除了交易市場的股價、歷史股價可以成為我們的交易參考原則,市場的情緒也是一個非常好的參考來源,例如可以透過新聞猜測現在市場是否為恐慌、經濟是否下行導致市場信心不足等等。在本課中,我們將探討如何使用自然語言處理(NLP)技術來分析文本數據,特別是從新聞和社交媒體中提取市場情緒。我們將學習如何使用 NLTK 和 SpaCy 等庫進行文本分析,並瞭解情緒分析在金融領域的重要性。今日 Colab
我們將使用以下 Python 庫:
!pip install nltk
!pip install spacy
!pip install textblob
!pip install tweepy
!pip install newspaper3k
!pip install wordcloud
!python -m spacy download en_core_web_sm
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
import spacy
from textblob import TextBlob
import tweepy
from newspaper import Article
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
nltk.download('vader_lexicon')
nltk.download('punkt')
sia = SentimentIntensityAnalyzer()
sentence = "Apple's new product has received rave reviews from critics. Everyone loves the new apple product! Great job, Apple!"
scores = sia.polarity_scores(sentence)
print(scores)

輸出:
可以看到這個中性偏向正面的句子,市場很喜歡蘋果的這個消息!
我們以 CNBC 上一篇關於 Apple 的新聞為例
url = 'https://www.cnbc.com/2024/10/04/apple-is-turning-to-its-army-of-developers-for-an-edge-in-the-ai-race.html?&qsearchterm=apple'
article = Article(url)
# 下載並解析文章
article.download()
article.parse()
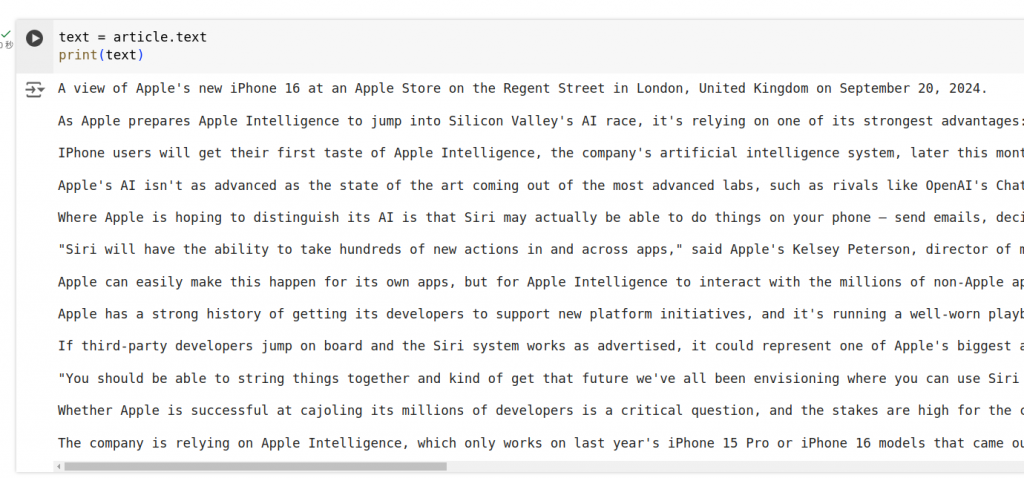
text = article.text
print(text)
scores = sia.polarity_scores(text)
print(scores)


除了使用 NLTK 來進行 NLP,我們也可用 SpaCy 來做
nlp = spacy.load('en_core_web_sm')
我們一樣使用 Apple 的新聞
doc = nlp(text)
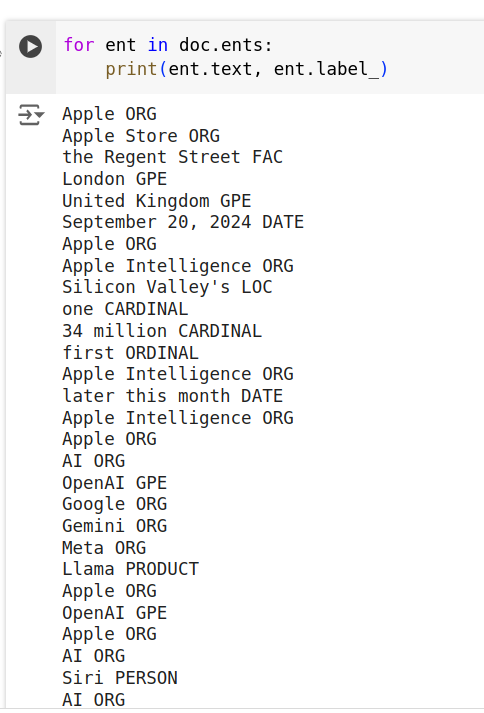
我們可以分析出句子裡的每個字是什麼,例如 Apple 是組織(公司)
for ent in doc.ents:
print(ent.text, ent.label_)
您需要在 Twitter Developer 平台上申請 API 憑證。API key 設置教學可參考這裡
consumer_key = '你的消費者金鑰'
consumer_secret = '你的消費者密鑰'
access_token = '你的存取權杖'
access_token_secret = '你的存取權杖密鑰'
auth = tweepy.OAuth1UserHandler(consumer_key, consumer_secret, access_token, access_token_secret)
api = tweepy.API(auth)
tweets = api.search_tweets(q='Apple', lang='en', count=100)
tweet_texts = [tweet.text for tweet in tweets]
scores = [sia.polarity_scores(text)['compound'] for text in tweet_texts]
plt.hist(scores, bins=20)
plt.title('Twitter 上關於 Apple 的情緒分佈')
plt.xlabel('情緒得分')
plt.ylabel('推文數量')
plt.show()
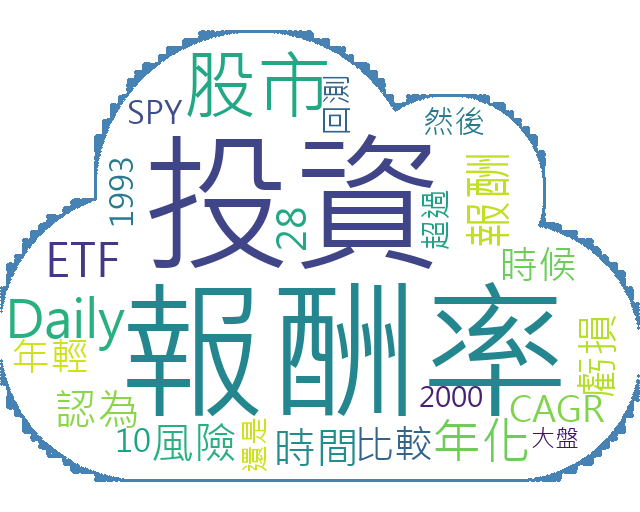
我們將使用從 Twitter 獲取的推文文本來生成文字雲,直觀地展示頻繁出現的詞語。
# 合併所有推文文本
text_combined = ' '.join(tweet_texts)
# 創建文字雲對象
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text_combined)
# 繪製文字雲
plt.figure(figsize=(15, 7.5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Twitter 上關於 Apple 的文字雲', fontsize=20)
plt.show()
width 和 height:設定圖片的寬度和高度。background_color:設定背景顏色,這裡選擇白色。generate 方法生成文字雲。通過文字雲,我們可以直觀地看到在推文中出現頻率較高的詞語。這有助於我們了解市場關注的熱點話題和主要情緒。
data = pd.DataFrame({
'Text': tweet_texts,
'Sentiment': scores
})
average_sentiment = data['Sentiment'].mean()
print(f"Twitter 上關於 Apple 的平均情緒分數為:{average_sentiment}")
def trading_strategy(sentiment_score):
if sentiment_score > 0.05:
action = 'Buy'
elif sentiment_score < -0.05:
action = 'Sell'
else:
action = 'Hold'
return action
action = trading_strategy(average_sentiment)
print(f"根據當前的市場情緒,建議的行動是:{action}")
通過本課的學習,應該對如何使用自然語言處理技術從文本數據中提取市場情緒有了初步的了解。我們還學習了如何生成文字雲,以視覺化方式展示文本數據中的關鍵詞。希望這些技能能夠幫助您在金融領域的數據分析中取得進展。
以下是本課中使用的完整程式碼,您可以直接在 Jupyter Notebook 或 Google Colab 中運行。
# 安裝必要的庫
!pip install nltk
!pip install spacy
!pip install textblob
!pip install tweepy
!pip install newspaper3k
!pip install wordcloud
!python -m spacy download en_core_web_sm
# 導入庫
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
import spacy
from textblob import TextBlob
import tweepy
from newspaper import Article
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 下載 NLTK 資源
nltk.download('vader_lexicon')
nltk.download('punkt')
# 使用 NLTK 的情緒分析器
sia = SentimentIntensityAnalyzer()
# 從新聞網站獲取文章
url = 'https://www.bloomberg.com/news/articles/2021-09-14/apple-unveils-iphone-13-new-ipads-and-watches-at-big-event'
article = Article(url)
article.download()
article.parse()
text = article.text
# 對文章進行情緒分析
scores = sia.polarity_scores(text)
print("新聞文章的情緒分析結果:")
print(scores)
# 使用 SpaCy 進行實體識別
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
print("\n文章中的命名實體:")
for ent in doc.ents:
print(ent.text, ent.label_)
# 設置 Twitter API 憑證
consumer_key = '你的消費者金鑰'
consumer_secret = '你的消費者密鑰'
access_token = '你的存取權杖'
access_token_secret = '你的存取權杖密鑰'
# 認證並建立 API 物件
auth = tweepy.OAuth1UserHandler(consumer_key, consumer_secret, access_token, access_token_secret)
api = tweepy.API(auth)
# 搜索推文
tweets = api.search_tweets(q='Apple', lang='en', count=100)
tweet_texts = [tweet.text for tweet in tweets]
# 對推文進行情緒分析
scores = [sia.polarity_scores(text)['compound'] for text in tweet_texts]
# 可視化情緒分佈
plt.hist(scores, bins=20)
plt.title('Twitter 上關於 Apple 的情緒分佈')
plt.xlabel('情緒得分')
plt.ylabel('推文數量')
plt.show()
# 生成文字雲
text_combined = ' '.join(tweet_texts)
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text_combined)
plt.figure(figsize=(15, 7.5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Twitter 上關於 Apple 的文字雲', fontsize=20)
plt.show()
# 建立資料框並計算平均情緒分數
data = pd.DataFrame({
'Text': tweet_texts,
'Sentiment': scores
})
average_sentiment = data['Sentiment'].mean()
print(f"Twitter 上關於 Apple 的平均情緒分數為:{average_sentiment}")
# 定義交易策略
def trading_strategy(sentiment_score):
if sentiment_score > 0.05:
action = 'Buy'
elif sentiment_score < -0.05:
action = 'Sell'
else:
action = 'Hold'
return action
# 測試交易策略
action = trading_strategy(average_sentiment)
print(f"根據當前的市場情緒,建議的行動是:{action}")

