在昨天我們介紹了DCGAN的原理,並且分享了一些訓練技巧。不過昨日的內容可能不夠詳盡,例如模型訓練過程中的各個步驟,如何調整鑑別器和生成器,並對其進行優化。這次我將透過拆解程式碼,詳細介紹如何使用DCGAN來生成MNIST風格的手寫數字圖片。我們將逐步說明程式碼中的重要部分,介紹生成器和鑑別器的設計、損失函數的計算以及模型訓練的具體流程。
在本次的內容中我們將繼續延續前面章節所提到的基礎設定,具體來說就是導入本次將會使用到的完整函式庫,並設置固定的亂數種子。這些步驟我們在前面章節中已經詳細講解過,因此在此不再重複過多敘述。而在本次的重點放在生成器與鑑別器的構建以及它們的訓練過程上,這部分內容至關重要因為它將決定整個生成對抗網絡模型的最終性能表現。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision as tv
from torch.utils.data import DataLoader
import numpy as np
import random
from tqdm import tqdm
from matplotlib import pyplot as plt
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_seed(0)
在這次的生成任務中我們依然選用經典的 MNIST 數據集來進行圖片生成操作。雖然這次的任務看似與我們之前在使用深度神經網路進行分類任務的程式碼相似,但有幾個關鍵點需要我們格外注意。首先這次的模型訓練屬於非監督式學習,也就是說我們並不會使用標籤來指導模型進行學習。因此不需要像監督式學習那樣通過驗證集來評估模型的性能。
而我們的主要目標是讓生成器和鑑別器在對抗過程中不斷優化,直到生成器能夠生成與真實數據分布極為相似的圖片,因此為了增加訓練數據量並提高模型的泛化能力,我們可以將訓練集和測試集進行合併,讓模型能夠接觸到更多樣的數據樣本,從而達到更好的生成效果。
transform = tv.transforms.Compose([
tv.transforms.ToTensor(),
tv.transforms.Normalize(mean=[0.5,], std=[0.5,])
])
trainset = tv.datasets.MNIST("MNIST/", train=True, transform=transform, download=True)
validset = tv.datasets.MNIST("MNIST/", train=False, transform=transform, download=True)
dataset = trainset + validset
train_loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=0, pin_memory=True)
昨日提到鑑別器的作用是將輸入的圖片分類為真實或偽造,因此他的輸出式屬於一種二分類的算法,最終輸出一個經過Sigmoid激活函數的值,表示該圖片是真實的概率。而在這裡我們也加入了昨日提到的BatchNorm2d並在每一層之中加入LeakyReLU激活函數來解決ReLU的死亡神經元問題。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.D = nn.Sequential(
# input is (1) x 28 x 28
nn.Conv2d(1, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
# state size. (64) x 14 x 14
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# state size. (128) x 7 x 7
nn.Conv2d(128, 256, 3, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# state size. (256) x 4 x 4
nn.Conv2d(256, 1, 4, 1, 0, bias=False),
# state size. (1) x 1 x 1
nn.Sigmoid()
)
def forward(self, x):
return self.D(x)
在鑑別器的設計中我們的方式基本上與傳統的卷積神經網路非常相似。通過逐層提取圖片的特徵,將特徵圖的通道數量逐漸增加,從而使模型能夠捕捉到圖片中越來越多的高級特徵。這個過程的核心是對圖片特徵的逐步縮小和濃縮,這就是卷積網路的典型特性隨著層數加深,圖片的空間維度會逐漸減小,而特徵通道的數量會逐步增多。
生成器的目標是將隨機噪聲(noize_dim)轉換成一張28x28的MNIST風格圖片。因此我們使用了卷積轉置層來進行上採樣,並且使用BatchNorm2d來穩定訓練過程。而最後一層之所以使用Tanh而不是Sigmoid而是tanh是因為我們需要將輸出範圍映射到[-1,1],對應數據集的標準化範圍。而在這裡我們假設輸入的noize_dim是一個(100, 1, 1)大小的隨機噪音資料
上採樣(Upsampling)是一種將低維度數據轉換為高維度數據的技術,通常應用在生成模型中,尤其是像生成對抗網絡中的生成器。例如本次生成器的任務是將一個小的隨機噪聲向量(比如大小為 (100, 1, 1) 的向量)轉換為與目標圖片大小相同的數據(比如 MNIST 圖片為 28x28 的大小)。為了實現這個過程,我們使用了卷積轉置層,這個層負責進行上採樣。
class Generator(nn.Module):
def __init__(self, noize_dim):
super(Generator, self).__init__()
self.G = nn.Sequential(
# input is (100) x 1 x 1
nn.ConvTranspose2d( noize_dim, 256, 4, 1, 0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# state size. (256) x 4 x 4
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# state size. (128) x 8 x 8
nn.ConvTranspose2d( 128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# state size. (64) x 16 x 16
nn.ConvTranspose2d( 64, 1, 4, 2, 3, bias=False),
# state size. (1) x 28 x 28
nn.Tanh()
)
def forward(self, x):
return self.G(x)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
noize_dim = 100
G = Generator(noize_dim).to(device)
D = Discriminator().to(device)
criterion = nn.BCELoss()
G_optimizer = optim.Adam(G.parameters(), lr = 1e-3)
D_optimizer = optim.Adam(D.parameters(), lr = 1e-3)
在生成對抗網絡的訓練過程中,由於生成器和鑑別器是兩個獨立的模型,它們各自的權重更新過程需要分開進行,因此我們需要為生成器和鑑別器分別定義兩個優化器。這樣可以靈活地對每個模型設置不同的學習率,從而達到更好的效果。
通常來說生成器和鑑別器的學習速率不同。因為生成器的目標是學會欺騙鑑別器,這是一個較為困難的任務,因此生成器可能需要較高的學習率來加速其學習過程,而鑑別器則需要更加穩定的更新,因此學習率可以設置得稍微低一點。
該模型的訓練方式比較特殊,我們需要分別訓練鑑別器與生成器而在鑑別器的部分我的就會顯得比較值觀,還記得昨日的損失公式嗎?
我們要讓鑑別器最大會真實圖像的機率,並減少生成器的圖像機率,因此對於鑑別器來說,我們需要先計算一次鑑別器對於真實圖像的損失值,在計算一次由生成器計算出來的損失值,最後將兩者加總已計算梯度。
def D_train():
D_optimizer.zero_grad()
x_real = x.to(device)
y_real = torch.ones(x.size(0)).to(device)
x_real_predict = D(x_real)
D_real_loss = criterion(x_real_predict.view(-1), y_real)
D_real_loss.backward()
noise = torch.tensor(torch.randn(x.size(0), noize_dim, 1, 1)).to(device)
y_fake = torch.zeros(x.size(0)).to(device)
x_fake = G(noise)
x_fake_predict = D(x_fake)
D_fake_loss = criterion(x_fake_predict.view(-1), y_fake)
D_fake_loss.backward()
D_total_loss = D_real_loss + D_fake_loss
D_optimizer.step()
return D_total_loss.item()
生成器的訓練則是讓鑑別器將生成的假圖片判定為真實圖片,因此我們將生成的假圖片輸入鑑別器,並將其結果與標籤(即1)進行比較,計算生成器的損失並更新其參數。生成器的部分只需要一個標籤,我們只需要將鑑別器所判定的標籤與實際標籤進行對比即可。在這裡我們要注意,由於我們要求生成器生成出來的是實際標籤,因此我們使用torch.ones來生成一個全為真實標籤的張量。
def G_train():
G_optimizer.zero_grad()
noise = torch.tensor(torch.randn(x.size(0), noize_dim, 1, 1)).to(device)
y_target = torch.ones(x.size(0)).to(device)
x_fake = G(noise)
y_fake = D(x_fake)
G_loss = criterion(y_fake.view(-1), y_target)
G_loss.backward()
G_optimizer.step()
return G_loss.item()
當我們定義好優化器後,只需將 Trainer 中的訓練部分移動出來即可。在訓練時,我們應使用 D_train() 和 G_train() 這兩個函數,而不是 train() 和 valid()。
epochs = 1000
early_stopping = 100
stop_cnt = 0
show_loss = True
best_loss = float('inf')
loss_record = {'Discriminator': [], 'Generator': []}
for epoch in range(epochs):
train_pbar = tqdm(train_loader, position=0, leave=True)
D_record, G_record = [], []
for idx, (x, _) in enumerate(train_pbar):
D_loss = D_train()
G_loss = G_train()
D_record.append(D_loss)
G_record.append(G_loss)
train_pbar.set_description(f'Train Epoch {epoch}')
train_pbar.set_postfix({'D_loss': f'{D_loss:.3f}', 'G_loss': f'{G_loss:.3f}'})
D_loss = sum(D_record) / len(D_record)
G_loss = sum(G_record) / len(G_record)
loss_record['Discriminator'].append(D_loss)
loss_record['Generator'].append(G_loss)
if G_loss < best_loss:
best_loss = G_loss
torch.save(D.state_dict(), 'D_model.ckpt')
torch.save(G.state_dict(), 'G_model.ckpt')
print(f'Saving Model With Loss {best_loss:.5f}')
stop_cnt = 0
else:
stop_cnt += 1
if stop_cnt == early_stopping:
output = "Model can't improve, stop training"
print('-' * (len(output) + 2))
print(f'|{output}|')
print('-' * (len(output) + 2))
break
print(f'D_Loss: {D_loss:.5f} G_Loss: {G_loss:.5f}', end='| ')
print(f'Best Loss: {best_loss:.5f}', end='\n\n')
# ----- 輸出 -----
Train Epoch 26: 100%|██████████| 469/469 [00:27<00:00, 17.18it/s, D_loss=0.531, G_loss=1.482]
Saving Model With Loss 2.92682
D_Loss: 0.43517 G_Loss: 2.92682| Best Loss: 2.92682
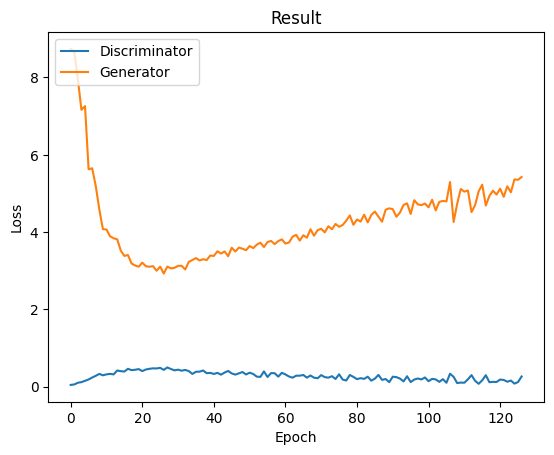
在整個訓練過程中,我們可以看到生成器的損失值一直居高不下,而鑑別器的損失值則持續下降。這顯然不是理想的狀況,不過在生成式對抗網路中非常常見。我們只能通過一些正規化方式或調整訓練策略來加強生成器的效果。例如,我們可以加入Warmup並延長鑑別器的暖身時間,以便生成器先行取得一定的優勢,或者改變訓練方式,讓生成器多訓練幾次再訓練鑑別器。這些措施都能顯著改善模型的訓練結果。
而在模型上我們只需要調用訓練好的生成器並給予一個雜訊即可完成模型生成的工作,而不需要引入鑑別器,在鑑別器的部分單純就是為了讓生成器與他對抗已達成非監督式學習的概念。不過我們可以看到對於這種簡單的圖形來說,損失值就算達到了2.9,其生成效果也是非常良好的,而在這裡我們記得由於我們輸入給模型的資料是(batch_size, noize_dim, 1, 1),因此我們也可以隨意地更改其batch_size大小讓能一次生成多筆資料。
import cv2
G = Generator(noize_dim)
G.load_state_dict(torch.load('G_model.ckpt'))
G.eval().to(device)
noize = torch.tensor(torch.randn(1, noize_dim, 1, 1)).to(device)
fake = G(noize)
fake = np.array(fake.detach().cpu())
for cnt, img in enumerate(fake):
npimg = (img/2+0.5)*255
npimg = np.transpose(npimg, (1, 2, 0))
#cv2.imwrite(f'fake_image/fake_{cnt}.png', npimg.astype('uint8'))
plt.imshow(npimg)
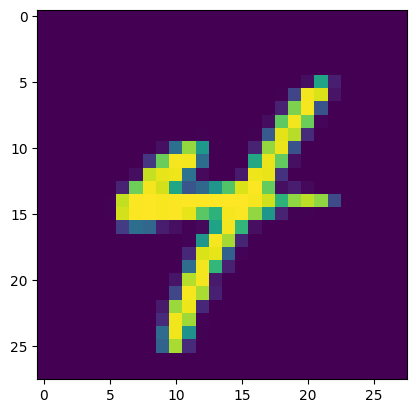
這次我們使用DCGAN來生成MNIST手寫數字圖片,並透過拆解程式碼一步步說明了數據集、生成器和鑑別器的建立、損失函數計算,以及模型的訓練流程。而我們可以觀察到雖然在整個訓練過程中生成器的損失可能持續較高,但這在GAN訓練中是常見的現象,因此在這類的模型中我們要調適兩個模型之間的對抗強度是有一定的挑戰性的,不過我們可以看到就算損失值很高我們依然能生成效果良好的圖片,而這次的程式中我們也可以得知不是所有資料都需要標註的,我們也可以透過非監督式學習的方式來達成模型生成的目標。

