在今日教學中,我們將學習如何結合 Stable Baselines 3 和之前大量篇幅介紹的 Backtrader,使用強化學習方法開發一個股票交易策略,終於有一個大融合的感覺了!我們會附完整程式在最後面,你也可以在 Colab 上直接運行。
在 Google Colab 中,我們需要安裝以下庫:
!pip install stable-baselines3
!pip install gymnasium
!pip install gymnasium[classic_control]
!pip install backtrader
!pip install yfinance
!pip install matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
import backtrader as bt
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common import env_checker
import gymnasium as gym
from gymnasium import spaces
我們將使用 yfinance 下載蘋果公司(AAPL)的歷史數據。
data = yf.download('AAPL', start='2015-01-01', end='2021-01-01')
data.reset_index(inplace=True)
data['Date'] = pd.to_datetime(data['Date']) # 確保 Date 列為 datetime 類型
data = data[['Date', 'Open', 'High', 'Low', 'Close', 'Volume']]
data.set_index('Date', inplace=True)
data['Open'] = data['Open'].astype('float32')
data['High'] = data['High'].astype('float32')
data['Low'] = data['Low'].astype('float32')
data['Close'] = data['Close'].astype('float32')
data['Volume'] = data['Volume'].astype('float32')
在這一部分,我們將創建一個自訂的交易環境 TradingEnv,它繼承自 gym.Env,以便與強化學習模型進行交互。這個環境將模擬股票交易的過程,並允許代理在環境中學習交易策略。
class TradingEnv(gym.Env):
"""自訂的交易環境,用於強化學習模型訓練"""
def __init__(self, data, cash=10000, commission=0.001):
super(TradingEnv, self).__init__()
self.data = data.reset_index()
self.cash = cash # 初始現金
self.initial_cash = cash # 紀錄初始現金
self.commission = commission # 交易手續費
self.current_step = 0 # 當前時間步
# 定義觀測空間和行動空間
self.observation_space = spaces.Box(
low=-np.inf, high=np.inf, shape=(5,), dtype=np.float32
)
self.action_space = spaces.Discrete(3) # 0: 持有, 1: 買入, 2: 賣出
# 初始化帳戶資訊
self.position = 0 # 持有的股票數量
self.net_worth = self.cash # 資產淨值
self.prev_net_worth = self.cash # 前一步的資產淨值
# 紀錄交易訊號
self.trades = []
def _get_obs(self):
"""獲取當前的觀測值"""
obs = np.array([
self.data.loc[self.current_step, 'Open'],
self.data.loc[self.current_step, 'High'],
self.data.loc[self.current_step, 'Low'],
self.data.loc[self.current_step, 'Close'],
self.data.loc[self.current_step, 'Volume'],
], dtype=np.float32)
return obs
def reset(self, *, seed=None, options=None):
"""重置環境到初始狀態"""
super().reset(seed=seed)
self.current_step = 0
self.position = 0
self.cash = self.initial_cash
self.net_worth = self.cash
self.prev_net_worth = self.cash
self.trades = [] # 重置交易紀錄
obs = self._get_obs()
info = {}
return obs, info
def step(self, action):
"""執行一個行動,並返回新的狀態和獎勵"""
current_price = self.data.loc[self.current_step, 'Close']
# 記錄交易訊號
date = self.data.loc[self.current_step, 'Date']
self.trades.append({'Date': date, 'Action': action})
# 計算交易手續費
commission = 0
if action == 1: # 買入
# 計算可買入的最大股數
max_shares = int(self.cash / (current_price * (1 + self.commission)))
if max_shares > 0:
# 更新帳戶餘額和持倉
cost = max_shares * current_price * (1 + self.commission)
self.cash -= cost
self.position += max_shares
commission = cost * self.commission
elif action == 2: # 賣出
if self.position > 0:
# 更新帳戶餘額和持倉
revenue = self.position * current_price * (1 - self.commission)
self.cash += revenue
commission = self.position * current_price * self.commission
self.position = 0
# action == 0 表示持有,不執行任何操作
self.current_step += 1
# 更新資產淨值
self.net_worth = self.cash + self.position * current_price
# 計算獎勵
reward = self.net_worth - self.prev_net_worth - commission
self.prev_net_worth = self.net_worth
# 判斷是否終止
if self.current_step >= len(self.data) - 1:
terminated = True
else:
terminated = False
truncated = False
obs = self._get_obs()
info = {}
return obs, reward, terminated, truncated, info
def render(self):
"""渲染環境(此處未實作)"""
pass
__init__ 方法:
_get_obs 方法:
reset 方法:
step 方法:
render 方法:
env = TradingEnv(data)
使用 Stable Baselines 3 提供的工具檢查環境是否符合要求:
env_checker.check_env(env)
將環境包裝為向量化環境,以便與 Stable Baselines 3 的算法兼容:
env = DummyVecEnv([lambda: env])
使用常見 RL 演算法,今天我們使用 PPO 算法為例進行訓練::
model = PPO('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000)
可以看到模型訓練: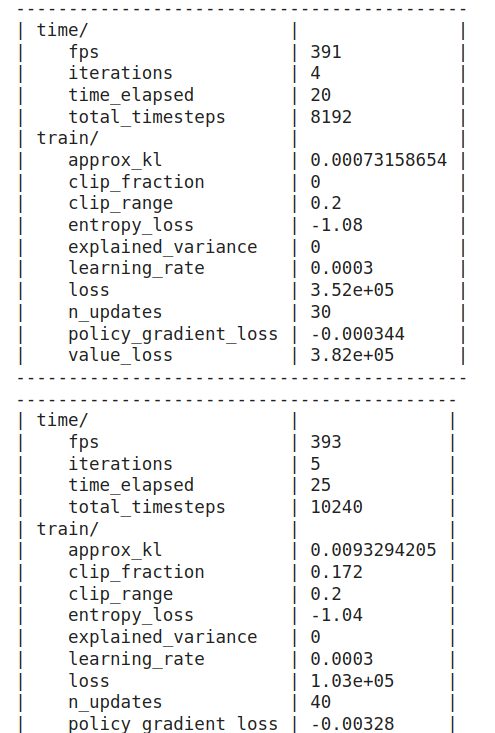
env.envs[0].reset()
for i in range(len(data) - 1):
obs = env.envs[0]._get_obs()
action, _states = model.predict(obs)
obs, rewards, dones, truncated, info = env.envs[0].step(action)
if dones:
break
env.envs[0],以便收集交易訊號。# 從環境中獲取交易紀錄
trades = pd.DataFrame(env.envs[0].trades)
# 將交易紀錄與原始數據合併
data.reset_index(inplace=True)
merged_data = pd.merge(data, trades, on='Date', how='left')
merged_data['Action'].fillna(0, inplace=True)
# 確保 Date 列為 datetime 類型
merged_data['Date'] = pd.to_datetime(merged_data['Date'])
class RLStrategy(bt.Strategy):
"""自訂的策略,用於在圖表上顯示買賣點"""
def __init__(self):
self.dataclose = self.datas[0].close
def next(self):
# 根據交易紀錄執行買賣
idx = len(self) - 1 # 當前索引
action = merged_data.loc[idx, 'Action']
if action == 1 and self.position.size == 0:
# 買入
self.buy(size=100)
elif action == 2 and self.position.size > 0:
# 賣出
self.sell(size=self.position.size)
cerebro = bt.Cerebro()
# 在添加數據時,指定 datetime 列
data_bt = bt.feeds.PandasData(
dataname=merged_data,
datetime='Date',
open='Open',
high='High',
low='Low',
close='Close',
volume='Volume',
openinterest=-1,
timeframe=bt.TimeFrame.Days
)
cerebro.adddata(data_bt)
cerebro.addstrategy(RLStrategy)
cerebro.broker.setcash(10000)
cerebro.broker.setcommission(commission=0.001)
print('初始資金: %.2f' % cerebro.broker.getvalue())
cerebro.run()
print('最終資金: %.2f' % cerebro.broker.getvalue())
資金有成長:
%matplotlib inline
plt.rcParams['figure.figsize'] = [20, 16]
plt.rcParams.update({'font.size': 12})
img = cerebro.plot(iplot = False)
img[0][0].savefig('backtrader_ppo.png')
可以得到下面結果,看起來真的密密麻麻的買賣點:
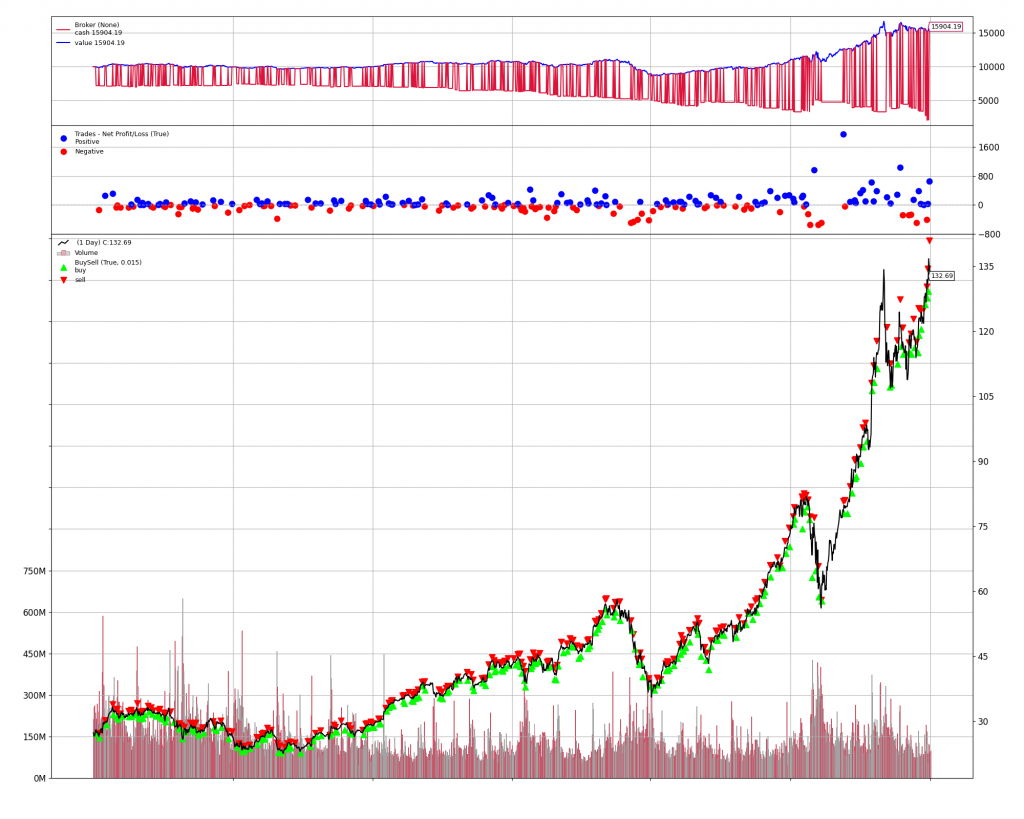
通過 Backtrader 的圖表,我們可以看到模型在測試期間的買賣點,以及資產淨值的變化。這有助於我們直觀地了解模型的交易決策和績效。
以下是完整的程式碼,您可以直接在 Google Colab 上執行。
# 安裝必要的庫
!pip install stable-baselines3
!pip install gymnasium
!pip install gymnasium[classic_control]
!pip install backtrader
!pip install yfinance
!pip install matplotlib
# 導入庫
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
import backtrader as bt
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common import env_checker
import gymnasium as gym
from gymnasium import spaces
# 獲取數據
data = yf.download('AAPL', start='2015-01-01', end='2021-01-01')
data.reset_index(inplace=True)
data['Date'] = pd.to_datetime(data['Date']) # 確保 Date 列為 datetime 類型
data = data[['Date', 'Open', 'High', 'Low', 'Close', 'Volume']]
data.set_index('Date', inplace=True)
# 數據預處理
data['Open'] = data['Open'].astype('float32')
data['High'] = data['High'].astype('float32')
data['Low'] = data['Low'].astype('float32')
data['Close'] = data['Close'].astype('float32')
data['Volume'] = data['Volume'].astype('float32')
# 定義交易環境
class TradingEnv(gym.Env):
"""自訂的交易環境,用於強化學習模型訓練"""
def __init__(self, data, cash=10000, commission=0.001):
super(TradingEnv, self).__init__()
self.data = data.reset_index()
self.cash = cash # 初始現金
self.initial_cash = cash # 紀錄初始現金
self.commission = commission # 交易手續費
self.current_step = 0 # 當前時間步
# 定義觀測空間和行動空間
self.observation_space = spaces.Box(
low=-np.inf, high=np.inf, shape=(5,), dtype=np.float32
)
self.action_space = spaces.Discrete(3) # 0: 持有, 1: 買入, 2: 賣出
# 初始化帳戶資訊
self.position = 0 # 持有的股票數量
self.net_worth = self.cash # 資產淨值
self.prev_net_worth = self.cash # 前一步的資產淨值
# 紀錄交易訊號
self.trades = []
def _get_obs(self):
"""獲取當前的觀測值"""
obs = np.array([
self.data.loc[self.current_step, 'Open'],
self.data.loc[self.current_step, 'High'],
self.data.loc[self.current_step, 'Low'],
self.data.loc[self.current_step, 'Close'],
self.data.loc[self.current_step, 'Volume'],
], dtype=np.float32)
return obs
def reset(self, *, seed=None, options=None):
"""重置環境到初始狀態"""
super().reset(seed=seed)
self.current_step = 0
self.position = 0
self.cash = self.initial_cash
self.net_worth = self.cash
self.prev_net_worth = self.cash
self.trades = [] # 重置交易紀錄
obs = self._get_obs()
info = {}
return obs, info
def step(self, action):
"""執行一個行動,並返回新的狀態和獎勵"""
current_price = self.data.loc[self.current_step, 'Close']
# 記錄交易訊號
date = self.data.loc[self.current_step, 'Date']
self.trades.append({'Date': date, 'Action': action})
# 計算交易手續費
commission = 0
if action == 1: # 買入
# 計算可買入的最大股數
max_shares = int(self.cash / (current_price * (1 + self.commission)))
if max_shares > 0:
# 更新帳戶餘額和持倉
cost = max_shares * current_price * (1 + self.commission)
self.cash -= cost
self.position += max_shares
commission = cost * self.commission
elif action == 2: # 賣出
if self.position > 0:
# 更新帳戶餘額和持倉
revenue = self.position * current_price * (1 - self.commission)
self.cash += revenue
commission = self.position * current_price * self.commission
self.position = 0
# action == 0 表示持有,不執行任何操作
self.current_step += 1
# 更新資產淨值
self.net_worth = self.cash + self.position * current_price
# 計算獎勵
reward = self.net_worth - self.prev_net_worth - commission
self.prev_net_worth = self.net_worth
# 判斷是否終止
if self.current_step >= len(self.data) - 1:
terminated = True
else:
terminated = False
truncated = False
obs = self._get_obs()
info = {}
return obs, reward, terminated, truncated, info
def render(self):
"""渲染環境(此處未實作)"""
pass
# 創建環境實例
env = TradingEnv(data)
# 檢查環境
env_checker.check_env(env)
# 包裝環境
env = DummyVecEnv([lambda: env])
# 訓練模型
model = PPO('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000)
# 測試模型並收集交易訊號
env.envs[0].reset()
for i in range(len(data) - 1):
obs = env.envs[0]._get_obs()
action, _states = model.predict(obs)
obs, rewards, dones, truncated, info = env.envs[0].step(action)
if dones:
break
# 從環境中獲取交易紀錄
trades = pd.DataFrame(env.envs[0].trades)
# 將交易紀錄與原始數據合併
data.reset_index(inplace=True)
merged_data = pd.merge(data, trades, on='Date', how='left')
merged_data['Action'].fillna(0, inplace=True)
# 確保 Date 列為 datetime 類型
merged_data['Date'] = pd.to_datetime(merged_data['Date'])
# 在 Backtrader 中顯示買賣點
class RLStrategy(bt.Strategy):
"""自訂的策略,用於在圖表上顯示買賣點"""
def __init__(self):
self.dataclose = self.datas[0].close
def next(self):
# 根據交易紀錄執行買賣
idx = len(self) - 1 # 當前索引
action = merged_data.loc[idx, 'Action']
if action == 1 and self.position.size == 0:
# 買入
self.buy(size=100)
elif action == 2 and self.position.size > 0:
# 賣出
self.sell(size=self.position.size)
# 設置 Backtrader
cerebro = bt.Cerebro()
# 在添加數據時,指定 datetime 列
data_bt = bt.feeds.PandasData(
dataname=merged_data,
datetime='Date',
open='Open',
high='High',
low='Low',
close='Close',
volume='Volume',
openinterest=-1,
timeframe=bt.TimeFrame.Days
)
cerebro.adddata(data_bt)
cerebro.addstrategy(RLStrategy)
cerebro.broker.setcash(10000)
cerebro.broker.setcommission(commission=0.001)
print('初始資金: %.2f' % cerebro.broker.getvalue())
cerebro.run()
print('最終資金: %.2f' % cerebro.broker.getvalue())
# 繪製圖表
%matplotlib inline
cerebro.plot(iplot=True, volume=False)
在本教學中,我們:
希望通過本教學,能夠深入理解如何使用強化學習方法進行量化交易策略的開發,並掌握 Stable Baselines 3 和 Backtrader 的實際應用技巧。


 iThome鐵人賽
iThome鐵人賽