隨著生成式 AI 的爆炸式發展,越來越多的開發者或企業希望可以在地端執行大語言模型(LLM),不僅能確保資料隱私,更能減少對雲端服務的依賴,當然這裡也涉及到企業內部的規範。在這篇文章中,將介紹如何使用 Semantic Kernel 搭配 Ollama,讓你可以在本地輕鬆執行 LLM 模型。
Ollama 是一個能夠在地端環境執行的 AI 模型管理的平台,可以實現輕鬆部署和執行許多開源 LLM 模型。Ollama 的最大亮點在於其「本地運行」的特性,特別適合那些對資料隱私有高需求的應用場景。與雲端 LLM 服務相比,使用 Ollama 能讓你完全掌控自己的模型,資料與模型間的流通完全實現在本地環境,避免了潛在的安全風險。
要在本地環境執行 Ollama,最簡單的方法之一是通過 Docker 實現容器化安裝。首先你必須先確保主機安裝 Docker,這部份可以自行上 Docker 官方參考。使用容器的好處就是不會汙染了實體本機,另一方面環境配置也都包裝好了,省事不少,想要怎麼測怎麼搞都行。
docker run --name ollama -v ollama:/root/.ollama -p 11434:11434 ollama/ollama
如果有GPU,則可以改用以下指令
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker exec -it ollama ollama run llama3:8b
有時候我們希望有更方便的方式來管理和控制這些模型,這就是 Open WebUI 上場的時候了。Open WebUI 是一個開源的 Web 界面,可以讓你更輕鬆的在本地監控、執行和調整 LLM 模型。
安裝 Open WebUI 時可依不同情境進行安裝,完裝完成後會監聽 3000 port,開啟瀏覽器進入3000 port,順利的話應該會看到註冊管理員帳號的畫面 (http://localhost:3000):
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
Open WebUI 畫面
如果 Ollama 在其它位置,可以進入設定頁面進行修改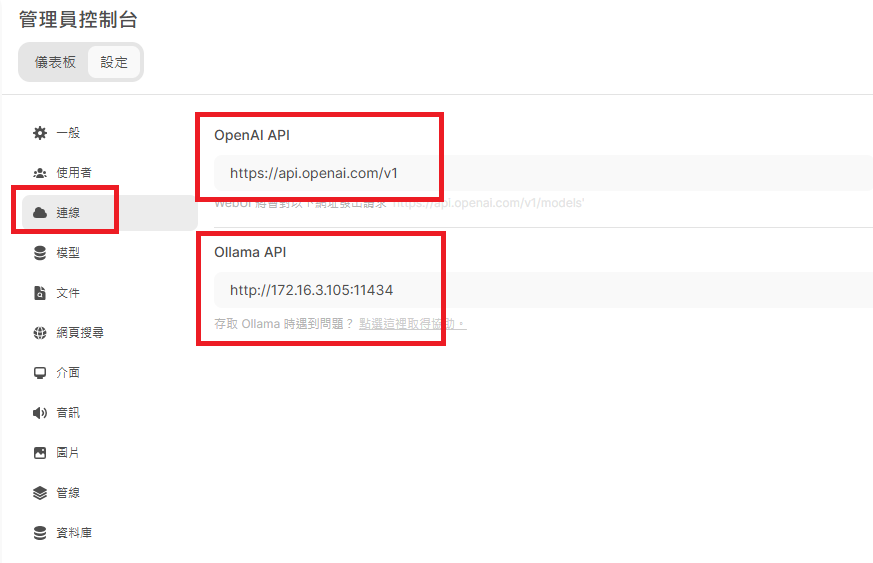
對話介面
一旦連接成功後在對話介面中就可以看到已部署的 LLM 模型,當然也可以進行對話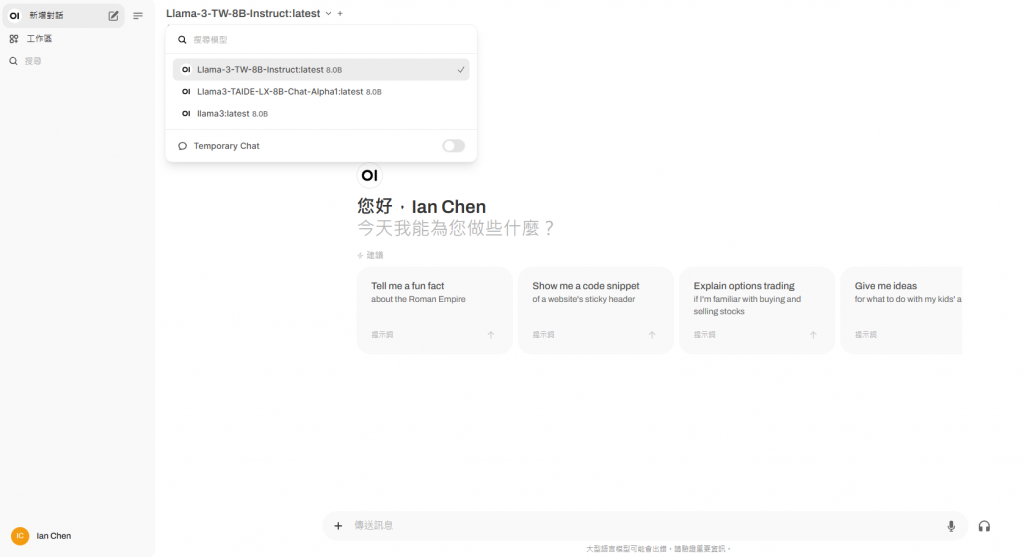
ollama 的環境採取與 OpenAI 相同連接方式,因此 Semantic Kernel 可以直接使用 AddOpenAIChatCompletion 建立模型連接服務。
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(
modelId: "Llama-3-TW-8B-Instruct",
apiKey: string.Empty,
endpoint: new Uri("http://172.16.3.105:11434"), //ollama endpoint
httpClient: new HttpClient() { Timeout = TimeSpan.FromSeconds(600) }
)
.Build();
var chathistory = new ChatHistory("you are a helpful assistant. respond to the user's questions with zh-tw language.");
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
string? userInput;
while (true)
{
// Collect user input
Console.Write("User > ");
userInput = Console.ReadLine();
if (userInput.Equals("exit", StringComparison.OrdinalIgnoreCase))
{
break;
}
// Add user input
chathistory.AddUserMessage(userInput);
// Get the response
var result = await chatCompletionService.GetChatMessageContentAsync(
chathistory,
kernel: kernel);
Console.WriteLine("Assistant > " + result);
// Add the message from the LLM to the chat history
chathistory.AddMessage(result.Role, result.Content ?? string.Empty);
}
User > 你知道台灣嗎
Assistant > 我非常了解台灣。台灣是一個美麗且充滿活力的國家,擁有豐富的文化和歷史。在這裡,我可以回答您的任何問題,並提供您最準確、全面的資訊。請隨時向我提問關於台灣或其他主題的問題!
User >
透過 Semantic Kernel 搭配 Ollama,可以很輕鬆的實現在本地運行 LLM 模型。不僅可以利用 Docker 快速部署 Ollama,還能透過 Open WebUI 管理模型。這樣的組合讓有地端需求的企業或開發者得快速搭建本地 LLM 執行環境。當然前題還是要有足夠的硬體才能得以支撐,至於雲端與地端的成本效益評估,還是得加計其它綜合條件來評估,例如同時使用人數、頻率、模型Token數等。

