheus 是一套開源的監控、警示系統,用來收集和儲存 時間序列資料(Time Series Data),對於需要觀測一段時間或是某個時間點的變化變得容易很多,是一套非常受歡迎、廣泛應用在微服務架構中的監控系統。
補充:Prometheus 最早是由 SoundCloud 所創造,現已納入 CNCF 的項目。

Prometheus 整體架構如下圖:
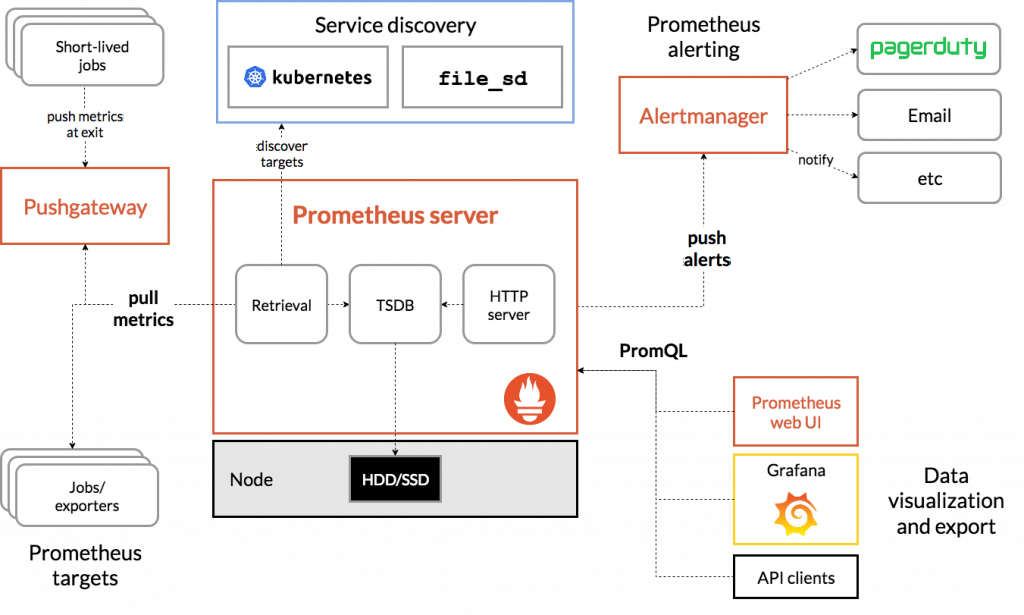
從上圖可以看到 Prometheus 是由多個元件所組成,包含:Prometheus Server、Pushgateway、Exporter、Alertmanager 等,後面將會針對這些元件做更詳細的說明。
在 Prometheus 中,每一筆資料都是採用 時間序列(Time Series) 來儲存的,每個 Time Series 是由一個 指標(Metric) 名稱與一組 標籤(Label) 來標識,並由多個 樣本(Sample) 組成,這些 Sample 會包含 時間戳(Timestamp) 與 值(Value)。
用實際的例子來說明,我們定義了一個 Time Series 為「HTTP Code 為 200 的請求數量」,假如這個 Time Series 是由 3 個 Sample 構成且它們代表的意義如下:
sample1:在時間點 t1,累積 HTTP Code 200 的回應累積數量為 10。sample2:在時間點 t2,累積 HTTP Code 200 的回應累積數量為 30。sample3:在時間點 t3,累積 HTTP Code 200 的回應累積數量為 50。可以得知 sample1 到 sample3 HTTP Code 200 的請求數量從 10 增加到 50,說明了這段時間內請求數量增加的趨勢。
Metrics 是一串符合正則表達式 [a-zA-Z_:][a-zA-Z0-9_:]* 的字串,用來表示某個特定的測量,可以視為 Time Series 的名稱,如:prometheus_http_request_total、cpu_usage 等。
而 Metrics 又可以分成下列四種類型:
0,如:prometheus_http_requests_total 是用來計算 HTTP 請求的總數。cpu_temperature 是用來記錄 CPU 溫度的變化。Labels 是由 標籤名稱(Label Name) 與 標籤值(Label Value) 組成的 key value 對,在設計上有以下限制:
[a-zA-Z_][a-zA-Z0-9_]*。下方是符合格式的 Label 範例:
{status="200", method="GET", path="/users"}
假如有一個 Metric 為 prometheus_http_requests_total,可以搭配 Label 來區分不同 HTTP Code、HTTP Method 與 Path,形成一個 Time Series。下方是範例格式,取得 HTTP Code 為 200、HTTP Method 為 GET 及 Path 為 /user 的累積請求數量:
prometheus_http_requests_total{status="200", method="GET", path="/user"}
Prometheus Server 是 Prometheus 生態中最核心的角色,負責收集、儲存及查詢 Time Series Data,它由三個元件所組成,分別是:收集引擎(Retrieval)、時間序列資料庫(Time Series Database, TSDB) 及 HTTP 伺服器(HTTP Server)。
通常要監控的服務會提供路徑為 /metrics 的 Endpoint,讓 Retrieval 定期從該 Endpoint 拉取(Pull) 資料,並根據 Metric 的類型將資料轉換成內部的 Time Series 表示格式。
這些提供 /metrics Endpoint 的服務通常會使用 函式庫(Client Library) 來建立與產生相關資料,如果要監控的不是一個服務而是一個資料庫、伺服器等,像是:MySQL、Linux Server,可以透過 Exporter 來幫忙整理資料,並提供 /metrics Endpoint 讓 Retrieval Pull 資料。
補充:透過 Pull 的方式來取得資料可以避免大量服務主動 推送(Push) 監控資料造成網路阻塞。
補充:對 Client Library 與 Exporter 感興趣的朋友,可以參考官方文件的說明。
TSDB 是 Prometheus 的儲存引擎,Retrieval Pull 下來的資料經轉換後就會由 TSDB 進行儲存。
HTTP Server 提供了多個 API 讓使用者可以存取以獲取相關資料,甚至提供了 GUI 介面讓使用者可以透過 Prometheus 定義的查詢語言 - PromQL 來查詢、聚合 Time Series Data。
下方是 HTTP Server 提供的幾個 API:
/metrics:Prometheus 自身的監控 Endpoint,讓使用者可以監控 Prometheus Server 的狀態。/api/v1/query:透過 PromQL 來查詢資料。/api/v1/query_range:透過 PromQL 來查詢並獲取指定時間範圍內的資料。補充:想深入了解有哪些 HTTP API 的朋友,可以參考官方文件的說明。
在微服務架構中,可能存在一些無法提供 /metrics Endpoint 的服務,像是:Cronjob 等,面對這種情況,Prometheus 提供了 Pushgateway 的元件,讓這些服務主動 推送(Push) 資料到 Pushgateway,Retrieval 會定期從 Pushgateway Pull 資料。
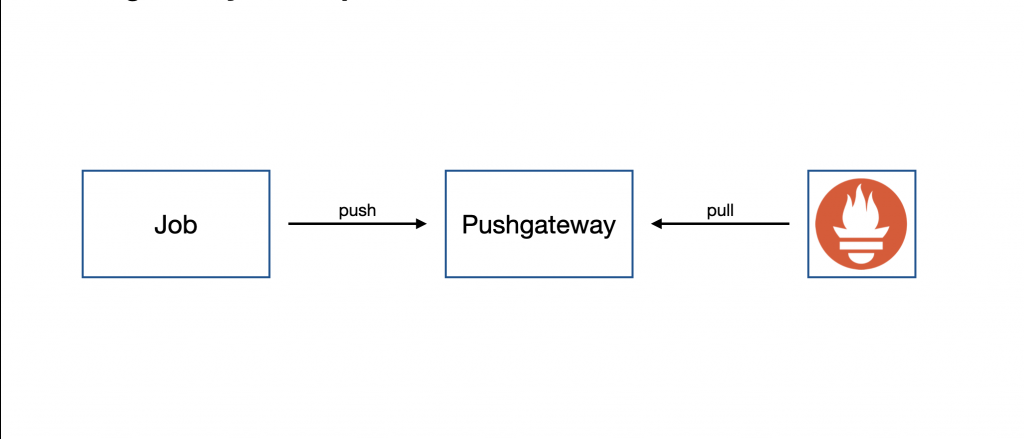
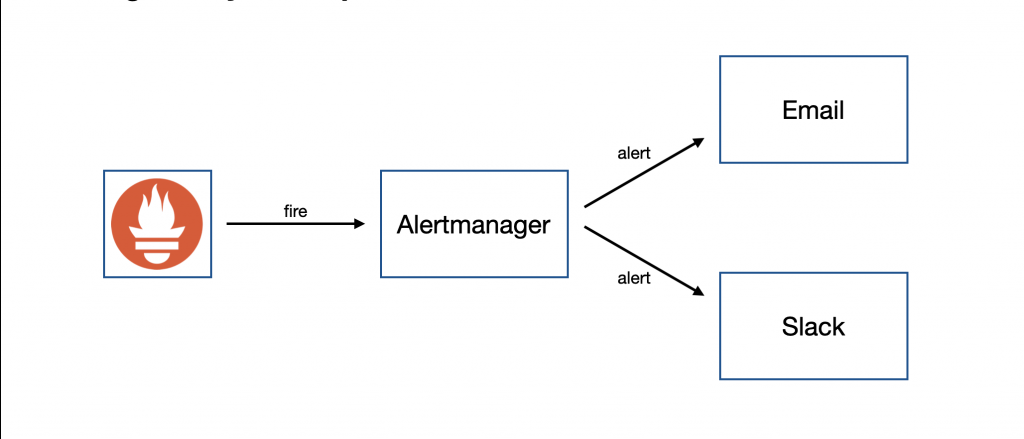
Alertmanager 會負責處理 Prometheus 的警報發送,發送的媒介可以是電子郵件、Slack 等,透過警報發送來主動告知維運人員系統出現異常,甚至是潛在風險,可以有效降低風險,建立起更加完備的監控機制。
前面有提到 PromQL 是 Prometheus 定義的查詢語言,可以用來查詢、聚合 Time Series Data,透過 Prometheus GUI 可以使用 PromQL 將這些資料以圖表的方式呈現,或是讓外部服務經由 HTTP Server 提供的 API 來獲取資料。
PromQL 共有四種資料型別,分別是:瞬時向量(Instant Vector)、區間向量(Range Vector)、純量(Scalar) 與 字串(String),這些資料型別分別用於不同情況的查詢與分析需求。
當我們直接透過一個 Metric 名稱、Label 進行查詢時,PromQL 會回傳符合條件的所有 Time Series 最新的值,這些值即 Instant Vector。
假設有 3 個 Sample:
t1,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 10。t2,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="404"} 的值為 50。t3,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 200。如果在 t3 發生後立刻執行以下查詢:
prometheus_http_requests_total
查詢結果將會回傳 prometheus_http_requests_total{status="200"} 在 t3 的值以及 prometheus_http_requests_total{status="404"} 在 t2 的值,如下表所示:
| Time Series | 值 |
|---|---|
prometheus_http_requests_total{status="200"} |
200 |
prometheus_http_requests_total{status="404"} |
50 |
如果想要查詢一段時間內的 Sample,就可以使用 Range Vector,透過在 [] 中指定時間即可取出該段時間內的 Sample 集合。下方是查詢過去 5 分鐘內 Metric 名稱為 prometheus_http_requests_total 所有 Sample 的 PromQL 查詢條件:
prometheus_http_requests_total[5m]
上方範例可以看到 [5m] 的查詢條件,5 為 持續時間(Time Durations)、m 為 單位(Unit),下方是 PromQL 提供的 Unit:
ms:毫秒。s:秒。m:分鐘。h:小時。d:天,即 24 小時。w:週,即 7 天。y:年,即 365 天。Scalar 是浮點數值,通常用於計算或是作為數值的篩選條件。
假設有 3 個 Sample:
t1,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 10。t2,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="404"} 的值為 50。t3,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 200。如果這時候使用下方查詢條件將會把每個值都除以 10:
prometheus_http_requests_total / 10
補充:上方 PromQL 中使用的
10即為 Scalar。
結果如下表所示:
| Time Series | 值 |
|---|---|
prometheus_http_requests_total{status="200"} |
20 |
prometheus_http_requests_total{status="404"} |
5 |
除了運算值以外,還可以透過比較運算來篩選出符合條件的 Sample,使用下方查詢條件將會過濾出值大於 100 的結果:
prometheus_http_requests_total > 100
結果如下表所示:
| Time Series | 值 |
|---|---|
prometheus_http_requests_total{status="200"} |
200 |
字串在 PromQL 通常會與 函數(Function) 一起使用,比如:針對 Label 做一些特殊處理等。
以 label_replace 函數當作範例,透過它來擴展新的 Label,並以指定 Label 的值作為擴展之 Label 的值。下方查詢條件會將 Label status 的值擴充至 Label code:
label_replace(prometheus_http_requests_total, "code", "$1", "status", "(.+)")
補充:上方 PromQL 中使用 雙引號(") 的部分就是 String。
假設有 3 個 Sample:
t1,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 10。t2,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="404"} 的值為 50。t3,Metric 名稱為 prometheus_http_requests_total 且 Label 為 {status="200"} 的值為 200。那麼使用上方 PromQL 會得到下表結果:
| Time Series | 值 |
|---|---|
prometheus_http_requests_total{status="200", code="200"} |
200 |
prometheus_http_requests_total{status="404", code="404"} |
50 |
PromQL 提供了非常多種函數讓使用者可以計算出一些資訊來進一步監控、分析服務。由於函數非常多,不太可能在這篇文章逐一說明,所以下面會介紹幾個實務上較常用的函數供大家參考。
rate 函數是用來計算指定時間範圍內 Time Series Data 的 平均增長率。下方是範例 PromQL 語法,透過 rate 函數得出過去 5 分鐘內 prometheus_http_request_duration_seconds_count{path="/"} 的平均增長率,進而觀察這段時間內該 API 處理時間的變化:
rate(prometheus_http_request_duration_seconds_count{path="/"}[5m])
假如在這 5 分鐘產生了 5 個 Sample:
t1,值為 100。t2,值為 105。t3,值為 110。t4,值為 115。t5,值為 120。由上方範例可以鎖定 時間窗格(Time Window) 為 5 分鐘,在這 5 分鐘內產生了 5 個 Sample,其中,最新的 Sample 為 t5、最舊的 Sample 為 t1,只要將 t5 的值減去 t1 的值,就可以得出增加的數量:
120 - 100 = 20
有了增加的數量之後,就可以來計算平均增長率,這裡是以 秒 為單位,所以我們將 5 分鐘轉換為 300 秒,接著,以 增加的數量/總秒數 的公式進行計算:
20 / 300 = 0.06667
最終得出的數值 0.06667 即 prometheus_http_request_duration_seconds_count{path="/"} 在 5 分鐘內的平均增長率。
irate 函數是用來計算指定時間範圍內 Time Series Data 的 瞬間增長率。下方是範例 PromQL 語法,透過 irate 函數得出過去 5 分鐘內 prometheus_http_request_duration_seconds_count{path="/"} 的瞬間增長率,進而觀察這段時間內該 API 處理時間的 突發變化:
irate(prometheus_http_request_duration_seconds_count{path="/"}[5m])
假如在這 5 分鐘產生了 5 個 Sample:
t1,發生於第 60 秒,值為 100。t2,發生於第 120 秒,值為 105。t3,發生於第 180 秒,值為 110。t4,發生於第 240 秒,值為 115。t5,發生於第 300 秒,值為 120。由上方範例可以鎖定 Time Window 為 5 分鐘,在這 5 分鐘內產生了 5 個 Sample,我們要從這 5 個 Sample 中取樣,瞬間增長率取的是 最新的兩個 Sample 來計算增加的數量,也就是拿 t5 的值與 t4 的值相減:
120 - 115 = 5
得出增加的數量之後,就要來取 這兩個 Sample 的時間差,也就是拿 t5 的時間與 t4 的時間相減:
300 - 240 = 60
最後,就可以拿增加的數量與時間差相除來得出瞬間增長率:
5 / 60 = 0.08334
最終得出的數值 0.08334 即 prometheus_http_request_duration_seconds_count{path="/"} 在 5 分鐘內的瞬增長率。
在終端機輸入下方指令以便從 Docker Hub 下載 Prometheus 的 Docker Image:
$ docker pull prom/prometheus
Prometheus 可以透過撰寫 YAML 檔來進行設定,像是:抓取資料的頻率、抓取資料的目標等。透下方指令產生 prometheus.yml:
$ mkdir <FOLDER>
$ touch <FOLDER>/prometheus.yml
接著,調整 prometheus.yml 的內容,透過 global 來定義全域設定,以下方範例來說,設定 scrape_interval 為 5s 讓 Prometheus 以每 5 秒的頻率抓取資料。透過設置 scrape_configs 來設定抓取資料的相關設定,首先,需要指定 job_name 來替該 Job 命名,然後可以透過 static_configs 來設定靜態目標,以下方範例來說,我們指定目標為 Prometheus 本身:
global:
scrape_interval: 5s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
補充:在複雜的微服務架構下,會更傾向用 服務發現機制(Service Discovery) 的方式來找到目標並抓取資料,不過為了讓內容保持簡單易懂,這裡使用靜態的方式來說明。
設定完了以後,就可以透過下方指令將 Prometheus 架設起來,運用 Docker 相關指令來將剛剛建立的資料夾與 prometheus.yml 綁定至 Container 中,並將 port 指定為 9090:
$ docker run --name <NAME> -p 9090:9090 -v /<FOLDER>:/etc/prometheus prom/prometheus
打開瀏覽器並存取 http://localhost:9090,會看到 Prometheus 提供的 GUI:
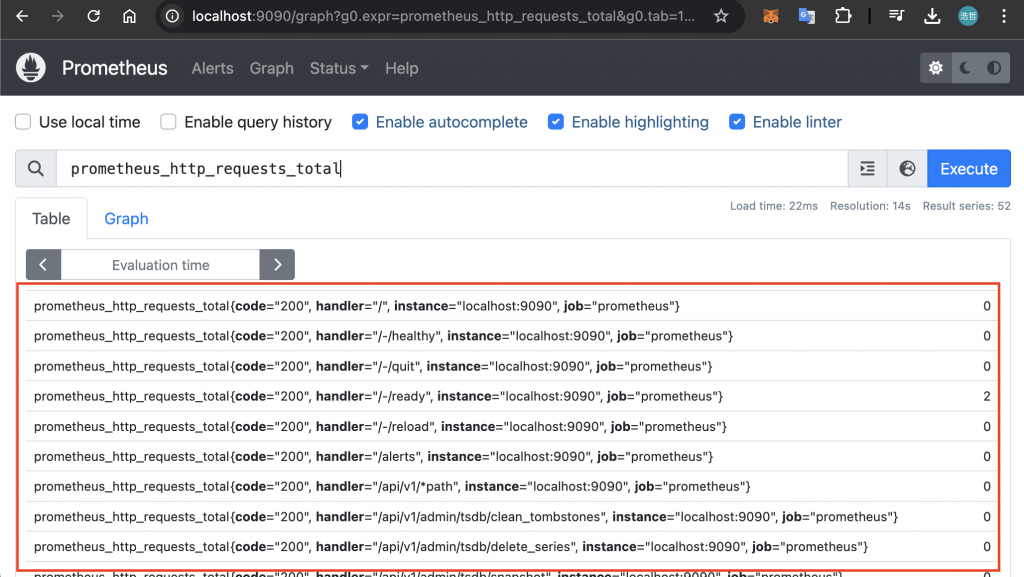
透過 Prometheus GUI 我們可以在「Graph」頁面使用 PromQL 來查詢 Time Series Data,也可以運用函數來繪製出有意義的圖表。在頁面上方的輸入框直接輸入 prometheus_http_requests_total 就可以找出所有 Metric 名稱為 prometheus_http_requests_total 的 Time Series,這些 Time Series 的值會取最新 Sample 的值,也就是 Instant Vector:
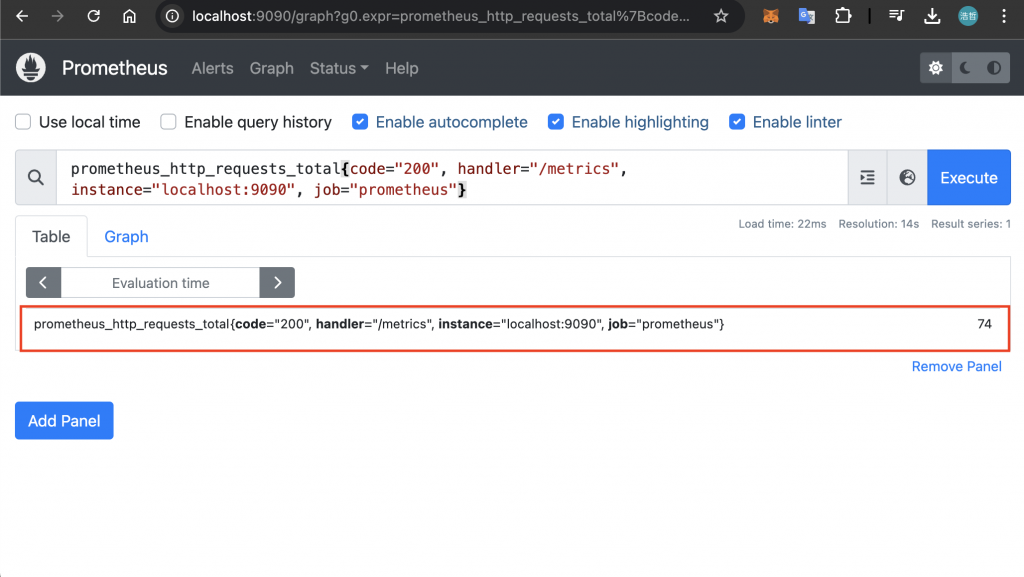
當然也可以透過 Label 來過濾資料,以下方範例來說,在輸入框輸入 prometheus_http_requests_total{code="200", handler="/metrics", instance="localhost:9090", job="prometheus"} 即可過濾出該 Time Series:
最後,來試試看繪製圖表,將頁面下方的頁籤切換至「Graph」並在上方輸入框輸入 irate(process_cpu_seconds_total[1h]),以觀察 Time Window 為 1 小時的狀況下, CPU 使用時間的瞬間增長率:
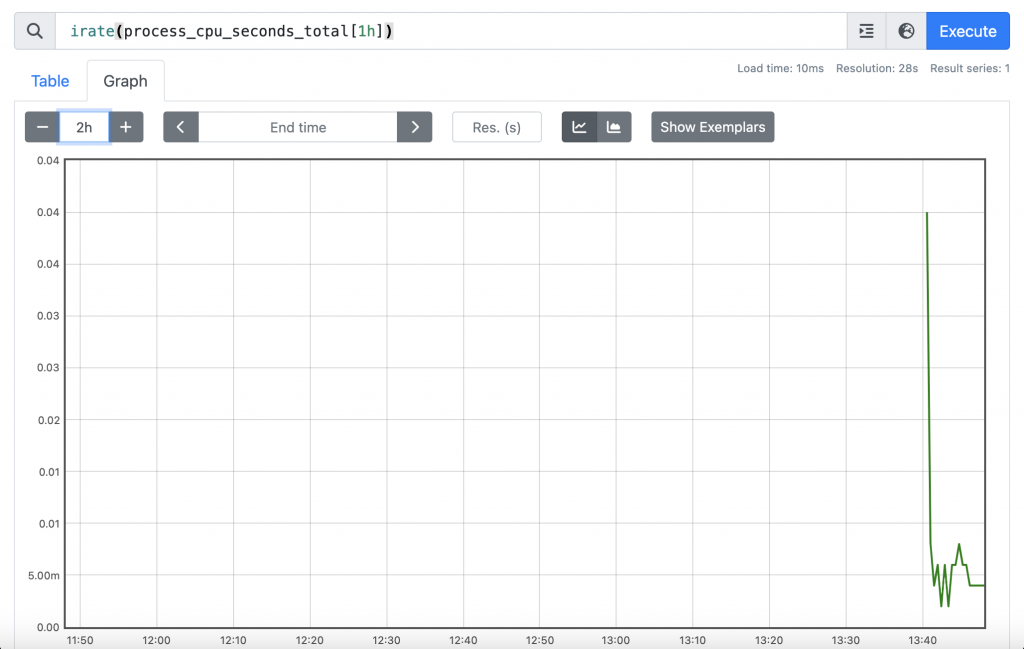
注意:圖表的上方有一個時間選擇器,該時間選擇器是用來決定圖表的起始時間與結束時間,以上方範例來說,Prometheus GUI 會以
1小時的 Time Window 去繪製過去2小時 CPU 使用時間的瞬間增長率。
Prometheus 是一套強大的監控系統,適合用於微服務架構,透過這篇文章,我們可以對 Prometheus 有更進一步的認識,包含其基本概念、組成的元件及用於查詢的 PromQL。
有了 Prometheus 的相關知識以後,下一篇將會結合 NestJS 來實現對 NestJS 服務的監控,敬請期待!


 iThome鐵人賽
iThome鐵人賽
{kind=link}