昨天我們學到的Seq2Seq架構中,其實有一個很嚴重的問題,該架構的核心是使用循環神經網路進行運算,撇開梯度消失的問題之蔡,其最大的缺點是運算速度非常緩慢,每次運算必須等待上一個單元計算完畢後才能取得結果無法進行平行運算,而且該模型承襲了循環神經網路只能單向運算的特性,因此不論是效能或速度上其實都有可以改善的地方,而在今天介紹的模型Transformer同樣的也是Encoder與Decoder架構的模型,但他在效能與執行速度上則有了大幅的提升,現在讓我們看看該模型的架構與數學式吧
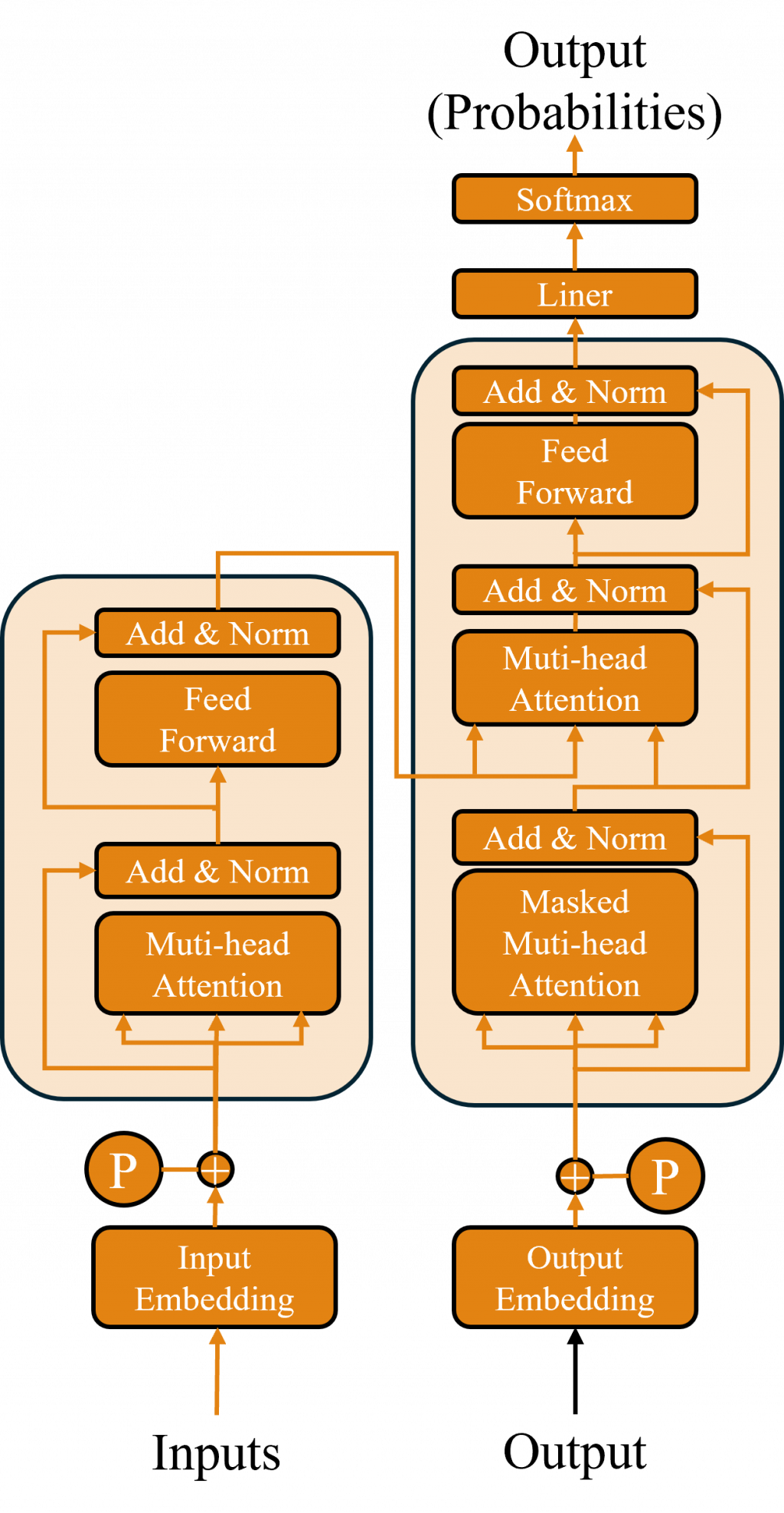
Transformer 是一種基於注意力機制(Attention Mechanism)的深度學習模型架構,是由 Vaswani 等人於 2017 年在論文《Attention is All You Need》中提出。雖然一開始是被設計用於自然語言處理任務,但隨著時間的推移,其應用範圍擴展到了電腦視覺等其他領域,基本上現今所有強大的模型都是基於此架構開發而成的,而其主要特點是能夠更高效地處理序列數據,尤其是在長序列上具有出色的表現,現在讓我們拆解模型架構來看看其內容吧。
在循環神經網路這類的時間序列模型中,其遞迴結構保留了序列中元素的順序資訊,但 Transformer 模型完全依賴平行運算並不具備順序意識。如果直接將序列傳送到模型中,可能會導致模型學到混亂的序列資訊,進而影響效果。因此我們需要一種方法將位置信息引入模型中而這種方式就是 Positional Encoding。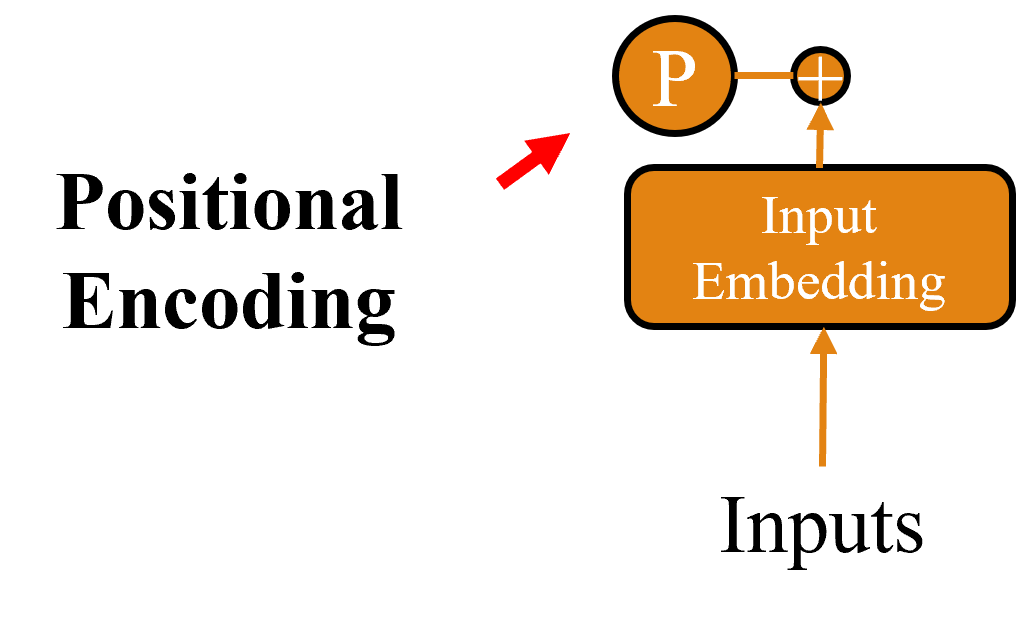
在 Positional Encoding 中,其編碼方式是將位置信息嵌入到輸入給模型的嵌入層中,並通過正弦與餘弦函數來實現。具體方法是對奇數位置使用正弦函數進行編碼,對偶數位置則使用餘弦函數進行計算。其數學公式如下所示: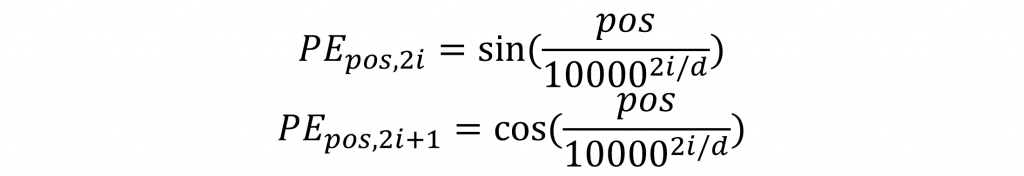
該公式的設計主要利用了 sin() 和 cos() 函數的周期性特性,因為這些函數非常適合表現循環性特徵。通過將不同頻率的 sin() 和 cos() 函數用於位置編碼,可以在多個尺度上捕捉序列中元素的相對距離,從而使每個位置的編碼具有獨特且可區分的特性。這種方法有助於模型更有效地學習詞與詞之間的相對位置關係。
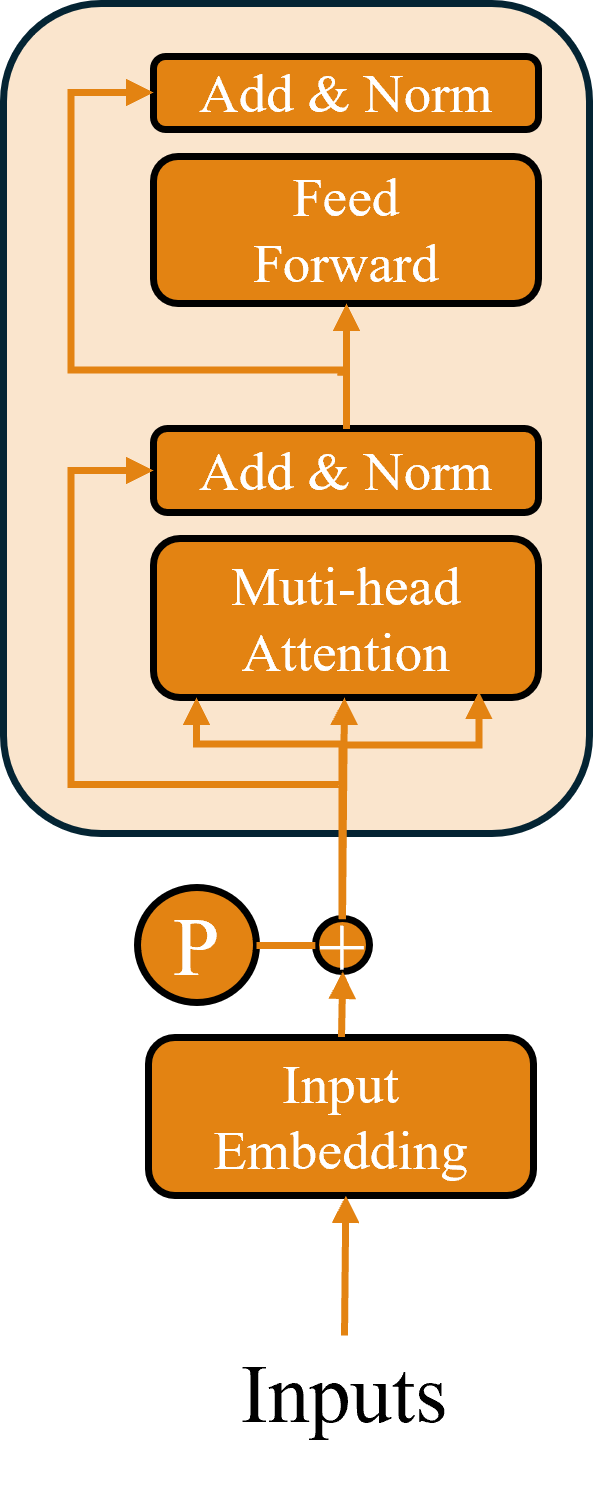
在Transformer中,最重要的部分是其自注意機制(Self-Attention)。該機制不同於Seq2Seq模型需要通過編碼器(Encoder)和解碼器(Decoder)之間的運算。自注意機制是使用每一個序列的查詢向量(Query, Q)、鍵向量(Key, K)和值向量(Value, V),在內部進行注意力運算。這三個向量分別通過與各自的權重矩陣W進行運算得到,其運算流程圖如下所示。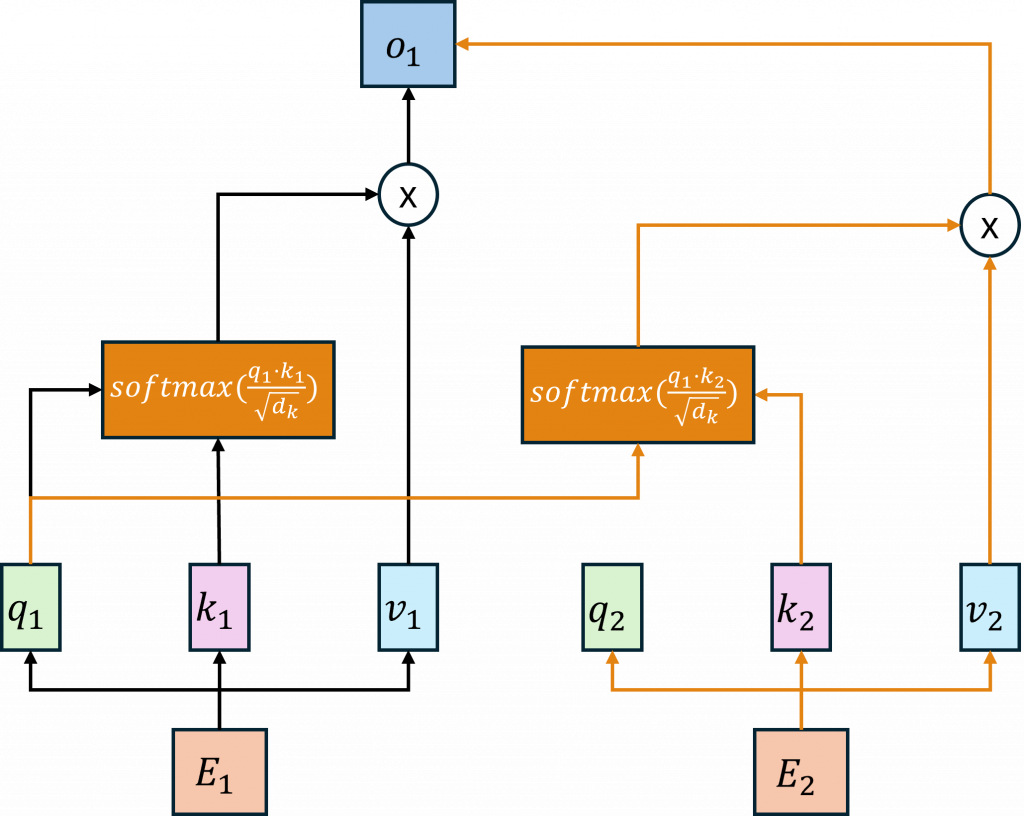
在所有的注意力機制中,計算的核心是通過計算注意力權重,並將其應用於對應的向量進行操作。例如在 Seq2Seq 模型中,首先利用Encoder和Decoder的隱藏狀態來計算注意力權重,然後與對應的上下文向量進行加權運算。
而在 Transformer 模型中,則是通過查詢向量與鍵向量計算出注意力權重,再將其應用於值向量上進行運算
,這種方式的目的是評估序列中的每個元素對其他元素的關注程度。具體而言對於 Transformer 中的Encoder其主要公式如下: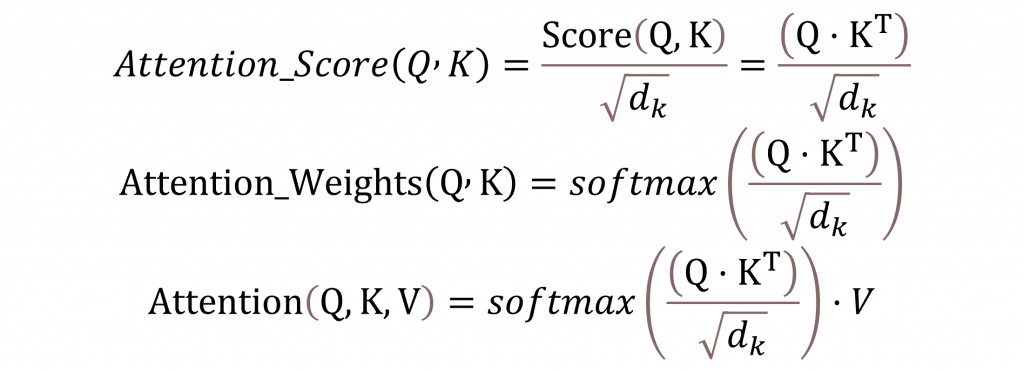
其中 √𝑑 是與鍵向量維度大小相等的數值,其目的是為了調整查詢向量與鍵向量相乘後可能出現過大的數值。這樣做是為了防止數值過大導致梯度消失或爆炸的問題,因此需要將這些放大的數值縮放回合理範圍。
在整個計算過程中,我們可以看到,最後一步與 Seq2Seq 模型相同,都是通過 Softmax 函數來計算注意力權重,並且與值向量進行加權運算,這代表每個輸出都是基於每一個查詢向量與鍵向量所計算的權重與機率。因此每一個輸出都反映了模型對所有輸入資訊的考量,這使得每個輸出結果比 Seq2Seq 方法更加豐富,因為Transformer 能夠更有效地捕捉全局關聯,從而產生更具信息性的結果。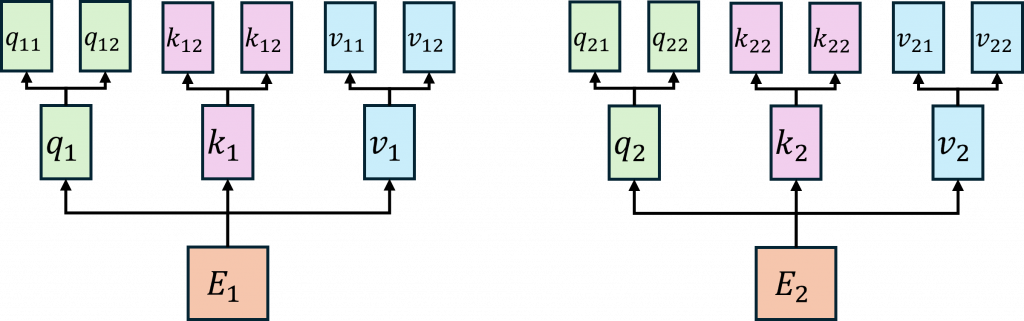
實際上Transformer 模型使用的是**多頭自注意力機制(Multi-Head Self-Attention)**來進行運算,這與單純的自注意力機制不同。多頭自注意力機制的主要區別在於,它會將查詢向量、鍵向量和值向量進行多次投影,生成多組查詢、鍵、和值向量,並在不同的頭(head)上進行獨立的注意力計算。每個頭能夠專注於輸入序列中的不同部分或特性,從而使模型能夠捕捉到更豐富的語意特性和上下文關係。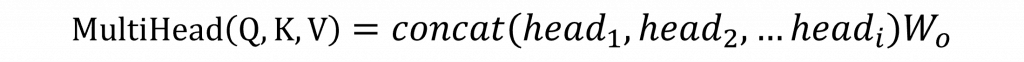
在經過注意力機制之後,為了能夠進行最終的輸出或計算機率,我們可以使用全連接層來處理數據。這個概念在 Transformer 中依然適用,但 Transformer 和 DCGAN 一樣,屬於較深層的網路,因此需要解決內部協變量偏移問題。
為了解決這個問題,Transformer 中引入了 Layer Normalization,其原理是通過對每一層的輸入 x 進行正規化處理,來穩定每一層的輸出結果從而促進模型更快、更穩定地收斂。Layer Normalization 的作用類似於 Batch Normalization,但它是針對每一個樣本的輸入進行正規化,而不是針對整個 batch。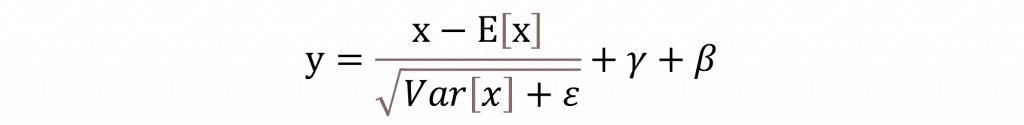
ε的用途主要是為了防止出現除以零的情況,因此其數值通常會設定得非常小,這樣可以確保計算過程中的穩定性,避免數值不穩定帶來的計算錯誤。至於γ則是用來控制縮放輸出的幅度,它在每一層中都可以進行調整,從而使模型能夠靈活地學習到不同特徵的權重。這樣可以幫助模型更好地適應不同數據的特性。而β則是代表該層的偏移量,這個偏移量可以幫助模型在學習過程中更好地調整輸出,使其更加接近真實數據的分佈。
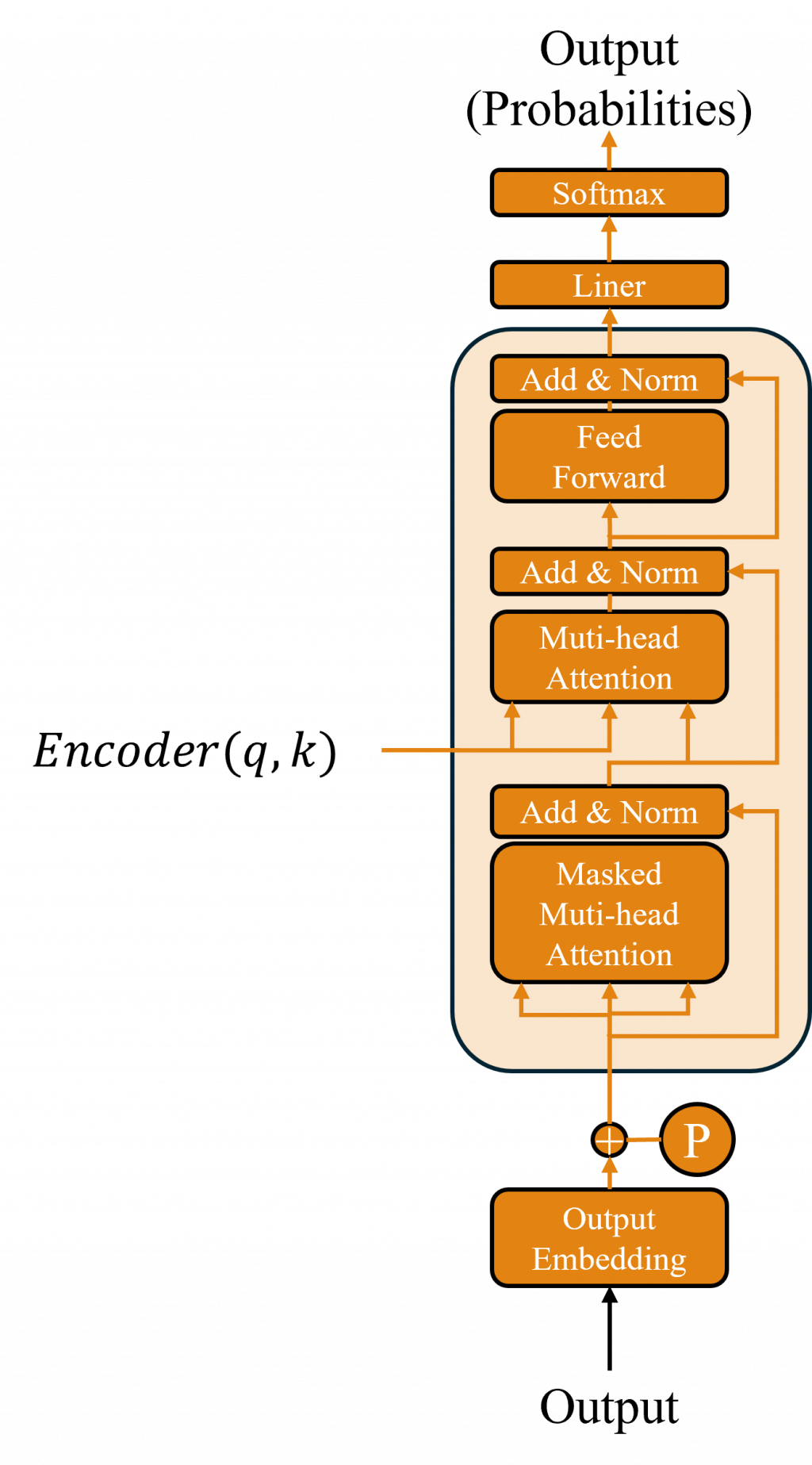
我們了解到Decoder在訓練時使用了 Teacher Forcing 方法,這種方法依賴於上一時間步的輸出和當前的輸入,但 Transformer 模型使用的是並行運算,在這種情況下,如果不進行特定的處理,注意力機制可能會包含完整的注意力權重信息,導致模型提前看到未來的時序信息,進而引發運算錯誤。
為了解決這個問題,Transformer 的 Decoder 中引入了一個 Masked Multi-head Attention(遮蔽式多頭注意力機制) 層。這一層的作用是確保模型在當前步驟中,僅能關注到當前或之前的位置信息,而無法看到未來的輸入。具體做法是生成一個 遮蔽矩陣(Masking Matrix),來遮蔽掉未來時間步的信息。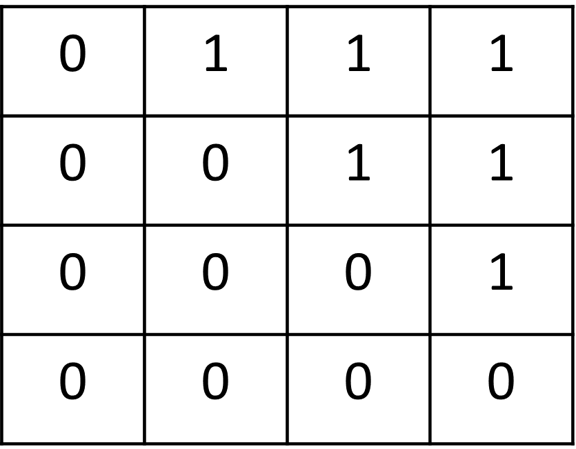
其計算原理是通過遮蔽注意力權重中的未來位置,從而防止當前生成的序列包含未來信息,這有效解決了信息泄露的問題。在計算注意力權重時,對於那些代表未來位置的部分(遮蔽矩陣中為 1 的部分),賦予一個負無窮大的值,這樣在進行 Softmax 計算時,這些位置的權重會趨近於零,幾乎不起作用。
這樣的設計確保了模型在生成序列時只能依賴當前和之前的輸入,避免提前看到未來的信息,從而保持生成的序列順序性和合理性。簡單來說,在進行多頭注意力機制計算之前,首先執行遮蔽操作,其他的計算過程則與 Encoder 中的多頭自注意力機制相同。
我們的學習進度已經來到了 2/3,今天進入的章節可以說是整個 AI 發展中最關鍵的部分。這個模型在語音變式、文字生成、語音生成等領域中,已經成為最重要的技術之一,這都要歸功於該模型中的 Self-Attention 機制。因此而在接下來的章節中,我們將深入學習和探索以這個模型為基礎的各種技術演變與優化,通過改進與調整該模型的架構,讓你逐步了解這些技術的發展過程與背後的原理。

