今天我們終於要來做 RAG 了。我們很快就會看到其實在客服性質裡的場景,RAG 的效果會比 Fine Tune 好上很多。
我們接著來寫程式吧!
from langchain_community.vectorstores import Qdrant
from qdrant_client import QdrantClient
from qdrant_client.http import models
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from azure_ml_embeddings import AzureMLEndpointEmbeddings
from langchain_community.llms.azureml_endpoint import (
AzureMLOnlineEndpoint,
CustomOpenAIContentFormatter,
)
這些套件要特別注意的是 AzureMLOnlineEndpoint 和 AzureMLEndpointEmbeddings 是我客製過,可以參考 Day 11 和 Day 23 的文章。
cohere_embed_api_key = "xx"
cohere_embed_url = "https://Cohere-embed-v3-multilingual-yqv.westus3.models.ai.azure.com/embeddings"
qdrant_url = "https://xx.cloud.qdrant.io:6333"
qdrant_api_key = "xx"
llama_url = "https://Meta-Llama-3-1-8B-Instruct-dkdel.westus3.models.ai.azure.com/v1/chat/completions/"
llama_api_key = "xx"
llm = AzureMLOnlineEndpoint(
endpoint_url=llama_url,
endpoint_api_type='serverless',
endpoint_api_key=llama_api_key,
content_formatter=CustomOpenAIContentFormatter(),
model_kwargs={"temperature": 0.8},
)
embeddings_model = AzureMLEndpointEmbeddings(embed_url=cohere_embed_url, api_key=cohere_embed_api_key)
prompt = ChatPromptTemplate.from_template("""你是電子元件公司的客服,請回答依照 context 裡的資訊來回答問題,超過範圍的請不要回答:
<context>
{context}
</context>
Question: {input}""")
client = QdrantClient(
url=qdrant_url,
api_key=qdrant_api_key
)
collection_name = "ironman2024"
qdrant = Qdrant(client, collection_name, embeddings_model)
retriever = qdrant.as_retriever()
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({"input": "請問MicroBoard MB1000的資訊"})
print(response)
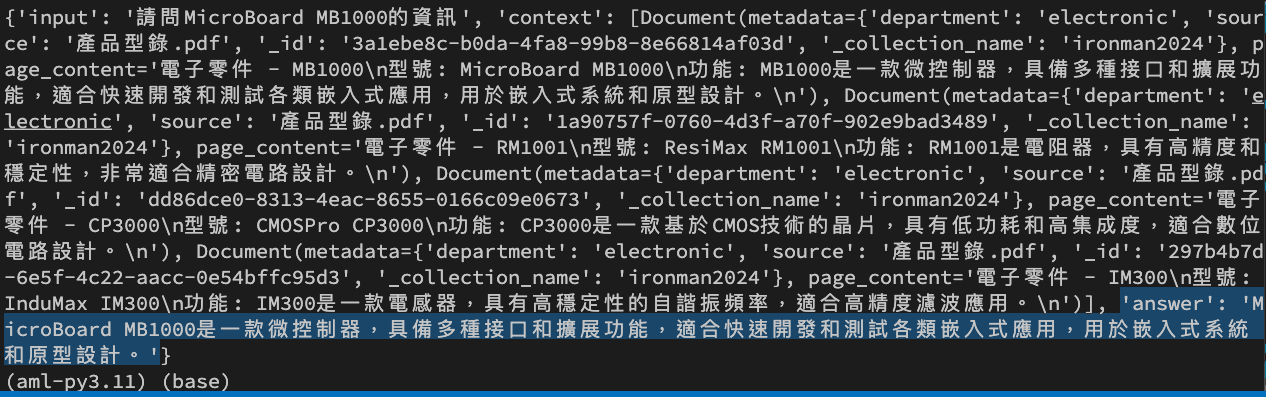
我們透過 RAG 的手法,不必再 Fine Tune 模型,而且可以精準地拿到我們所要的答案。
反觀在 Day 18 時,我們使用了 Fine Tune 後的模型,雖然有正確拿到 MB 1000 的資訊,但是卻產生了 MC 1000 和 PB 1000 不在我產品型錄裡的幻覺。
因此建議大家再回去看看 Day 13 談論 Fine Tune 的場景的文章,思考自己的應用是不是用 RAG 可以又快又便宜。


 iThome鐵人賽
iThome鐵人賽