從這章開始,將進入推理加速相關技術的理論章節 🚀。
這些理論都已經都有被應用在一些知名框架當中,其實3分鐘就可以輕鬆應用了。但是如果客戶或面試官問說這些技術是什麼?為什麼選用這個框架?回答不出來就尷尬了,因為筆者曾經被洗臉過,所以筆者決定腳踏實地一步一步學習,讓讀者們以後不會被洗臉。
首先從 系統/硬體層面最佳化 (System-level / Hardware-Level Optimization) 開始,這一章介紹的是 針對計算資源的分散式系統 (Distributed Systems) ⚙️。
在很多服務中,會很常聽到Ray這個名字。Ray是一個分散式計算框架,主要針對python開發者設計,用於平行和分散計算任務,可以高效管理計算資源。
Ray不一定只能用在LLM,但LLM的使用需要龐大的計算量,正好符合Ray Serve針對大規模計算任務去分配資源的特性。而Ray當中的Ray Data、Ray Train、Ray Tune、Ray Serve、Ray RLlib,各自有適合不同LLM任務的技術。
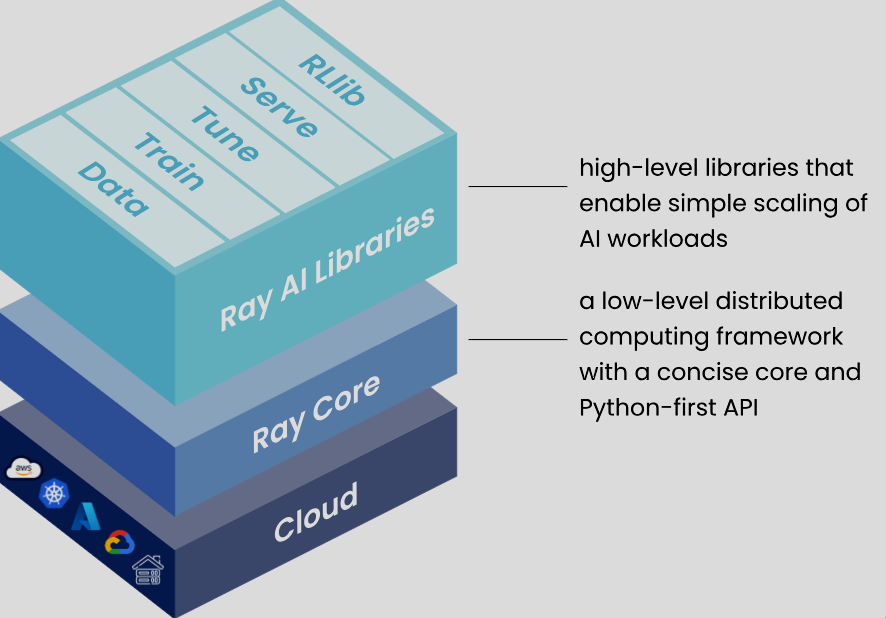
(圖源: Ray Docs)
像是Ray Data可以快速載入、處理、轉換數據,Ray Train可以做到深度學習模型的分散式訓練,而Ray Tune可以幫助微調時找到最佳化的參數,Ray RLlib可以用來做強化學習相關的工作。
這邊專心探討Ray Serve的部分。
Ray Serve則是一個可以將一個或多個模型部屬、建立線上推理、提供模型自動擴展和負載均衡服務的model serving library。其中它是framework-agnostic,也就是Ray Serve不依賴其他特定ML相關的的library或framework。在現在AI發展迅速的狀況下,很多相似於Ray Serve的服務可能有許多限制,像是只能在單一雲端供應商上使用。如果有做過infra的工作,會知道在基礎設施上要進行更改是非常耗時,而且很危險,出事會有很多人一起陪葬:)。而Ray Serve是通用的可擴展服務層 (general-purpose scalable serving layer),就可以避免被特定framework或是某些vendor綁住。
筆者在 官方文件 翻了很久,整理了以下的介紹。
如果部署FastAPI,可以加強FastAPI的併發處理能力,可以將任務分配到多個節點上面平行處理,提高API的回應速度和吞吐量。傳統上你可能會手動設定threading和multiprocessing,現在Ray就可以幫你自動處理這些複雜的工作。
如果有多台機器,Ray自動擴展的機制可以動態地調度任務到可用的計算資源上。傳統ML系統的關鍵就是在能夠為每個模型分配正確的資源來請求負載,以節省成本。
它可以用在LLM的推理stream串流、動態批次請求 (dynamic request batching)、多個節點或GPU服務 (multi-node/multi-GPU),以達成效能最佳化。也因為這些特性,它特別適合用在快速載入多個模型,像是任務可能會針對圖像、文字等各使用到不同的模型的狀況。
因為framework-agnostic的特性,目前Ray除了可以無縫結合FastAPI等服務,多個知名服務上也可以與它結合使用,像是Hugging Face Transformers、vLLM、langchain等等。甚至OpenAI、Cohere也有使用Ray作為他們infra分散式系統一部分的基礎。
Ray Serve還提供了簡單的dashboard服務,可以在上面看到你部屬的所有運作中的副本 (replicas),nodes和它們的logs,同時Ray可以確保任務完成。
當然這無法監控非Ray的服務或應用,如果需要更全面的監控,還是乖乖用prometheus + grafana這種進階的方式架設dashboard。
(註:此replicas非kubernetes中的replicas)
想到動態擴展和調度這幾個名詞,就會忍不住想到kubernetes。
(圖源: reddit,下面的留言滿有趣的XD)
簡單來說kubernetes是管理服務的一生,我們都知道kubernetes可以用pod部屬你的服務,它可以管理整個服務的生命週期,包含部署、擴展、監控、重啟,確保服務在多個伺服器上面可以穩定運行;而Ray則是只針對了運算部分的資源分配。
Kubernetes主要是針對服務層面的資源管理,雖然它可以增加pod的數量,但對於計算資源的動態調整並不靈活。相比之下,Ray能夠自動處理計算資源的分配和調整,而在kubernetes中類似的工作往往需要手動設定的,這些需要大量的infra專業知識。
如果計算資源和監控設定不好、服務出現問題了,這時開發人員就會請infra們通靈原因和解法 🔮🛠️,至少筆者以前的經驗是這樣。
所以兩者搭配使用效果是非常好的,前提是你有大量機器、客戶和需求,關於kubernetes,詳細一點的介紹會在後續的章節提到。
現在我們簡單介紹了Ray當中Ray Serve這個scalable model serving library,可以知道它的功能主要是在大型計算任務的資源分配,目前也已經在許多服務中可以找到它的身影。這一章節先理解理論,而實作的部分我們可以在後續的vLLM的應用框架中使用到。
P.S. 這一章有很多不知道怎麼翻譯的單字,所以筆者就讓它們維持英文。
知識梗圖 - 是一種一次可以跑多種模型的服務
(圖源: Medium)
Github
https://github.com/ray-project/ray
Ray Docs
https://docs.ray.io/en/latest/ray-overview/index.html
筆者與GPT-4o QA確認自己k8s那段有沒有理解錯誤

