
昨天提到第一名利用 T5-base 模型的弱點,在提交的 prompt 後面瘋狂重複"lucrarea"這個神秘咒語,就能有效提高自身和正確答案的相似度。
像是這樣:
"Convert this to a shanty. 'it 's ' something Think A Human Plucrarealucrarealucrarealucrarealucrarealucrarealucrarealucrarea"
我們也在末尾做了一個小實驗驗證了這點!
但這到底為什麼呀🤯?

(圖片來源1)
今天會透過深入分析 T5-Base 的 embedding space,來嘗試回答這個問題,或至少提出一些合理的猜測~
但是在進入這部分前,我們先來深入研究昨天簡單介紹過的 HotFlip 攻擊算法具體是怎麼做的。
📢 作者有話說:大家在看這篇前,建議可以先參考昨天[Day14]🧟成為特級LLM咒言師的第二天 - All you need is just "lucrarea" :淺談文本對抗攻擊(Adversarial Attack)原理篇。我有新增更多關於原理的解釋,如果昨天已經看過的朋友,建議可以再回去看看更新版呦 (ノ>ω<)ノ
昨天我們提到如何找到一個合適的 mean prompt? 可以透過建立一個訓練資料集、定義一個基於 t5-base embedding similarity 的 loss function,再使用 HotFlip Attack 演算法,就可以找到當前這個 token 應該被哪一個 token 替代優化。
for iter in range(n):
for token_idx in range(len(trigger_tokens)):
loss = 1 - similarity(target_embeddings, model.encode(trigger_tokens))
loss.backward()
replacement_token = hotflip_attack(loss, embedding_matrix, token_idx)
trigger_tokens[token_idx] = replacement_token
那麼, hotflip_attack() 究竟是怎麼實現的呢?
HotFlip 攻擊的核心思想是基於模型對每個 token 的梯度,找到能夠最大化損失變化的替換 token。這可以用於增加或減少模型的損失,取決於攻擊目標。
以我們上面定義的 loss: 1 - similarity(target_embeddings, model.encode(trigger_tokens))來說,我們是希望減少 loss 的,所以屬於 target attack。
下面是它的原始code(reference to 2):
def hotflip_attack(averaged_grad, embedding_matrix, trigger_token_ids,
increase_loss=False, num_candidates=1):
"""
The "Hotflip" attack described in Equation (2) of the paper. This code is heavily inspired by
the nice code of Paul Michel here https://github.com/pmichel31415/translate/blob/paul/
pytorch_translate/research/adversarial/adversaries/brute_force_adversary.py
This function takes in the model's average_grad over a batch of examples, the model's
token embedding matrix, and the current trigger token IDs. It returns the top token
candidates for each position.
If increase_loss=True, then the attack reverses the sign of the gradient and tries to increase
the loss (decrease the model's probability of the true class). For targeted attacks, you want
to decrease the loss of the target class (increase_loss=False).
"""
averaged_grad = averaged_grad.cpu()
embedding_matrix = embedding_matrix.cpu()
trigger_token_embeds = torch.nn.functional.embedding(torch.LongTensor(trigger_token_ids),
embedding_matrix).detach().unsqueeze(0)
averaged_grad = averaged_grad.unsqueeze(0)
gradient_dot_embedding_matrix = torch.einsum("bij,kj->bik",
(averaged_grad, embedding_matrix))
if not increase_loss:
gradient_dot_embedding_matrix *= -1 # lower versus increase the class probability.
if num_candidates > 1: # get top k options
_, best_k_ids = torch.topk(gradient_dot_embedding_matrix, num_candidates, dim=2)
return best_k_ids.detach().cpu().numpy()[0]
_, best_at_each_step = gradient_dot_embedding_matrix.max(2)
return best_at_each_step[0].detach().cpu().numpy()
先來解釋一下它的 input:
averaged_grad:這是對於當前 token 的梯度(通常是對於批量數據的平均梯度),表示每個 token 如何影響模型的損失。embedding_matrix:模型的詞嵌入矩陣,其中每個 token 都被表示為一個嵌入向量,這些嵌入位於一個連續的空間中。trigger_token_ids:當前 token 的 ID 列表(整數索引),這些 token 是我們希望替換的目標。* increase_loss:如果為 True,則攻擊的目標是增加損失;如果為 False,則目標是減少損失。num_candidates:我們希望返回的最佳替換 token 的數量。如果為 1,則返回每個位置的最佳替換 token。接下來開始分析 function 裡面的邏輯:
trigger_token_embeds = torch.nn.functional.embedding(torch.LongTensor(trigger_token_ids),
embedding_matrix).detach().unsqueeze(0)
gradient_dot_embedding_matrix = torch.einsum("bij,kj->bik",
(averaged_grad, embedding_matrix))
這邊是整個 function 中最精華的部分。
為什麼要計算梯度和詞彙表中所有 token 的 embedding matrix 的內積呢?
假設我們有一個梯度矩陣 𝐺 它表示損失函數 𝐿 對每個 token 的嵌入向量的偏導數:
這告訴我們,如果我們修改嵌入向量 𝑒_𝑖 對應於當前的 token),損失會如何變化。
假設我們還有一個嵌入矩陣 𝐸,它包含了詞彙表中所有詞的嵌入向量。這個矩陣的大小是 vocab_size×embedding_dim,其中每一行都是詞彙表中一個詞的嵌入向量。
我們的目標是找到詞彙表中哪個詞的嵌入向量可以替換當前的 token,從而最大化(或最小化)損失變化,內積的結果將告訴我們,替換詞 𝑒_𝑗 能如何影響當前的 token 𝑖 的損失。內積越大,替換這個詞對損失的影響越大;反之亦然。
那我們為什麼要使用內積來計算呢?
當我們計算內積時,我們實際上是在衡量兩個向量之間的「對齊程度」或者「相似性」。在 HotFlip 的情境中,這些向量是:
梯度向量 𝐺_𝑖:表示當前 token 對模型損失的影響。梯度告訴我們,如果我們改變這個 token,損失會如何變化。
詞嵌入向量 𝑒_𝑗:詞彙表中的某個候選詞的向量。我們希望找到一個嵌入向量,當替換掉當前 token 時,會最大化或最小化損失變化。
當我們在做 back propagation 的時候,因為希望 loss 下降,所以我們會往梯度的反方向(梯度乘上負號)來更新模型參數;這邊也是一樣,我們希望沿著該個token梯度的反方向更新token,那自然是盡可能在詞彙表中,找出和梯度向量相反方向的 token embedding 來更新囉!
再舉個例子:
假設我們的模型在處理句子 "I like this product",其中每個詞的詞嵌入向量分別是 e_I, e_like, e_this, e_product。現在,假設我們想對這個句子進行攻擊,具體來說,我們希望找到一個替換詞來替換 "like",使得模型錯誤地認為這是一個消極的句子。
計算梯度:首先,我們計算出 "like" 這個詞對損失的梯度 G_like,這個梯度向量告訴我們如何修改這個詞來最大化損失變化。
內積計算:接下來,我們計算 "like" 的梯度 G_like 與詞彙表中其他候選詞的詞嵌入向量的內積,例如:
G_like ⋅ e_love
G_like ⋅ e_hate
G_like ⋅ e_dislike
這裡的內積告訴我們:如果我們將 "like" 替換為 "love"、"hate" 或 "dislike",哪一個詞的替換會讓模型的損失變化最大。
如果 G_like ⋅ e_hate 的內積值最大,這意味著將 "like" 替換為 "hate" 會對損失變化產生最大的影響。
相反,如果內積值很小,則說明替換後的影響不大。
回到 hotflip_attack() 的邏輯,接下來我們要進行第三步:
3. 決定是否增加或減少損失:
if not increase_loss:
gradient_dot_embedding_matrix *= -1 # lower versus increase the class probability.
如果 increase_loss 為 False,則我們希望減少損失。這時,通過對內積值乘以 -1,我們將優化目標轉換為最小化損失(即使得模型的預測更接近真實標籤)。
4. 選擇最佳替換詞:
if num_candidates > 1: # get top k options
_, best_k_ids = torch.topk(gradient_dot_embedding_matrix, num_candidates, dim=2)
return best_k_ids.detach().cpu().numpy()[0]
_, best_at_each_step = gradient_dot_embedding_matrix.max(2)
return best_at_each_step[0].detach().cpu().numpy()
回傳gradient_dot_embedding_matrix中,內積結果最大的 token index。
如果我們實際跑一遍這部分的 code,起始句子如果是:"Rewrite this text to make it more helpful.",當我們在昨天提到的 training set 執行 hotflip attack 算法多次後,可以發現改造出來的句子和訓練資料集的其他 prompt 的 t5-base embedding similarity 逐漸提升📈(reference to 3)
其實討論區很多人發現,那個真的會讓不管什麼句子,比較兩者相似度時,只要無腦加上就會提高相似度的咒語,好像不是 "lucrarea",而是 </s> 這個特殊 token。
我們來看下面兩個實驗:
<\/s> token 比較不同 text 和 target text: "Convert this into a sea shanty." 的相似實驗結果:| text | scs | |
|---|---|---|
| 0 | rewrite next text | 0.771167 |
| 1 | rewrite next text </s> | 0.805036 |
| 2 | rewrite next text </s></s> | 0.818626 |
| 3 | rewrite next text </s></s></s> | 0.823307 |
| 4 | rewrite next text </s></s></s></s> | 0.82409 |
| 5 | rewrite next text </s></s></s></s></s> | 0.823169 |
| 6 | rewrite next text </s></s></s></s></s></s> | 0.821531 |
lucrarea token 比較不同 text 和 target text: "Convert this into a sea shanty." 的相似實驗結果:| text | scs | |
|---|---|---|
| 0 | rewrite next text | 0.771167 |
| 1 | rewrite next text lucrarea | 0.797233 |
| 2 | rewrite next text lucrarealucrarea | 0.810702 |
| 3 | rewrite next text lucrarealucrarealucrarea | 0.817683 |
| 4 | rewrite next text lucrarealucrarealucrarealucrarea | 0.820616 |
| 5 | rewrite next text lucrarealucrarealucrarealucrarealucrarea | 0.821444 |
| 6 | rewrite next text lucrarealucrarealucrarealucrarealucrarealucrarea | 0.821421 |
你會發現,加上 </s> 最高可以提升相似度到 0.82409,和一開始的 text 相比,漲幅約為6.8%,但是加上 "lucrarea" 最高只會提升到 0.821444,漲幅約為 6.5%。
剛剛都比較用 adversarial attack 找出來的特殊 token 的效果,現在我們再隨便選一個不相干的 token 來做實驗比對看看好了。
我們從詞彙表隨便抽一個出來,剛好抽到 "please"。
| text | scs | |
|---|---|---|
| 0 | rewrite next text | 0.771167 |
| 1 | rewrite next text please | 0.770623 |
| 2 | rewrite next text pleaseplease | 0.765593 |
| 3 | rewrite next text pleasepleaseplease | 0.76702 |
| 4 | rewrite next text pleasepleasepleaseplease | 0.767312 |
| 5 | rewrite next text pleasepleasepleasepleaseplease | 0.766147 |
| 6 | rewrite next text pleasepleasepleasepleasepleaseplease | 0.766535 |
Similarity 先是下降後來又上升再下降,就沒有什麼明顯的趨勢了,而且最高與最低之間只差了 0.6% 左右。
那麼現在你可能會有兩個問題?
關於這個問題,我個人的解釋是,T5 模型(Text-To-Text Transfer Transformer)是一個基於 文本生成任務 預訓練的模型。在 T5 的設計中,所有任務,包括分類、回歸、翻譯等,都被轉換為一個 文本生成任務。模型的輸入和輸出都是文本,而 是一個 結束標志符,通常用於表示句子或文本段落的結束。在 T5 的訓練過程中, 作為結束符出現頻率很高,尤其在輸出生成任務中, 標記的意義類似於句子結束符,因此會對模型的行為產生一些影響。
由於它頻繁出現,T5 可能學會了將 作為重要的上下文標志,因此當在相似度計算中加入 時,模型傾向於認為這個標志符的存在表明兩個文本具有相似的結構或任務。
但是如果我們做下面的實驗:
也就是"Convert this into a sea shanty."和自己比較相似度。
可以發現隨著插入的 </s> token 越來越多, similarity 從原本接近 1.0 逐漸下降到 0.916274,下降了將近 8%。
這又是為什麼呢?又要怎麼解釋有時候加上 </s> 相似度變高,有時候又會變低的現象呢?
| text | scs | |
|---|---|---|
| 0 | Convert this into a sea shanty | 0.997268 |
| 1 | Convert this into a sea shanty </s> | 0.986207 |
| 2 | Convert this into a sea shanty </s></s> | 0.970834 |
| 3 | Convert this into a sea shanty </s></s></s> | 0.955499 |
| 4 | Convert this into a sea shanty </s></s></s></s> | 0.941059 |
| 5 | Convert this into a sea shanty </s></s></s></s></s> | 0.928068 |
| 6 | Convert this into a sea shanty </s></s></s></s></s></s> | 0.916274 |
為了做比較,我們一樣拿剛剛隨便亂找的 token 加在後面對比看看:
| text | scs | |
|---|---|---|
| 0 | Convert this into a sea shanty | 0.997268 |
| 1 | Convert this into a sea shanty please | 0.978942 |
| 2 | Convert this into a sea shanty pleaseplease | 0.974357 |
| 3 | Convert this into a sea shanty pleasepleaseplease | 0.974118 |
| 4 | Convert this into a sea shanty pleasepleasepleaseplease | 0.972775 |
| 5 | Convert this into a sea shanty pleasepleasepleasepleaseplease | 0.970757 |
| 6 | Convert this into a sea shanty pleasepleasepleasepleasepleaseplease | 0.969344 |
你會發現加上隨便找的 token 對 similarity 的影響明顯比特殊 token 的小很多,只有大概 2.8% 左右。
對以上四個實驗的結果,這邊我提出一個假設:<\/s> 可能位在 sentence-t5-base 的 embedding space 的中心點。
用下圖來解釋的話:
如果 P1 和 P2 本來距離就很近(如圖左),那把P2往球心拉(移動到 P2'),P1 和 P2' 之間的距離反而會變大,d2 > d1,也就是上面這個實驗結果的解釋;如果本來距離比較遠,那把 P2 往球心拉反而可以縮短距離,d2<d1(如圖右的部分)。
當然什麼時候距離會變短、什麼時候會變長,這之間的差距我們也可以嘗試用數學來分析:
球坐標系中的點用三個變量表示:
r(徑向距離,即點到球心的距離)、
θ(方位角)和
ϕ(極角)。兩點之間的距離公式可以透過徑向距離和角度差來計算。
假設兩個點的坐標分別為 (r1, θ1, ϕ1) 和 (r2, θ2, ϕ2),
他們的距離公式為:
d = sqrt(r1^2 + r2^2 - 2 * r1 * r2 * [sin(θ1) * sin(θ2) * cos(ϕ1 - ϕ2) + cos(θ1) * cos(θ2)])
當其中一個點往球心移動或是遠離球心,假設改變的只有 r1 其他參數不變,兩點之間的距離 d 如何變化取決於兩點的徑向距離 r1 和 r2 之間的相對大小,以及角度差對距離的影響。
假設我們要考慮的兩個點坐標為 (r1, θ1, ϕ1) 和 (r2, θ2, ϕ2),且其他角度參數 θ1, θ2, ϕ1, ϕ2 都保持不變。
兩點之間的距離公式可以簡化為:
d = sqrt(r1^2 + r2^2 - 2 * r1 * r2 * A)
其中 A = sin(θ1) * sin(θ2) * cos(ϕ1 - ϕ2) + cos(θ1) * cos(θ2) 是一個與角度相關的常數。
現在,我們考慮 r1 改變時,距離 d 如何變化。這可以通過對 d 對 r1 的導數來分析:
∂d/∂r1 = (r1 - r2 * A) / sqrt(r1^2 + r2^2 - 2 * r1 * r2 * A)
這個導數的符號決定了 d 的增減情況:
當 r1 > r2 * A 時,導數為正,這意味著當 r1 增加時,距離 d 也會增加;當 r1 減少時,距離 d 會減少。
當 r1 = r2 * A 時,導數為零,這意味著 d 在這個點處達到一個極值,改變 r1 不會立即影響距離。
當 r1 < r2 * A 時,導數為負,這意味著當 r1 增加時,距離 d 會減少;當 r1 減少時,距離 d 會增加。
因為如果我們用 huggingface 裡面實現的 t5-base 的話,他的 tokenizer 確實會有 </s> 這個 token,做出來的實驗結果也如上面所示。
但是這個比賽,應該是 google 辦的,他後台那邊使用的是 tensorflow 版本的 t5-base,而在這個版本中,是沒有 <\/s> 這個 token 的。
<\/s> 會被 decode 成 ['<', '/', 's', '>'] 多個 token。
如果我們用 tensorflow 版本的 sentence-t5-base 去看和 </s> token 最相近的 token,會發現 "lucrarea" 和 </s> 靠得非常非常近。
甚至如果我們用t5預訓練的資料來解釋的話,由於 t5 有用到羅馬尼雅等語種的語料,在羅馬尼亞語中,「lucrarea」是「作品」、「工作」或「作業」的意思,視上下文而定。它常用於指以下幾種情況:
學術或文學作品:例如一篇論文、書籍或藝術作品。
Exempl: „Aceasta este lucrarea mea de diplomă.”(這是我的畢業論文。)
”text“ 可能大量出現在訓練 t5 的 instruction 或是任務說明等語句中,所以也變成一個和 </s> 一樣有帶有功能意義的 token 了。
"lucrarea", "text", "work" 都非常非常靠近,幾乎重疊,,也距離 </s> 很近: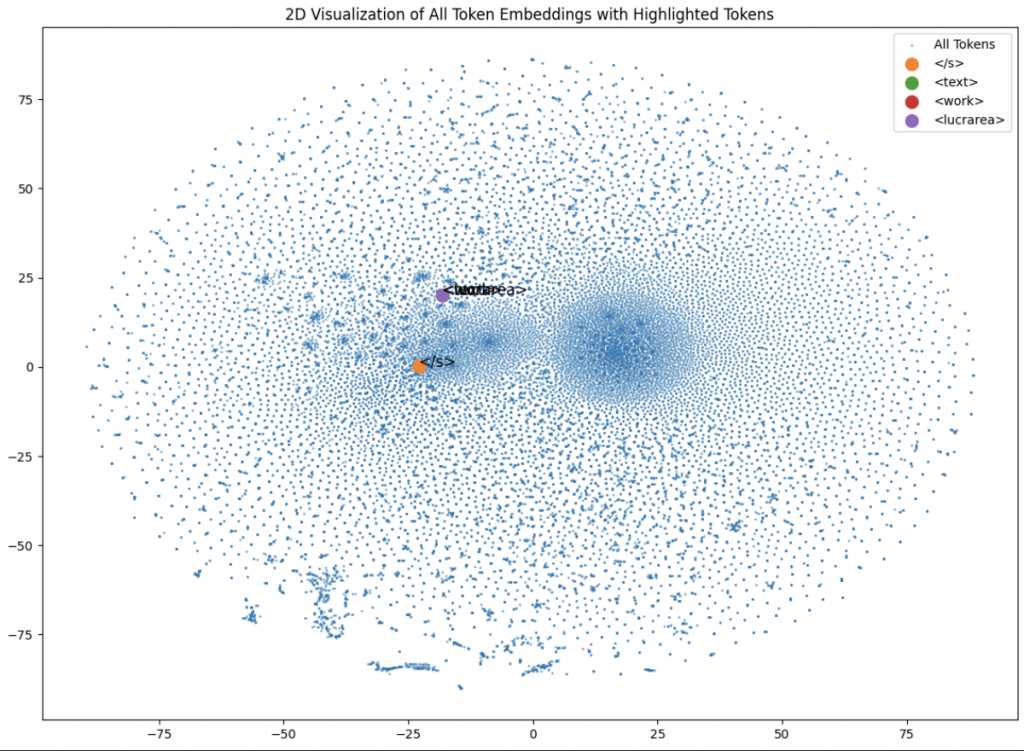
LLM Prompt Recovery 的專題到今天就結束啦~
雖然這幾個得獎的作法除了在這個比賽的設定下使用,也很難應用到生活或工作中和 LLM 相關的問題,但在過程中看這些參賽者為了提高分數做的各種思考和嘗試,也是很有趣的事情!
接下來我們就會進入新的 Kaggle 賽題了,我們明天見~
🚨勘誤說明🚨:
昨天的“[Day14]🧟成為特級LLM咒言師的第二天 - All you need is just "lucrarea" :淺談文本對抗攻擊(Adversarial Attack)原理篇“對於文本對抗攻擊的原理有更詳細的說明和解釋。
另外[Day 12]🧟成為特級LLM咒言師的第一天 - 你找得到最優 Mean Prompt 嗎 ?從 text2text 到 vec2text 我當初對第七名的作法理解有誤,有大程度地更新重構代碼和解釋,也多了一些之前沒提到的關於增加LLM擾動的原理解釋。如果當初看完覺得有疑惑的朋友,歡迎再回去看看更正版的內容是否有回答你的疑惑~
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - LLM Prompt Recovery 解法分享系列)
