在今天的內容中,我們將使用 ManyThings 這個網站中的中英文資料,來進行文字翻譯任務的訓練。在這次內容中,我們會分別使用兩個 Tokenizer 給予 Encoder 與 Decoder 進行分析與訓練,我們會使用 BERT 的 Tokenizer 來進行處理。在這裡需要注意的是,BERT 的 Tokenizer 在使用時會產生 [CLS] 與 [SEP] 這兩個特殊 Token,這剛好可以作為我們模型中的 SOS 與 EOS Token。現在讓我們直接來看程式碼的部分。
由於ManyThings這個網站沒有繁體中文資料,我們需要先使用OpenCC這個函式庫將其進行簡體轉繁體操作。這也是解決繁體中文語料庫不足的一種方法。去年國科會開發的LLaMA繁體中文版出現大量簡體資訊,就是因為直接使用了簡體中文資料而未刪除特定國家的資訊所導致的問題。然而在我們的情況下,因為只需要簡單的資料處理,所以直接進行簡轉繁即可。
與我們在IMDB時的做法一樣,我習慣將資料先轉換成csv格式。在該資料集中,每個英文和中文之間都是通過\t這個特殊符號分割。主要有三個欄位,第一個欄位是英文,第二個欄位是中文,第三個欄位是相關資訊。因此,我們只需將資料分割後取得前兩個欄位,再將其儲存為csv文件即可。
import pandas as pd
from opencc import OpenCC
def convert_news_to_csv(data_path, csv_file_path):
cc = OpenCC('s2tw') # 簡體轉繁體
with open(data_path, 'r', encoding = "utf-8") as f:
lines = f.read().split('\n')
english, chinese = [], []
for line in lines:
if line:
en, cn, _, = line.split('\t') # 資料是\t分割的
english.append(en)
chinese.append(cc.convert(cn))
df = pd.DataFrame({'chinese':chinese, 'english':english})
df.to_csv(csv_file_path)
convert_news_to_csv('cmn.txt', 'translate.csv')
df = pd.read_csv('translate.csv')
input_texts = df['chinese'].values
target_texts = df['english'].values
在這一步中大多數的操作都與先前相同,但唯一不同的地方在於collate_fn所需填充的內容各不相同。因此在這裡我們特別進行講解。首先輸入給Encoder的中文資料不需要有sos Token,因此我們需要使用input_ids[:, 1:]這種寫法,其中**:,的寫法是取出第二個維度的資料**。由於我們當前的資料維度是(batch_size, seq_len),因此我們需要取出seq_len的維度並移除第1個[CLS] Token,以達到移除sos Token的功能,而Deocder則不需要進行改動。
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from transformers import AutoTokenizer
class TranslateDataset(Dataset):
def __init__(self, x, y, src_tokenizer, tgt_tokenizer):
self.x = x
self.y = y
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
def collate_fn(self, batch):
batch_x, batch_y = zip(*batch)
inputs = self.src_tokenizer(batch_x, max_length=256, truncation=True, padding="longest", return_tensors='pt').input_ids[:, 1:]
targets = self.tgt_tokenizer(batch_y, max_length=256, truncation=True, padding="longest", return_tensors='pt').input_ids
return {'src_input_ids':inputs, 'tgt_input_ids': targets}
x_train, x_valid, y_train, y_valid = train_test_split(input_texts, target_texts, train_size=0.8, random_state=46, shuffle=True)
src_tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
tgt_tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
trainset = TranslateDataset(x_train, y_train, src_tokenizer, tgt_tokenizer)
validset = TranslateDataset(x_valid, y_valid, src_tokenizer, tgt_tokenizer)
train_loader = DataLoader(trainset, batch_size = 64, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=trainset.collate_fn)
valid_loader = DataLoader(validset, batch_size = 64, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=validset.collate_fn)
在Encoder模型中與我們在LSTM章節中所建立的方式完全相同,唯一的差異在於我們不需要經過全連接層的運算,並且需要使用到output這一個參數,其原因是**output包含者整個模型在運算時的隱藏狀態,因此我們在計算Attention時會需要使用其變數,而hidden則會做為Decoder的初始隱狀態。**
import torch.nn as nn
class EncoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size, padding_idx):
super(EncoderGRU, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=padding_idx)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(0.1)
def forward(self, token_ids):
embedded = self.dropout(self.embedding(token_ids))
#embedded: (batch_size, time_step, emb_dim)
output, hidden = self.gru(embedded)
# output: (batch_size, time_step, hidden_size * 2)
# hidden: (2, batch_size, hidden_size)
return output, hidden
在Attention層時,我們需要仔細考慮輸入的資料格式。首先,我們要了解Attention的輸出是一個單一向量,即上下文向量。這個上下文向量會輸入給當前時序的Decoder。因此,我們的decoder_hidden其實是一個(batch_size, 1, hidden)的輸入,而Encoder則是(Batch_size, seq_len, hidden)。通過Bahdanau Attention的公式運算後,這些輸入會被轉換成相同大小,因此可以順利加總起來。接下來的步驟就是將各類運算轉換為上下文向量。我會把每層輸出的註解都打在程式碼中,以便你理解每個過程發生了什麼事情。
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.encoder_projection = nn.Linear(hidden_size, hidden_size)
self.decoder_projection = nn.Linear(hidden_size, hidden_size)
self.attention_v = nn.Linear(hidden_size, 1)
self.tanh = nn.Tanh()
self.softmax = nn.Softmax(dim=-1)
def forward(self, encoder_hidden, decoder_hidden):
energy = self.tanh(self.encoder_projection(encoder_hidden) + self.decoder_projection(decoder_hidden))
#energy: (batch_size, time_step, hidden_size)
scores = self.attention_v(energy)
#scores: (batch_size, time_step, 1)
scores = scores.squeeze(2).unsqueeze(1)
#scores: (batch_size, 1, time_step)
attention_weights = self.softmax(scores)
# attention_weights (batch_size, 1, time_step)
context_vector = torch.bmm(attention_weights, decoder_hidden)
#context_vector: (batch_size, 1, hidden_size)
return context_vector
在Decoder部分,我們需要將Embedding的資訊與經過Attention計算後的上下文向量結合,然後將這些資訊傳遞到輸出層。在輸出層,信息會經過全連接層的轉換,最終生成適合進行softmax運算的向量。這樣模型在推理時能夠計算出下一個時間步的Token。
需要經過
softmax運算的資料必須轉換為維度為 (batch_size, 1, seq_len) 的格式。因此,無論是在Attention機制中還是Decoder中,我們都會看到為了滿足此需求而進行的維度轉換操作。
class DecoderGRU(nn.Module):
def __init__(self, attention, hidden_size, output_size, padding_idx):
super(DecoderGRU, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size, padding_idx=padding_idx)
self.gru = nn.GRU(2 * hidden_size, hidden_size, batch_first=True)
self.output_projection = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(0.1)
self.attention = attention
def forward(self, encoder_outputs, decoder_hidden, decoder_input_ids):
# decoder_input_ids: (batch_size, 1)
embedded = self.dropout(self.embedding(decoder_input_ids))
# embedded: (1, batch_size, emb_dim)
decoder_state = decoder_hidden.permute(1, 0, 2)
#decoder_state (batch_size, 1, emb_dim)
context = self.attention(decoder_state, encoder_outputs)
# (batch_size, 1, hidden_size)
input_gru = torch.cat((embedded, context), dim=-1)
# input_gru (batch_size, 1, hidden_size + emb_dim)
output, decoder_hidden = self.gru(input_gru, decoder_hidden)
# output: (batch_size, time_step, hidden_size)
# decoder_hidden: (1, batch_size, hidden_size)
decoder_output = self.output_projection(output)
# decoder_output: (batch_size, 1, output_size)
return decoder_output, decoder_hidden
這次的模型定義較為特殊。在理解具體模型之前,我們先了解整體的運作流程,如此可以幫助我們更好地理解接下來的內容。首先我們會通過Encoder模型計算當前批量的整體隱藏狀態。接著,建立一個初始給予Decoder的SOS Token decoder_next_input,並將Encoder最後的隱藏狀態傳入Decoder進行運算。
接下來,我們使用for迴圈,將真實的目標序列作為下一個decoder_next_input,並繼續交給模型生成文字(即Teacher Forcing)。同時,我們會記錄每個序列的生成結果,以便計算正確的損失值。
class Attentionseq2seq(nn.Module):
def __init__(self, encoder, decoder, padding_idx):
super(Attentionseq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.criterion = nn.NLLLoss(ignore_index=padding_idx)
self.logsoftmax = nn.LogSoftmax(dim=-1)
def forward(self, src_input_ids, tgt_input_ids):
input_ids = src_input_ids
targets = tgt_input_ids
# Encoder
encoder_outputs, decoder_hidden = self.encoder(input_ids)
# encoder_outputs: (batch_size, time_step, hidden_size)
# decoder_hidden: (1, batch_size, hidden_size)
decoder_next_input = torch.empty(targets.shape[0], 1, dtype=torch.long).fill_(101).to(input_ids.device.type) # 加入CLS token
# decoder_next_input: (batch_size, 1)
# Decoder
decoder_outputs = []
for i in range(targets.shape[1]):
decoder_next_input, decoder_hidden = self.decoder(encoder_outputs, decoder_hidden, decoder_next_input)
# decoder_next_input: (batch_size, 1, hidden_size)
# decoder_hidden: (1, batch_size, hidden_size)
decoder_outputs.append(decoder_next_input) # 儲存當前時序的文字分布狀態
decoder_next_input = targets[:, i].unsqueeze(1) # 取出下一個對應的文字進行生成
# decoder_next_input: (batch_size, 1)
decoder_outputs = torch.cat(decoder_outputs, dim=1) # 完整的Decoder隱狀態輸出
# decoder_outputs: (batch_size, time_step, output_dim)
decoder_outputs = self.logsoftmax(decoder_outputs) # 計算個文字機率
# decoder_outputs: (batch_size, time_step, output_dim)
# 計算損失值
loss = self.criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)), # (batch_size * time_step, output_dim)
targets.view(-1) # (batch_size * time_step)
)
return loss, decoder_outputs
我們的生成方式有所不同,因為沒有目標序列,所以只能依賴 SOS Token 來進行生成。生成過程的邏輯是首先通過 Encoder 進行計算,接著直接使用 SOS Token 作為起始輸入開始生成,並將每次生成的結果作為下一次的輸入序列,持續進行直到生成 EOS Token 為止生成才會結束。
def generate(self, input_ids, sos_token=101, eos_token=102, max_len=50):
with torch.no_grad():
encoder_outputs, decoder_hidden = self.encoder(input_ids)
decoder_outputs = []
decoder_next_input = torch.empty(1, 1, dtype=torch.long).fill_(sos_token).to(input_ids.device.type)
for _ in range(max_len):
decoder_next_input, decoder_hidden = self.decoder(encoder_outputs, decoder_hidden, decoder_next_input)
decoder_outputs.append(decoder_next_input)
_, top_token_index = decoder_next_input.topk(1)
if top_token_index == eos_token:
break
decoder_next_input = top_token_index.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = self.logsoftmax(decoder_outputs)
_, generated_ids = decoder_outputs.topk(1)
return generated_ids.squeeze()
在訓練模型時我們可以為 Encoder 和 Decoder 分別使用不同的優化器。然而需要注意的是,Encoder、Attention 和 Decoder 的 hidden_size 必須保持相同大小,否則可能會導致錯誤。
import torch.optim as optim
from trainer import Trainer
# 主程式部分
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
hidden_size = 768
encoder = EncoderGRU(
vocab_size=len(src_tokenizer),
hidden_size=hidden_size,
padding_idx=src_tokenizer.pad_token_id
)
decoder = DecoderGRU(
attention = BahdanauAttention(hidden_size=hidden_size),
hidden_size=hidden_size,
output_size=len(tgt_tokenizer),
padding_idx=tgt_tokenizer.pad_token_id
)
model = Attentionseq2seq(
encoder = encoder,
decoder = decoder,
padding_idx = tgt_tokenizer.pad_token_id
).to(device)
optimizer_e = optim.Adam(encoder.parameters(), lr=1e-4)
optimizer_d = optim.Adam(decoder.parameters(), lr=1e-4)
trainer = Trainer(
epochs=30,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=[optimizer_e, optimizer_d],
early_stopping=3
)
trainer.train()
# ----- 輸出 -----
Train Epoch 21: 100%|██████████| 374/374 [00:23<00:00, 16.02it/s, loss=0.589]
Valid Epoch 21: 100%|██████████| 94/94 [00:01<00:00, 51.56it/s, loss=1.494]
Saving Model With Loss 1.84741
Train Loss: 0.53640| Valid Loss: 1.84741| Best Loss: 1.84741
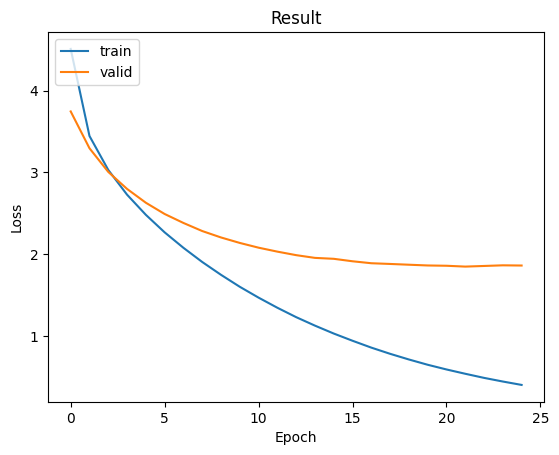
我們可以觀察到,模型的訓練損失雖然持續下降,但驗證損失卻沒有明顯上升,這表明模型已經達到了優化的瓶頸。由於驗證損失已經收斂,且尚未出現過擬合的情況,這時我們可以採取進一步的措施來提升模型性能,例如引入最佳化技巧或擴充資料集,以促進模型的進一步改善。
最後我們使用驗證數據生成文字結果。在這過程中我們需要將 SOS token 移除,因為模型的輸入是在 Encoder 處理後再傳遞給 Decoder,而 Decoder 的 SOS token 已在 generate 函數中自動定義。因此在生成短語時儘管偶爾會偏離原意,但整體的生成效果仍然不錯,而這種偏離主要是由於訓練數據不足,如果我們能夠擁有更多的數據,生成效果將會有明顯的提升。
model.load_state_dict(torch.load('model.ckpt'))
model.eval()
for idx in range(3):
input_ids = src_tokenizer(x_valid[idx], max_length=256, truncation=True, padding="longest", return_tensors='pt').to(device).input_ids[:, 1:]
generated_ids = model.generate(input_ids, max_len=20)
print('\n輸入文字:', x_valid[idx])
print('目標文字:', y_valid[idx])
print('翻譯文字:', tgt_tokenizer.decode(generated_ids))
# ----- 輸出 -----
輸入文字: 他要愛。
目標文字: He wants affection.
翻譯文字: [CLS] he's love. [SEP]
輸入文字: 別再讓我做那事了。
目標文字: Don't make me do that again.
翻譯文字: [CLS] don't do that again. [SEP]
輸入文字: 我們愛湯姆。
目標文字: We love Tom.
翻譯文字: [CLS] we love tom. [SEP]
在今天的內容中,我們發現程式碼非常複雜,因此我們在註解中詳細說明了每個維度的輸出。在文章的主要部分,我們解釋了為何在程式設計中需要這樣處理。不過由於內容很複雜,因此你可能還是需要多看幾次程式碼才能了解這些程式的內容及其相關的數學公式。

