
各位學習完資料處理文件資料後,接下來就是要學習如何爬蟲了!
大家要思考一下為什麼要使用爬蟲?
其實最主要的目的,就是要從別人的資料幹過來分析 
網路爬蟲其實有兩個分類,分別是網路爬蟲 web crawler和網頁抓取 web scraper,但我們習慣使用「網路爬蟲」為統稱,兩個的宗旨都是從網站上擷取資料下來。
本文會以Web Scraping主要是擷取網站結構資訊為主
今天學習的爬蟲武器鍛造目標會有
1.網路擷取資料的知識背景
2.擷取網路上的資料
3.準備的工具
4.網路爬蟲的目標與使用場景
 )
)
source: https://www.geeksforgeeks.org/http-full-form/
近代的知識擷取中大部分都會透過網路的HTTP協議或是HTTPS加密傳輸協定來提供訊息或資料。
所以相關的網路基礎也是很重要的。
HTTP可以把它當作是我們使用傳輸的協定(想像成貨車的感覺) => 因為傳輸方法也有很多種
| 項目 | 說明 |
|---|---|
| HTTP 定義 | 超文本傳輸協議,用於客戶端和伺服器之間傳輸資料。 |
| 請求與回應 | 請求:客戶端發送到伺服器的請求;回應:伺服器對請求的回應。 |
| HTTP 方法 | - GET:獲取數據- POST:提交數據- PUT:更新資源- DELETE:刪除資源 |
| HTTP 標頭 | 附加資訊,例如 User-Agent(客戶端資訊)和 Content-Type(數據類型)。 |
| 狀態碼 | - 200 OK:請求成功- 404 Not Found:資源不存在- 500 Internal Server Error:伺服器錯誤 |
| 安全性 | 使用 HTTPS 提供加密以保護資料傳輸過程中的安全。 |
這之前還有前端跟後端的差別
tips 通常都是後端工程師提供資料,前端工程師實踐畫面
那界接的窗口就是API是 Application Programming Interface 的縮寫,指的是一組明確定義的規則,讓不同的軟體應用程式能夠互相溝通和交換資料
簡單說就是後端工程師把資料源(資料庫、靜態檔案) 包裝成一個可以讓你連線取得的方法。
這整取得的窗口就是API。 -> 我們可以把她想像成
後端 => 商家物流中心 => 定義好的API,依照規範跟連線方式制定貨車或運輸車 => 傳輸協議,可能是 RESRful API前端 => 要領到貨(data)的人
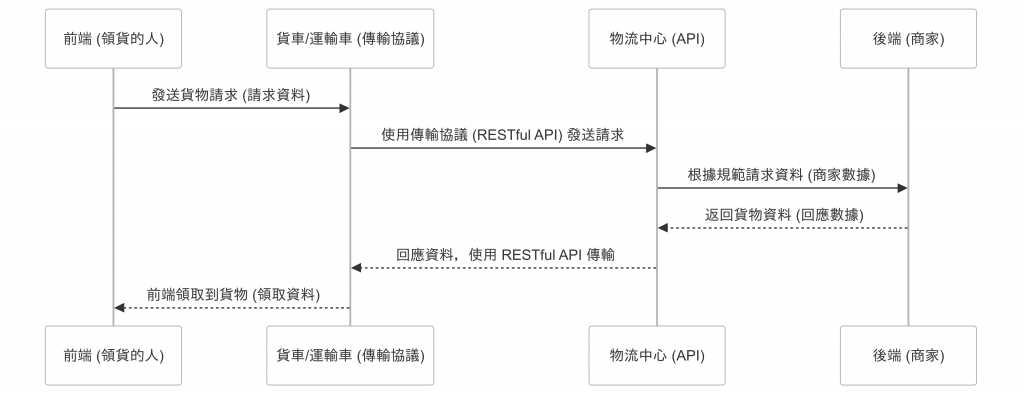
API 的運作方式
1.請求 (Request):
客戶端發送請求到伺服器,通常包括所需的動作(如獲取或修改數據)以及身份驗證信息23。
2.處理 (Processing):
伺服器接收到請求後,根據 API 的規範進行處理,例如讀取或寫入數據庫45。
3.回應 (Response):
處理完請求後,伺服器會將結果返回給客戶端,通常包括狀態碼和請求的數據
| 項目 | 前端 (Front-End) | 後端 (Back-End) |
|---|---|---|
| 定義 | 直接與使用者互動的部分,負責網頁的視覺呈現和用戶體驗。 | 負責處理數據、業務邏輯和伺服器端的功能。 |
| 技術 | 使用 HTML、CSS 和 JavaScript 等技術構建介面。 | 使用伺服器端語言(如 PHP、Python、Node.js)和資料庫技術(如 MySQL、MongoDB)。 |
| 功能 | 顯示內容、處理用戶輸入、提供互動性。 | 處理請求、管理數據庫、執行業務邏輯。 |
| 工作範疇 | 設計網頁佈局、實現動畫效果、確保跨瀏覽器兼容性。 | 建立和維護伺服器、設計 API 接口、處理數據存取。 |
| 使用者接觸 | 使用者可以直接看到和操作的部分。 | 使用者通常無法直接看到,僅通過前端介面交互。 |
前端:
後端:
其實可以簡單歸類
前端設計就是: 設計出好看頁面的工程師。(網頁的畫面或是手機app的畫面)
後端設計就是: 整理資料跟分析資料的人。(我們前面在做的事情,還有提供API的人)
tips - 前端(front-end)跟客戶端(client)的不同
很多人會混淆前端跟顧客端,
前端是指: 工程師寫程式碼,呈現瀏覽器或是裝置的介面設計或操作模式的功能。
客戶端:使用者(user)操作介面的裝置,可能是電腦的瀏覽器,也有可能是手機app。
擷取網路上的資料主要可以通過兩種方式:網路爬蟲和API 調用。以下是這兩種方法的比較及其特點:
定義:網路爬蟲是一種自動化工具,通過模擬用戶行為來訪問網站並提取數據。它通常涉及發送 HTTP 請求,接收 HTML 回應,然後解析和提取所需的數據。
優點:
缺點:
定義:API 調用是通過發送請求到特定的 API 端點來獲取結構化數據的方法。API 通常提供清晰的文檔,說明如何獲取所需數據。
優點:
缺點:
擷取網路上的資料主要可以透過網路爬蟲和 API 調用這兩種方式。選擇哪一種方法取決於具體需求、目標網站的可用性以及數據的結構化程度。如果網站提供 API,通常建議使用 API 調用,因為這樣可以更有效率地獲取數據並減少潛在的法律風險。如果沒有可用的 API,則需要考慮使用網路爬蟲技術。
透過前面學到的我們擷取資料的方式是調用api以及網路爬蟲
基於我們是使用python來操作
所以會整理一些常用的library
後續會使用到這些library來操作給大家看喔
| 工具 | 描述 | 應用場景 |
|---|---|---|
| Scrapy | 一個強大的網頁抓取框架,適合大規模數據抓取和處理。 | - 數據挖掘:提取網站上的結構化數據,如產品資訊、價格等。- 市場研究:收集競爭對手的數據以進行分析。- 自動化測試:驗證網站內容的正確性。 |
| Beautiful Soup | 用於解析 HTML 和 XML 文檔,方便從中提取數據。 | - 簡單的靜態網站抓取:適合小型項目或單一頁面的數據提取,如新聞標題或文章內容。- 數據清理:從複雜的 HTML 結構中提取所需信息。 |
| Selenium | 用於自動化瀏覽器操作,適合抓取動態生成內容的網站(如使用 JavaScript 的網站)。 | - 動態網站抓取:提取需要用戶互動或 JavaScript 渲染的內容,如社交媒體平台的帖子。- 測試自動化:自動化測試網頁應用程式的功能和性能。 |
| MechanicalSoup | 結合 Requests 和 Beautiful Soup 的功能,簡化網站互動和數據提取。 | - 表單提交:自動填寫並提交網頁表單以獲取後續數據。- 會話管理:保持會話狀態以便於多次請求。 |
| Lxml | 高效的 XML 和 HTML 解析庫,適合需要快速處理大文件的場景。 | - 高效解析:在需要快速解析和處理大量數據時使用,如大型資料集的抓取與分析。 |
| Playwright | 支持多種瀏覽器的自動化測試框架,適合抓取需要 JavaScript 渲染的網站。 | - 跨瀏覽器測試:驗證不同瀏覽器上的網站功能。- 實時數據抓取:從即時更新的網站獲取資料。 |
| Requests | 簡單易用的 HTTP 請求庫,適合與網路服務進行交互。 | - 網頁抓取:發送 HTTP 請求以獲取網頁 HTML 內容,然後解析和提取所需數據。- API 調用:向 API 發送請求並處理回應,進行數據整合。- 文件下載/上傳:從 URL 下載文件或向伺服器上傳文件。- 會話管理:管理用戶會話以保持狀態,便於多次請求。- 監控與數據收集:定期從不同來源獲取數據,監控網站內容變化或追蹤實時數據。 |
使用場景
| 目標 | 範例 | 使用場景 |
|---|---|---|
| 編纂網路索引 | 搜尋引擎爬蟲自動抓取網頁以建立索引 | Google、Bing 等搜尋引擎的索引建設 |
| 數據收集 | 自動收集商品價格、天氣資訊等 | 價格比較網站、天氣應用程式 |
| 監控與分析 | 監控競爭對手網站上的價格變化 | 市場研究、競爭對手分析 |
| 資料驅動的決策 | 分析社交媒體情緒以調整行銷策略 | 行銷活動、品牌管理 |
| 驗證網站內容 | 檢查網站上的鏈接是否有效 | 網站維護、SEO 優化 |
| 資料挖掘 | 從社交媒體或論壇提取用戶評論進行分析 | 學術研究、情感分析 |
| 注意事項 | 描述 |
|---|---|
遵循 robots.txt |
檢查網站的 robots.txt 文件,遵循網站對爬蟲的規範。 |
| 避免過度請求 | 設置請求間隔,避免對伺服器造成負擔,減少被封鎖的風險。 |
| 尊重智慧財產權 | 不侵犯版權或商標權,合法使用抓取到的數據。 |
| 數據使用合規性 | 遵循法律法規,特別是個人資料保護法,避免收集敏感數據。 |
| 查看網站服務條款 | 仔細閱讀目標網站的服務條款,確保不違反其規定。 |
| 保持透明和負責任 | 若可能,與網站所有者聯繫並告知爬蟲計劃,以建立信任。 |
| 使用適當工具和技術 | 選擇合適的工具(如 Scrapy、Beautiful Soup)以提高效率並減少伺服器壓力。 |
| 監控和維護 | 定期檢查爬蟲運行狀態,及時更新以應對網站結構變化。 |
成為一名優秀的網路爬蟲者不僅需要技術能力,還需具備良好的道德規範和法律意識。

