訓練模型的過程,雖然會顯示每個週期的評估指標數值,也可以使用 CSVLogger 保存下來查看這些數值,但如果將數值轉換成圖表,是不是更好去看趨勢,更加一目了然呢?今天要來介紹如何繪製圖表,以及補充一些可以監控模型訓練的視覺化工具。(除了視覺化,也包含其他好用的功能!)
Matplotlib 為 Python 的一個視覺化工具庫,可以用來繪製各式各樣的統計圖表,類似於 MATLAB,可以和 NumPy 與 Pandas 這 2 種數據處理庫一起使用。提供幾個繪製圖表的例子:
繪製曲線圖:
import matplotlib.pyplot as plt
import numpy as np
a = np.linspace(0,10,100)
b = np.exp(-a)
plt.plot(a,b)
plt.show()
繪製直方圖:
import matplotlib.pyplot as plt
from numpy.random import normal,rand
x = normal(size=1000)
plt.hist(x,bins=50)
plt.show()
先回顧整個模型的程式碼:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
from tensorflow.keras import layers, regularizers
from tensorflow.keras.applications import VGG16
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, CSVLogger
# 載入資料集
trpath = "./Kaggle/data/"
trdata = ImageDataGenerator(validation_split=0.2)
traindata = trdata.flow_from_directory(directory=trpath,
target_size=(256,256),
shuffle=True,
subset='training')
valdata = trdata.flow_from_directory(directory=trpath,
target_size=(256,256),
shuffle=True,
subset='validation')
# 設定 steps_per_epoch 和 validation_steps
spe = traindata.samples // traindata.batch_size # steps_per_epoch
vs = valdata.samples // traindata.batch_size # validation_steps
# 定義資料增強層
data_augmentation = tf.keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
# 建立模型
inputs = tf.keras.Input(shape=(256, 256, 3))
base_model = data_augmentation(inputs)
base_model = VGG16(include_top=False, weights='imagenet', input_tensor=base_model)
x = base_model.output
x = layers.Flatten()(x)
x = layers.Dense(4096, activation="relu", kernel_regularizer=regularizers.l2(0.01))(x)
x = layers.Dense(4096, activation="relu", kernel_regularizer=regularizers.l2(0.01))(x)
outputs = layers.Dense(5, activation="softmax")(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
# 凍結層
for layer in base_model.layers:
layer.trainable = False
# 編譯模型
opt = Adam(learning_rate=0.0001)
model.compile(optimizer=opt,
loss="categorical_crossentropy",
metrics=["accuracy"]
)
checkpoint = ModelCheckpoint("model.h5",
monitor="val_accuracy",
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='max',
period=1)
early = EarlyStopping(monitor="val_accuracy",
min_delta=0,
patience=20,
verbose=1,
mode="max")
csv_logger = CSVLogger("training.csv", append=True)
hist = model.fit_generator(steps_per_epoch=spe,
generator=traindata,
validation_data=valdata,
validation_steps=vs,
epochs=100,
callbacks=[checkpoint, early, csv_logger])
繪製訓練結果,在一張圖的左邊繪製模型訓練和驗證的準確度,右邊繪製模型訓練和驗證的損失值:
import matplotlib.pyplot as plt
plt.figure(figsize=(9, 4))
plt.subplot(121)
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title("Model Accuracy")
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(["Accuracy","Validation Accuracy"])
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title("Model Loss")
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.legend(["Loss","Validation Loss"])
plt.show()
plt.savefig("plot.png")
說明:
figure 為繪製圖表的視窗,使用 figsize 設定圖表大小,單位為英寸。subplot 為子圖,要繪製多張圖在一張大圖中可以使用,數字 121 表示圖共有 1 列(橫) 2 行(直),這張圖要畫在第 1 個位置(左邊數來)。plot 可以繪製數據,這裡使用 fit_generator() 的物件 history,可以將這些訓練模型的評估指標的歷史記錄調出來,使用 accuracy 表示取得訓練準確度的數據(依此類推)。title 為圖表的標題。xlabel 和 ylabel 表示 x 軸的標題和 y 軸的標題,x 軸這裡都是週期。legend 表示圖例。show 表示顯示圖表。savefig 可以保存圖表檔案,副檔名可以使用其他圖檔類型。繪製結果: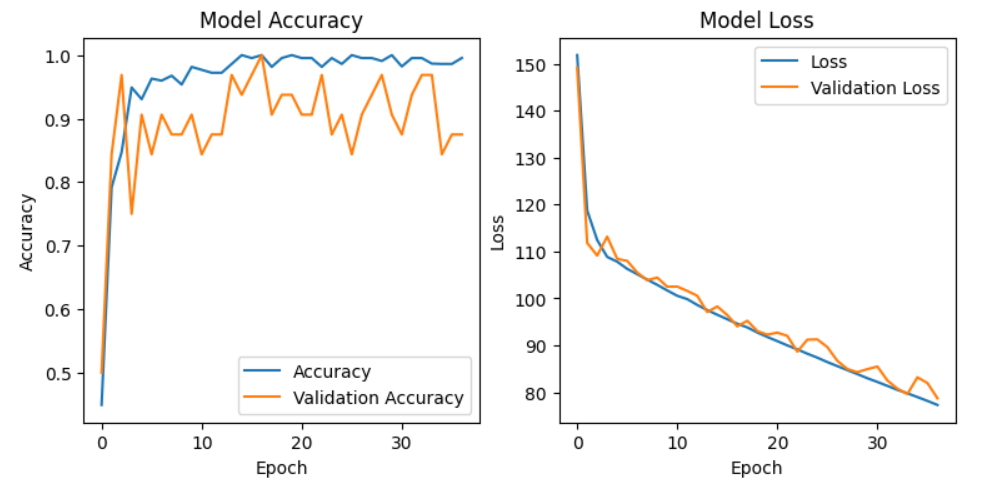
這樣就可以看看模型訓練的狀況啦(然後再做調整)。
接下來補充其他監控模型訓練的可視化工具,雖然 Matplotlib 也可以繪製動態的圖表,如使用 plt.pause() 或是 FuncAnimation,但也有很多工具可以使用,查看更多不同的關於模型的資訊記錄,甚至可以進行比較。
TensorBoard 為 TensorFlow 內建的一個模型監控工具,以瀏覽器形式來查看,除了數據資料之外,也可以查看模型的架構。TensorBoard 也是在 Callbacks 模組中。
使用方法:
from tensorflow.keras.callbacks import TensorBoard
tensorboard = TensorBoard(log_dir="日誌儲存路徑")
也是記得在 fit_generator() 或 fit() 加入 callbacks,裡面輸入設定的變數名稱:
hist = model.fit_generator(steps_per_epoch=spe,
generator=traindata,
validation_data=valdata,
validation_steps=vs,
epochs=100,
callbacks=[tensorboard])
如果是使用 Spyder IDE,可以開啟 Anaconda Prompt 進入當前開發環境,輸入下列指令:
tensorboard --logdir 完整日誌路徑
開啟網頁就可以查看相關資訊: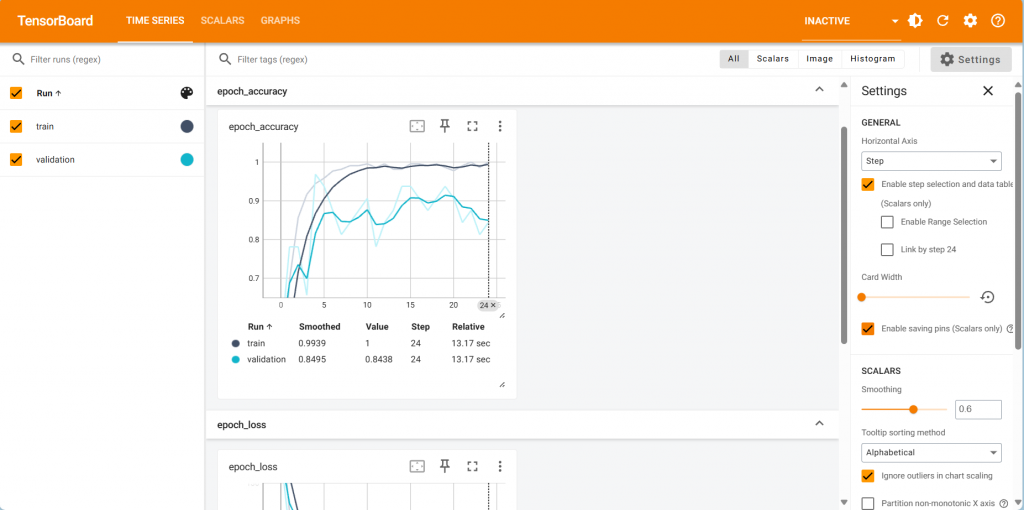
Weights and Biases(Wandb)為一款可以監控機器學習相關實驗的數據,提供可視化結果,以及團隊協作功能,除了可以查看訓練時的評估指標外,還有硬體設備的狀態也有記錄下來。
使用方法(以使用 Anaconda 為例):
pip install wandb 安裝套件wandb login,輸入自己的 API Key 登入(API Key 可進入授權頁面,或到 User settings 往下拉到 Danger zone 取得)import wandb
from wandb.integration.keras import WandbCallback
wandb.init(
# project_name 可替換自己的專案名稱,可以先建立,或是直接指定,到時候會直接創好
project="project_name",
# 記錄模型配置,方便日後管理,內容以本系列實作為例
config={
"learning_rate": 0.0001,
"architecture": "VGG16",
"dataset": "Bears Dataset",
"epochs": 100,
}
)
### 省略模型程式碼 ###
# callbacks 記得加入 WandbCallback()
hist = model.fit_generator(steps_per_epoch=spe,
generator=traindata,
validation_data=valdata,
validation_steps=vs,
epochs=100,
callbacks=[WandbCallback()])
# 設定想要儲存的評估指標
wandb.log({"accuracy": hist.history['accuracy'], "loss": hist.history['loss'], "val_accuracy": hist.history['val_accuracy'], "val_loss": hist.history['val_loss']})
# 最後記得加上 wandb.finish() 表示結束
wandb.finish()
python your_code.py(your_code 替換成自己的檔案名稱)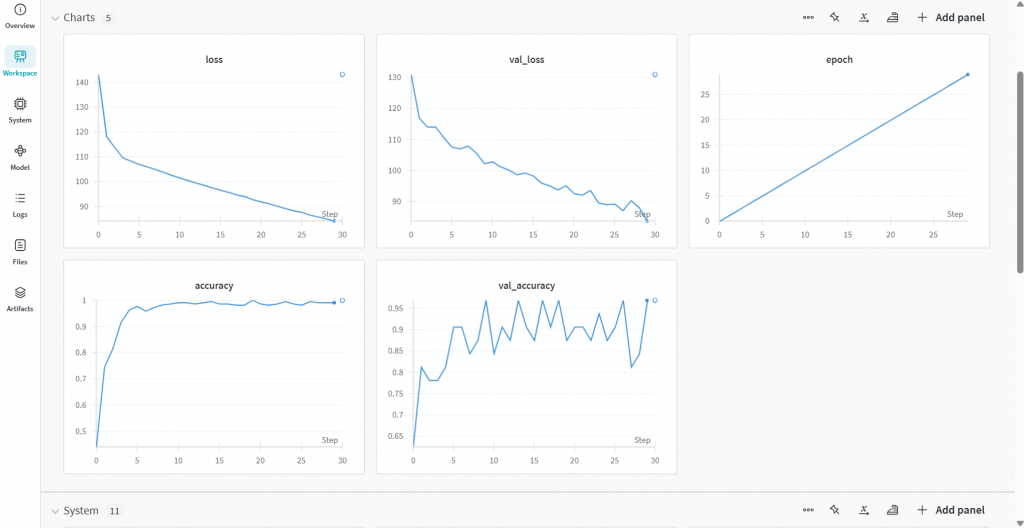
MLflow 除了可以讓訓練結果可視化之外,還有提供模型部署的功能,今天主要介紹可視化的功能。
使用方法:
pip install mlflow 安裝套件import mlflow
import mlflow.tensorflow
mlflow.start_run()
### 省略模型程式碼 ###
# 手動記錄參數用法,寫在編譯前
mlflow.log_param("learning_rate", 0.0001)
mlflow.log_param("epochs", 100)
mlflow.log_param("batch_size", traindata.batch_size)
# 自動記錄重要參數用法,寫在訓練前
mlflow.tensorflow.autolog()
mlflow.end_run()
python your_code.py(your_code 替換成自己的檔案名稱)mlflow ui,開啟顯示的網址,進入專案,點選「Model metrics」: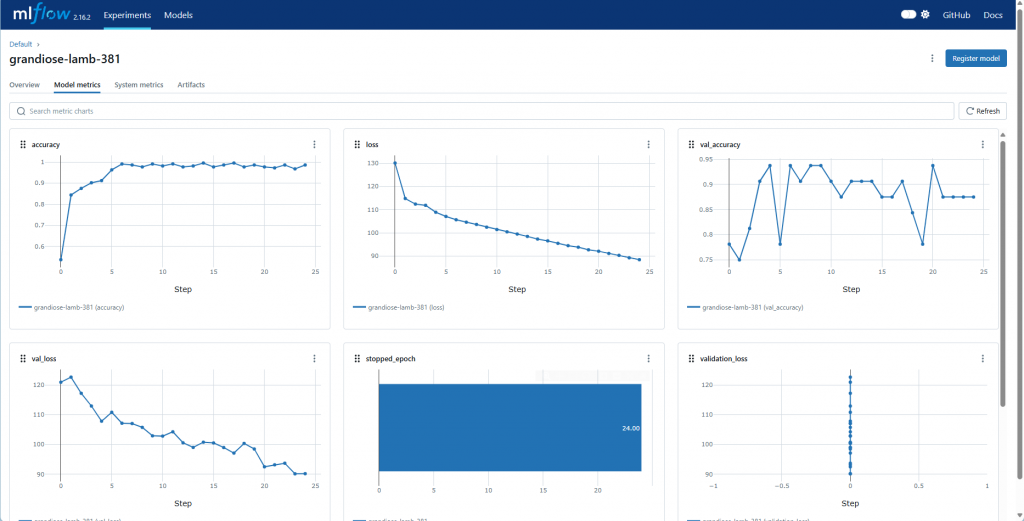
本來只想到要介紹 Matplotlib 的,突然想到用過的一些工具,就來介紹給大家啦
明天要拿訓練好的模型來進行推論囉!


 iThome鐵人賽
iThome鐵人賽