昨天提到生成式 AI 中生成器負責根據隨機噪聲生成逼真的數據或圖片,這種架構在早期的生成任務中有廣泛應用,不過隨著技術進步Encoder-Decoder架構被提出,這種架構逐漸取代了單純的生成器,成為更強大且靈活的工具。這裡的Decoder與生成器相似,它也能生成新的數據,不過其背後的工作原理更為複雜和高效。而今天我們就要來說說在這種架構中是如何生成文字的。
Seq2Seq(Sequence to Sequence)模型是一種非常經典的深度學習模型,該模型是Google開發用於翻譯的一種特殊架構,其架構特別適用於處理序列輸入並生成序列輸出的任務該模型的核心思想是使用編碼器(Encoder)將輸入序列編碼為一個固定長度的向量,然後使用解碼器(Decoder)將這個向量解碼為目標序列,而現在讓我們來分別介紹該模型的詳細數學吧。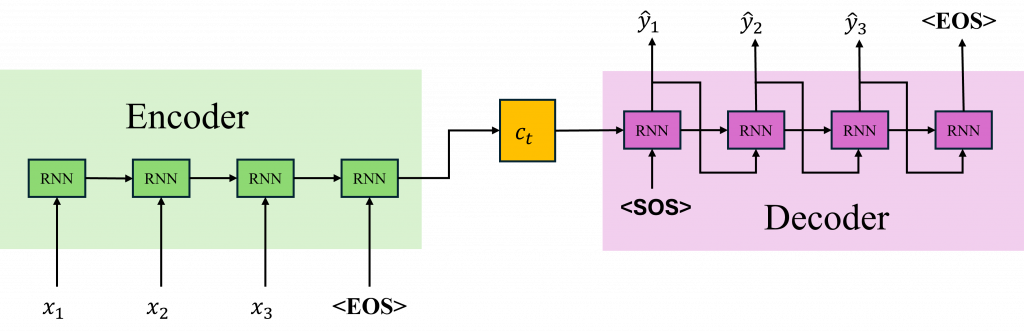
在Seq2Seq的模型架構中,其中的構造都是使用循環神經網路或長短期記憶這類的模型組合而成的。在Encoder的部分,和進行文字分類時一樣將輸入序列轉換成一個隱藏狀態,但在Seq2Seq架構中我們稱這個隱藏狀態為上下文向量(Context Vector)。
在分類任務中我們是通過分析這個上下文向量,並交給全連結層進行運算與分析;而在Seq2Seq架構中,我們則是把這個隱藏狀態當作整個架構的知識庫並傳遞到Decoder中,也就是Enocder扮演的角色是負責理解我們輸入資料的詳細內容。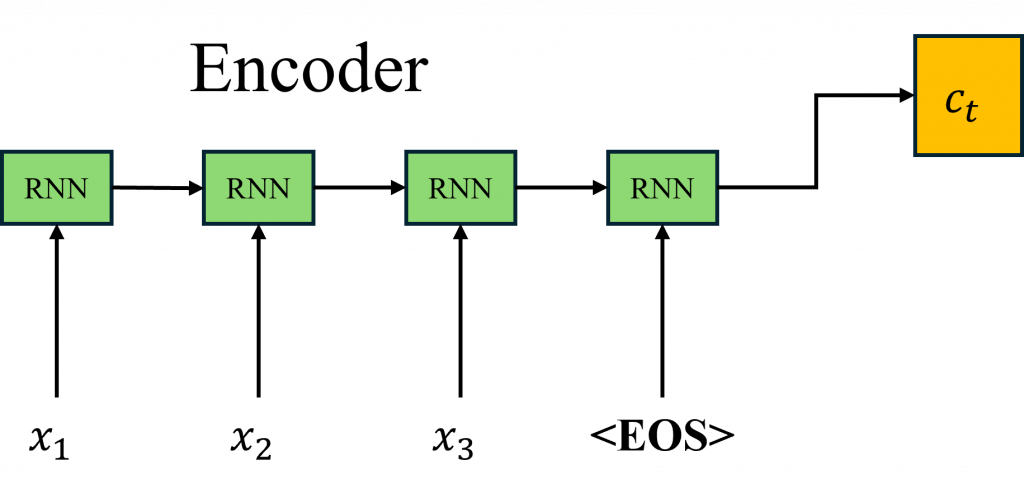
因此對其Encoder的數學公式其實就非常的簡單,他就與我們之前講到的循環神經網路與LSTM完全一模一樣,沒有任何的變化,不過我們在後續Decoder會提到一些比較複雜的部份因此我們將其上下文向量的簡化成以下模式(其中c(t)上的e代表的是由Encoder生成的)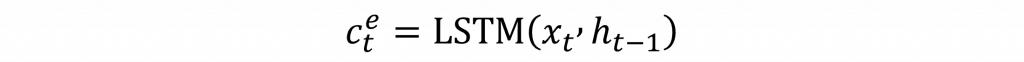
但是在Encoder階段,由於生成的文字與輸入的文字長度往往不相等,我們需要透過一個特殊Token <EOS>(End of Sequence)來讓Encoder學習到文字的結尾,並將這訊息傳遞給Decoder,使模型知道何時停止生成文字。如果沒有EOS標記,模型可能會無限生成詞彙,導致無法正確判斷何時該結束輸出序列。
不過在 Decoder 的生成過程中就有所不同了,我們會在第一步將 <SOS>(Start of Sequence)特殊標記作為第一個時序的輸入讓它產生對應的翻譯或相對應的文字目標,直到遇到 <EOS> 才停止生成。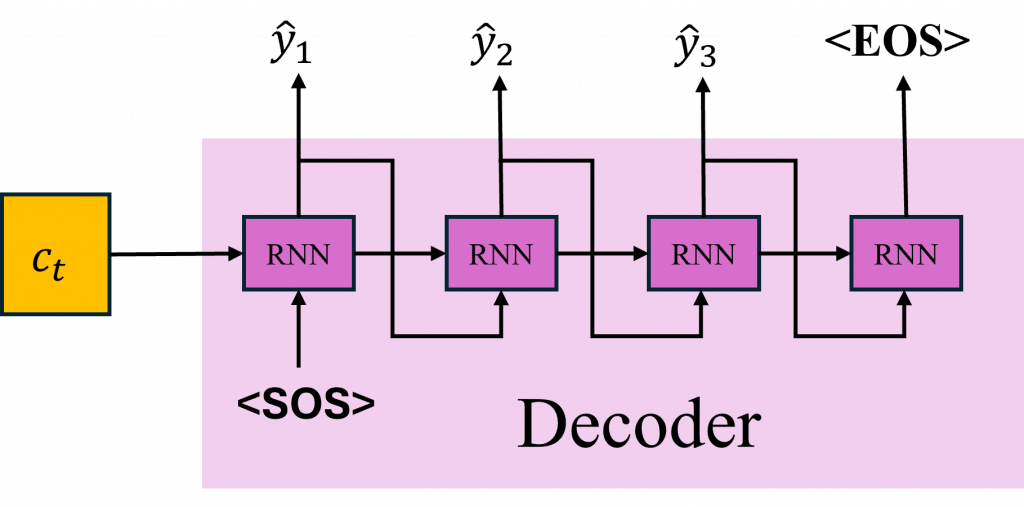
而觀察圖片中的 Decoder 架構,可以發現,它會將上一個生成的文字當作當前時序的輸入進行運算。因此我們必須先計算出每個 Decoder 的隱藏狀態中最有可能對應的文字機率,並將其轉換成對應的標記給模型進行運算。以上這段文字我們可以轉換成以下三個公式:
這三個公式你應該不陌生了。第一個是每一個隱藏狀態的輸出,而我們知道隱藏狀態的輸出需要通過全連接層的計算才能轉換為對應的維度以計算出機率。因此,第二個公式就是全連接層的公式,第三個則是softmax的公式,用來計算機率並轉換出最終生成的Token。
但是這樣的運算會發生問題,我們知道生成動作永遠是學習最困難的部分,因此在一開始模型肯定會生成錯誤的目標序列。這就導致當這個錯誤的目標序列被用作下一個時序的輸入時,生成的結果每出錯一個字,後續的文字也會跟著出錯。因此實際上我們會使用Teacher Forcing(教師強迫)技術來協助模型的訓練。
在Teacher Forcing這個方法中,其運作方式是在訓練階段使用真實目標序列的元素作為Decoder的輸入,而不是使用上一個時間步(上一個文字)的資料。也就是說不管每個生成出來的文字是什麼,我們輸入的都會是正確的序列給Decoder。這樣當Decoder在每一步單獨計算損失值時,模型就能夠更快地學習目標序列的結構和模式。
在今天的內容中,我們可以發現這些技術都是一步步地延伸而成的,而這些公式基本上可以從前面幾個章節中取得。這表明在深度學習領域中,基礎公式的重要性。在今日討論的Seq2Seq架構中,我們能發現其作法與DCGAN相似,非常簡單。但是,仔細想想這篇文章中有沒有什麼奇怪的地方,以及這個模型還有哪裡可以優化的。而在明天我將會告訴你這個模型的缺陷並告訴你改進的數學證明。

