在上一篇文章中,我簡單介紹了如何使用 Spring AI 的 Chat Mode,並建立了兩組 API 端點。其中一個是用於基本的聊天模型對話,另一個則是以串流的方式回傳回應內容。在實際應用中,我們傾向使用串流的方式,讓回應內容逐步回傳給使用者,藉此提升使用者體驗。
今天,我計畫新增 Embedding Model 和 Vector Store,為未來實作 RAG(Retrieval-Augmented Generation)應用奠定基礎。
設定 Embedding Model 非常簡單,因為我們已經完成 OpenAI 的連線設定,包含 API 金鑰的設置。接下來只需要指定要使用的 Embedding Model 即可。在這裡,我選擇了 text-embedding-3-small,這個模型在繁體中文的表現相當出色,而且性價比很高。
想進一步了解繁體中文 Embedding 的評測,可以參考 ihower 的一篇詳細文章:
在向量資料庫方面,我選擇了 Qdrant。主要原因有兩個:
使用 Qdrant 的步驟如下:
完成以上步驟後,理論上即可於 Spring 專案中開始使用 Qdrant。
為了展示 Embedding 的效果,我建立了一個簡單的 API 端點 /ai/embedding。在 Spring Framework 中,我們可以利用 @Autowired 讓框架自動完成依賴注入(Dependency Injection),如此一來就不需要手動實例化 Embedding Model 或 Vector Store,相關參數都已在 Properties 中設定完畢。
對於初次接觸 Spring Framework 的開發者來說,這樣的做法或許會感到有些陌生,但熟悉之後就會發現它相當便利。透過框架的依賴注入功能,我們不再需要煩惱建構子的設計以及物件之間的依賴關係,這正是 Spring Framework 強大的優勢所在。
以下是 API 的程式碼範例:
@GetMapping("/ai/embedding")
fun embed(
@RequestParam(
value = "message",
defaultValue = "Tell me a joke"
) message: String
): Map<*, *> {
val embeddingResponse: EmbeddingResponse = embeddingModel.embedForResponse(listOf(message))
return java.util.Map.of("embedding", embeddingResponse)
}
這個 API 只做一件事:接收一個名為 message 的請求參數,預設值為 "Tell me a joke"。函式中,將 message 轉換為單元素的 List,然後使用 Embedding Model 的 embedForResponse 方法進行嵌入,最終回傳包含嵌入結果的 Map。
如果您想深入了解 Spring Framework 中 @Autowired 如何將 Spring Beans 注入到其他 Beans,可以使用 IntelliJ IDEA 的 Spring Tools 生成 Bean Graph。這個工具可以協助我們分析應用程式中的依賴關係,生成的 Bean Graph 也可以匯出成圖檔,方便理解每個物件的相依性。我強烈推薦這個小工具給大家使用。
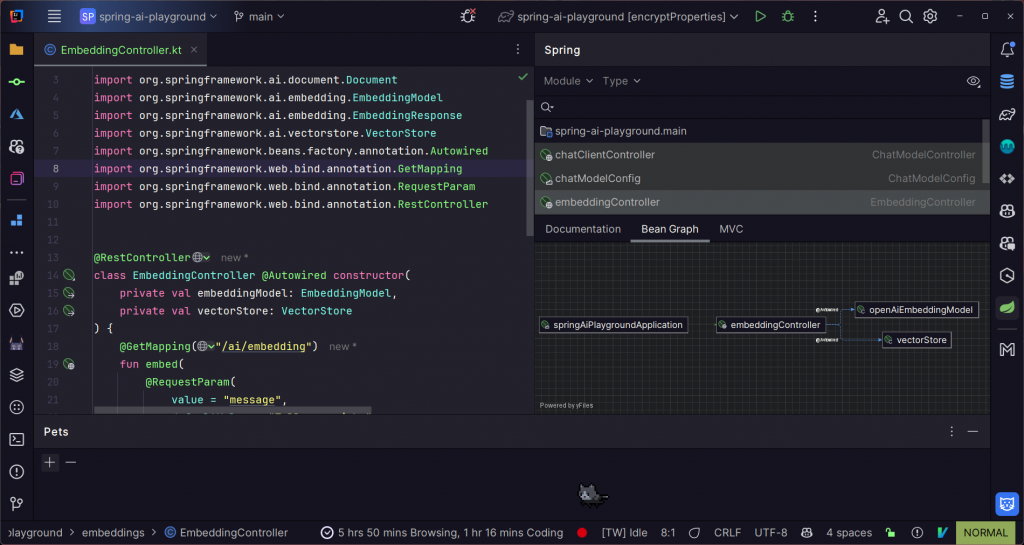

原本我還建立了一個 API endpoint,預期將 Embedding 的結果存入 Qdrant 向量資料庫。然而,今天在使用時遇到了一些小問題,花費較多時間仍然無法順利解決。因此,這篇文章無法展示如何將 Embedding 結果存入 Vector Store。這部分的工作就留待明天處理,希望屆時能夠順利解決。
雖然今天的進度沒有達到預期目標,但至少我們分享了如何在 Spring AI 中設定 Embedding Model,以及如何利用 IntelliJ IDEA 的 Bean Graph 功能來理解 Spring Beans 的相依性。相信這些技巧能幫助大家提升開發效率,更深入地理解 Spring 框架的運作原理。
感謝各位的閱讀,我們明天再會!


 iThome鐵人賽
iThome鐵人賽