這次的練習跟Web Speech API有關,之前並沒有接觸過,覺得滿酷的。
他會要求打開並存取你的麥克風,開始講話後,就會進行語音識別,並轉換成文字.

個人codepen
此服務在某些瀏覽器,像是chrome,因為需要將資料在服務端上做辨別加工處理,所以在離線狀態下,是無法作用的。
window.SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
recognition.start();
// 建立物件
const recognition = new SpeechRecognition();
// 設定是否要及時回傳語言識別結果,預設值為false,也就是你講完一句話後,他才回傳結果
recognition.interimResults = true;
// 設定要識別的語言,沒有設定的話,預設會根據html的lang屬性去判斷,或使用者端的語言設置
recognition.lang = "zh-TW";
// 設定是否要連續性的偵測語音說話,預設是false,也就說話停頓或中斷,語音偵測會自動結束。
// 因此預設的情況下,你必須要額外去做事件監聽,當語音偵測結束時,重新啟動語音偵測。
recognition.continuous = false;
recognition.addEventListener("end", recognition.start);
recognition.addEventListener("result", function);
當語言偵測結束後,會回傳一個物件。資料就在results中。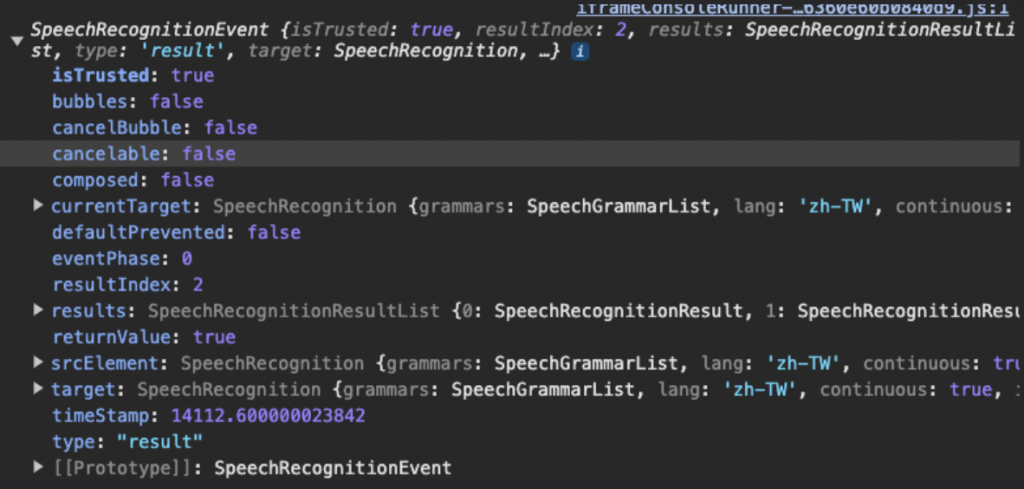
因為不是陣列,所以要取得裡面層層包覆的值,就必須先轉換成陣列。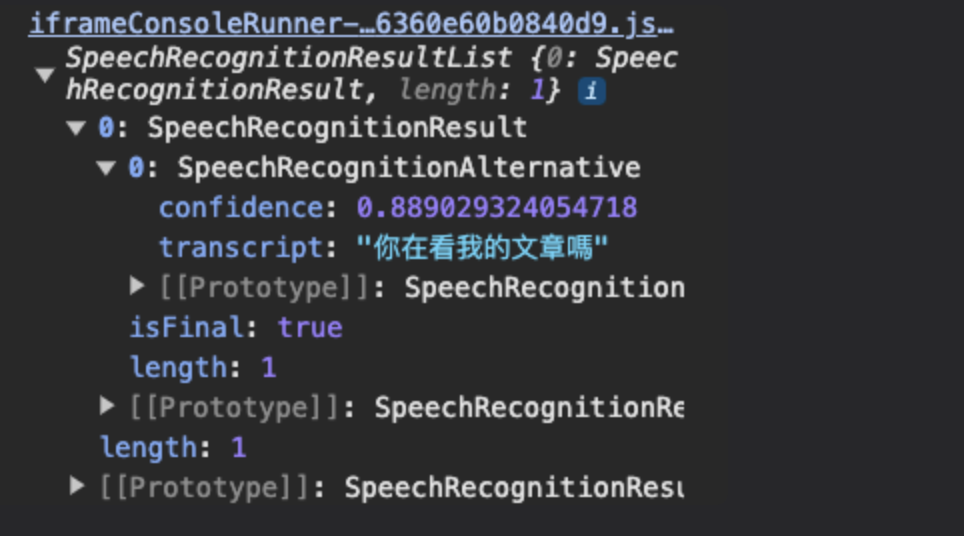
recognition.addEventListener("result", (e) => {
console.log(e);
const transcript = Array.from(e.results)
.map((result) => result[0])
.map((result) => result.transcript)
.join("");
});
confidence:轉換的成功率,介於0~1之間
transcript:語音偵測轉換後的文字
isFinal:是否語言偵測結束,為Boolean值
要將transcript渲染在畫面中時,需要去判斷isFinal。否則,每一次的語音偵測結果都會把文字一直渲染在畫面上。
if (e.results[0].isFinal) {
p = document.createElement("p");
words.appendChild(p);
}
// 中斷語音偵測事件,並回傳results
SpeechRecognition.stop();
// 中斷語音偵測事件,不會回傳results
SpeechRecognition.abort()
// 如果他罵了特定髒話,就中止偵測
if (transcript.includes("大便")) {
recognition.abort();
}
英文的語音偵測測試後,發現轉換成功率需要加強?但切成中文的語言識別後,都能夠準確地轉換每一句。
才發現原來是我的英文發音有問題啊哈哈,他聽不出來我發音,所以轉換起來不太準,我念date他轉換成dead。其實他會讀心術吧,知道我寫文章寫到快掛掉QQ,因為文筆不好...

