在本節中,我們將深入探索如何使用深度學習中的循環神經網絡(RNN),特別是長短期記憶網絡(LSTM),來進行時間序列數據的預測。我們將使用PyTorch框架,從數據預處理、模型構建、訓練到評估,完整地演示如何應用LSTM模型進行股票價格預測。今日 Colab
PyTorch 是一個開源的深度學習框架,由Facebook的人工智慧研究小組開發。它具有以下特點:
在本節中,我們將使用PyTorch來構建和訓練LSTM模型,進行股票價格的預測。
可以藉由下面指令來安裝:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
另外須注意 Pytorch 本身需要注意自身環境的配置來選取對應的安裝指令,更多以前的 Pytorch 版本安裝也可這個連結。
LSTM(長短期記憶網絡) 是一種特殊的循環神經網絡,由 Hochreiter 和 Schmidhuber 於 1997 年提出,專門用於解決長期依賴問題。
LSTM 的核心特點:
C):負責長期信息的傳遞,能夠保留重要的歷史信息。f):決定需要遺忘多少舊信息。i):決定有多少新信息需要寫入記憶單元。O):決定輸出多少信息到下一個時間步。為什麼 LSTM 適合時間序列預測:
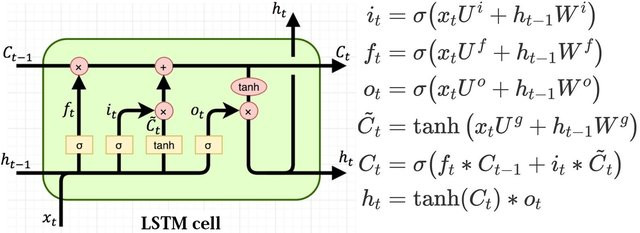
接下來,我們將利用 LSTM 的這些特性,構建一個用於股票價格預測的深度學習模型。
我們將使用yfinance庫獲取蘋果公司(AAPL)的股票數據。
import pandas as pd
import numpy as np
import yfinance as yf
# 獲取數據
data = yf.download('AAPL', start='2015-01-01', end='2021-01-01')
# 提取收盤價
data = data[['Adj Close']]
data.rename(columns={'Adj Close': 'Close'}, inplace=True)
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plt.plot(data['Close'])
plt.title('AAPL 股票收盤價')
plt.xlabel('日期')
plt.ylabel('價格')
plt.show()
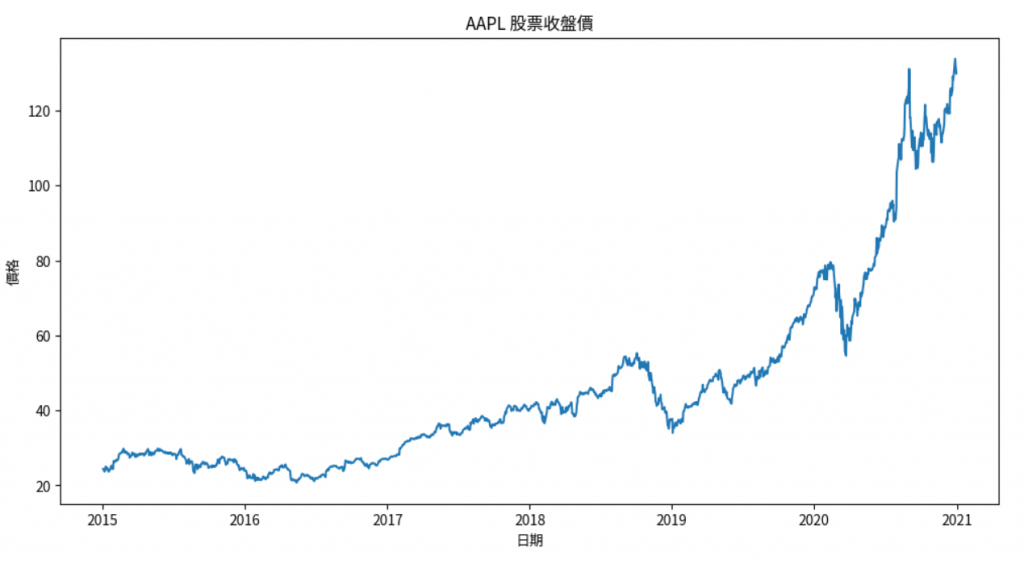
為了提高模型訓練的效率,我們需要將數據歸一化到 [0,1] 區間。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
data['Close'] = scaler.fit_transform(data[['Close']])
我們需要將時間序列數據轉換為監督學習的問題,即輸入特徵和目標值。
def create_dataset(dataset, lookback=60):
X, y = [], []
for i in range(len(dataset)-lookback):
X.append(dataset[i:(i+lookback), 0])
y.append(dataset[i+lookback, 0])
return np.array(X), np.array(y)
# 轉換為numpy數組
dataset = data.values
# 定義lookback窗口大小
lookback = 60
X, y = create_dataset(dataset, lookback)
我們分資料的方式先簡單用前面 8 成的資料當做訓練,後面2成資料當作測試
# 劃分比例
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
X_train = X[:train_size]
y_train = y[:train_size]
X_test = X[train_size:]
y_test = y[train_size:]
PyTorch的RNN模型需要輸入形狀為 (batch_size, seq_length, input_size)。
# 調整輸入形狀
X_train = X_train.reshape(-1, lookback, 1)
X_test = X_test.reshape(-1, lookback, 1)
import torch
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用設備:{device}')
class StockPriceLSTM(nn.Module):
def __init__(self, input_size=1, hidden_size=50, num_layers=2):
super(StockPriceLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 定義LSTM層
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
# 定義全連接層
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
# 初始化隱藏狀態和細胞狀態
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
# 前向傳播LSTM
out, _ = self.lstm(x, (h0, c0))
# 取最後一個時間步的輸出
out = self.fc(out[:, -1, :])
return out
輸入(Input):
(batch_size, seq_length, input_size) 的張量。
1,表示收盤價。輸出(Output):
(batch_size, 1) 的張量。
流程:
初始化隱藏狀態和細胞狀態:
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
LSTM 層計算:
out, _ = self.lstm(x, (h0, c0))
(batch_size, seq_length, hidden_size),包含每個時間步的輸出。取最後一個時間步的輸出:
out = self.fc(out[:, -1, :])
(batch_size, hidden_size)。model = StockPriceLSTM().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
X_train_tensor = torch.from_numpy(X_train).float().to(device)
y_train_tensor = torch.from_numpy(y_train).float().to(device)
X_test_tensor = torch.from_numpy(X_test).float().to(device)
y_test_tensor = torch.from_numpy(y_test).float().to(device)
num_epochs = 100
for epoch in range(num_epochs):
model.train()
outputs = model(X_train_tensor)
optimizer.zero_grad()
loss = criterion(outputs.squeeze(), y_train_tensor)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
# 在測試集上評估
model.eval()
with torch.no_grad():
test_outputs = model(X_test_tensor)
test_loss = criterion(test_outputs.squeeze(), y_test_tensor)
print(f'Epoch [{epoch+1}/{num_epochs}], 訓練集Loss: {loss.item():.4f}, 測試集Loss: {test_loss.item():.4f}')
Train 跟 Test Loss 都有持續下降,贊喔!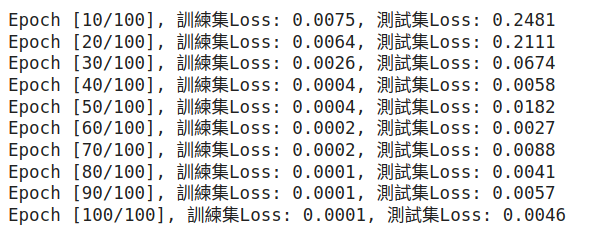
model.eval()
with torch.no_grad():
train_predict = model(X_train_tensor).cpu().numpy()
test_predict = model(X_test_tensor).cpu().numpy()
# 反歸一化
train_predict = scaler.inverse_transform(train_predict)
y_train_actual = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test_actual = scaler.inverse_transform(y_test.reshape(-1, 1))
# 構建完整的時間序列
predicted = np.concatenate((train_predict, test_predict), axis=0)
actual = scaler.inverse_transform(dataset[lookback:])
plt.figure(figsize=(12,6))
plt.plot(actual, label='實際價格')
plt.plot(predicted, label='預測價格')
plt.title('AAPL 股票價格預測')
plt.xlabel('時間')
plt.ylabel('價格')
plt.legend()
plt.show()
可以看到前面資料中因為有出現在訓練資料所以聯繫節都預測得非常好,後面是測試,只能抓到大趨勢: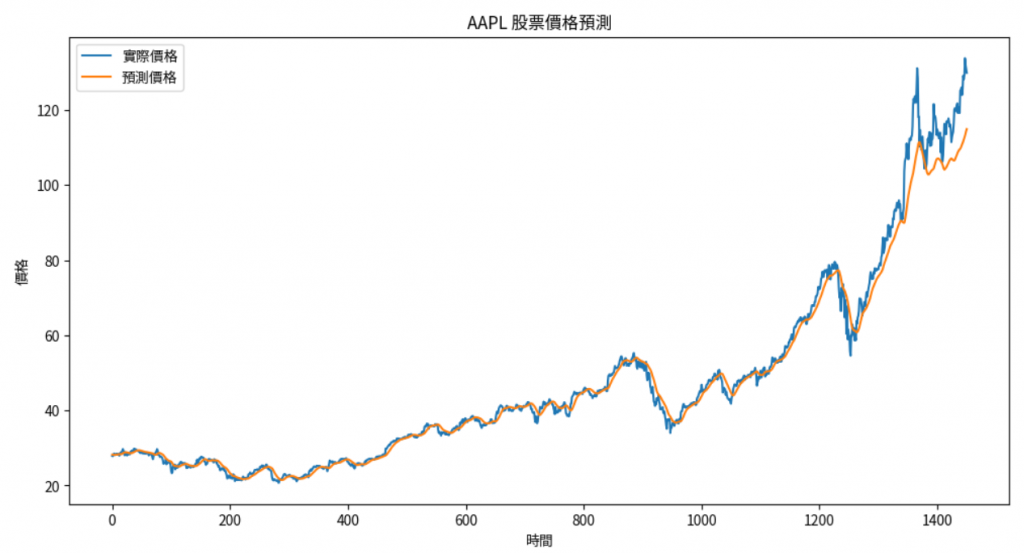
from sklearn.metrics import mean_squared_error
train_score = mean_squared_error(y_train_actual, train_predict)
test_score = mean_squared_error(y_test_actual, test_predict)
print(f'訓練集MSE: {train_score:.2f}')
print(f'測試集MSE: {test_score:.2f}')
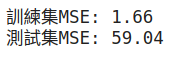
lookback窗口大小,確保模型能夠捕捉足夠的歷史信息。lookback,以免增加模型複雜度。hidden_size,如32、64、128。num_layers,如1、2、3。0.01、0.001、0.0001。Dropout:在LSTM層中添加dropout,防止過擬合。
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=0.2)
多變量輸入:除了收盤價,還可以加入開盤價、最高價、最低價、成交量等特徵。
# 例如,使用收盤價和成交量
data = data[['Close', 'Volume']]
技術指標:添加移動平均線、相對強弱指數(RSI)等技術指標。
在本節中,我們:
透過這次實踐,您應該對如何使用深度學習模型處理時間序列數據有了更深入的理解,並掌握了使用PyTorch進行模型構建和訓練的基本方法。
作業:
嘗試調整模型的超參數:如hidden_size、num_layers、learning_rate,觀察對模型性能的影響。
增加更多的特徵:如技術指標、基本面數據,構建多變量時間序列模型。
嘗試使用GRU模型:將LSTM替換為GRU,比較兩者的性能。
使用 Early Stopping 和學習率調整策略:提高模型的泛化能力。
透過這些練習,我們將能夠更靈活地應用深度學習模型進行時間序列預測,並提高模型的性能。
提示:
檢查GPU是否可用:在訓練深度學習模型時,使用GPU可以大大加速訓練過程。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
防止過擬合:在訓練過程中,監控訓練集和驗證集的損失,防止模型過擬合。
保存和加載模型:使用torch.save()和torch.load()保存和加載模型,方便後續使用。
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加載模型
model.load_state_dict(torch.load('model.pth'))
注意:
數據預處理的重要性:時間序列數據的質量直接影響模型的性能,務必仔細進行數據清洗和預處理。
模型的可解釋性:深度學習模型通常是黑盒模型,難以解釋其內部機制。在金融領域,風險控制非常重要,需謹慎使用。
風險提示:股票價格預測具有高度不確定性,模型預測結果僅供參考,不應作為投資決策的唯一依據。
1.https://ithelp.ithome.com.tw/articles/10321650
2.https://ithelp.ithome.com.tw/articles/10322059
3.https://www.youtube.com/watch?v=zuiACAhRUzA&ab_channel=%E9%99%B3%E7%B8%95%E5%84%82VivianNTUMiuLab
4.https://blog.sappy.tw/posts/ai/nlp/lstm/

