昨天我們學習到了Self-attention的技術,我們還説到今天會介紹Self-attention更進階一點的變體,稱為Multi-head Self-attention。這篇文章將解釋Multi-head Self-attention的概念及其優勢。
Self-attention的概念是透過計算每個input與sequence中其他輸入的相似度,來決定每個輸入對最終結果的貢獻。在Self-attention中,會計算query (q) 和 key (k) 之間的相似度,並根據這個相似度對value (v) 進行加權求和。這樣的機制讓Self-attention在捕捉序列中各元素之間的關聯性上非常有效。
然而,基本的Self-attention在某些任務中可能不夠靈活,因為它僅使用單一的q來計算相似性。而不同的任務和數據集可能需要捕捉不同種類的關聯性,這時就會需要用到Multi-head Self-attention。
Multi-head Self-attention的核心概念是透過多個獨立的head,每個head都可以學習不同的關聯模式。因此,不同的head可以專注於不同的特徵,從而提高模型的表現。
Multi-head Self-attention的計算過程:
Query, Key, Value矩陣的生成:首先,跟一般的Self-attention是沒有任何區別的,都需要將輸入資料與三個不同的矩陣(Q, K, V)進行線性變換,分別得到query矩陣(q)、key矩陣(k) 和value矩陣(v)。接著,根據head的數量,對這些矩陣進行進一步變換,產生每個head對應的q、k、v。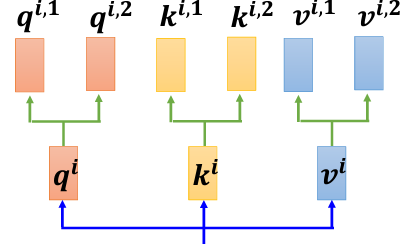
Attention Score計算:對每個head,分別計算query與key之間的相似度,並根據這些相似度來對value進行加權平均。這個過程稱為scaled dot-product attention,也就是對每個head,計算: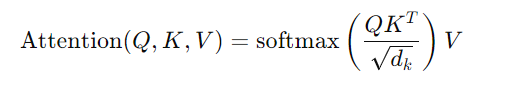
其中,d_k是input vector的長度,用來對計算的結果進行縮放,避免數值在softmax函數的時候,數值會向兩端靠攏。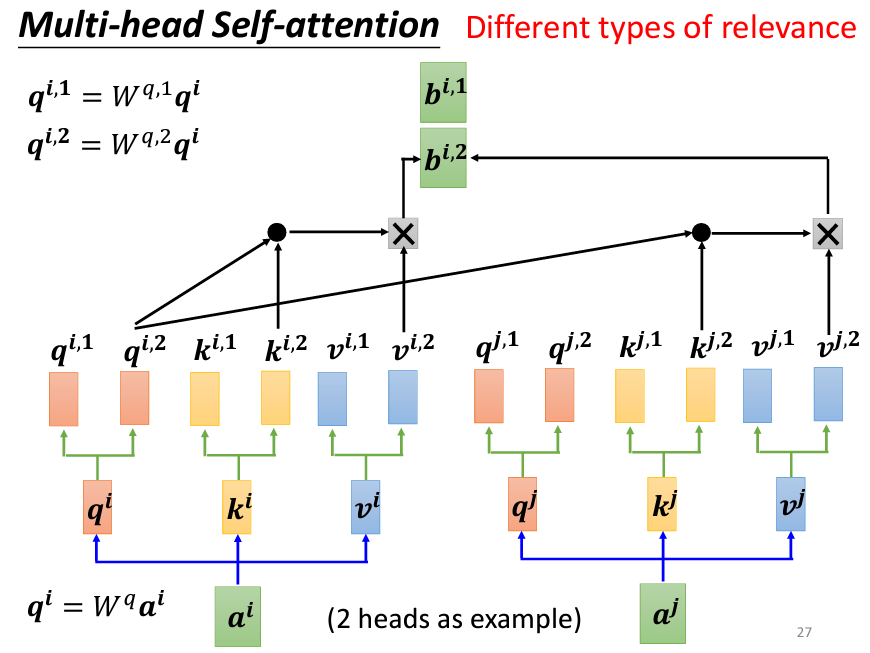
Head的合併:在所有head完成Attention計算後,將每個head的輸出拼接在一起,並通過一個線性變換,得到最終的輸出。這樣可以保留每個head的特徵,並綜合它們的結果。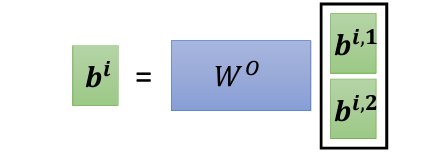
使用多個head的原因在於,關聯性(即Self-attention中計算的q和k的相似度)有許多不同的形式。不同的head可以專注於不同類型的關聯性,從而使模型能夠更靈活地處理複雜的輸入數據。例如,在翻譯或語音識別等任務中,多head可以捕捉到不同層次的語義或聲學特徵,進而提升結果的品質。
雖然Self-attention在捕捉序列元素之間的關聯性上表現的很不錯,但它有一個關鍵的問題:無法識別輸入的相對位置。在Self-attention的運作中,每個元素的位置(例如,它是序列中的第一個還是最後一個)對於Attention的計算沒有任何影響,這可能在某些情況下帶來問題。比如在詞性標註(POS tagging)任務中,動詞通常不會出現在句首,這樣的位置資訊可能對於模型預測很重要。
為了解決這個問題,我們可以引入了Positional Encoding這一個技術。Positional Encoding為每個位置生成一個向量,並將該向量加到對應位置的輸入上,從而將位置信息引入模型。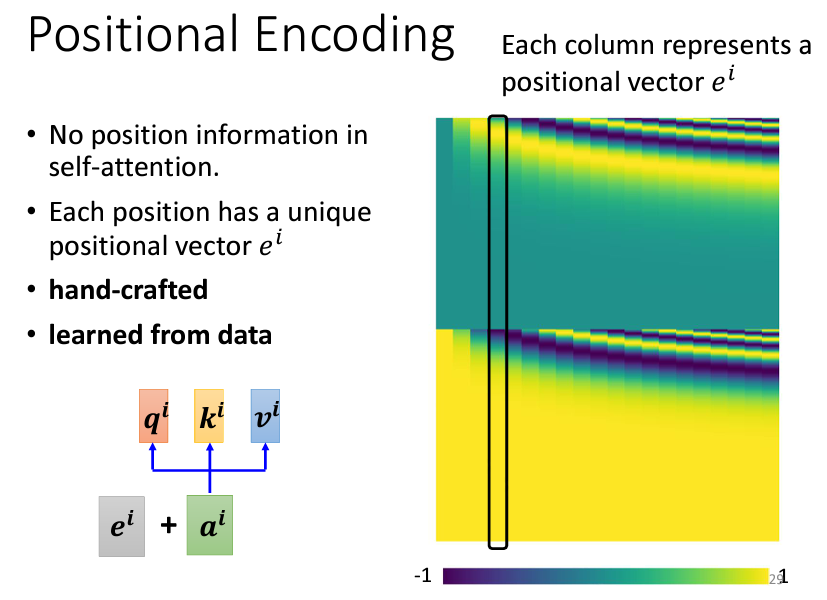
Transformer 原始論文 Attention Is All You Need 中的Positional Encoding使用了一個基於sin和cos函數的公式來生成這些位置向量。這種方式可以確保即使序列長度超出預定範圍,位置向量也可以依照公式擴展。
儘管sin和cos函數生成的Positional Encoding在Transformer模型中表現良好,但這種handcrafted的方式並不是唯一的選擇。近期的研究提出了許多新的Positional Encoding方法,這些方法不再依賴手工設計,而是根據數據學習出來的。例如,使用Recurrent Neural Networks (RNN)或其他神經網路來生成Positional Encoding已經成為一個熱門的研究。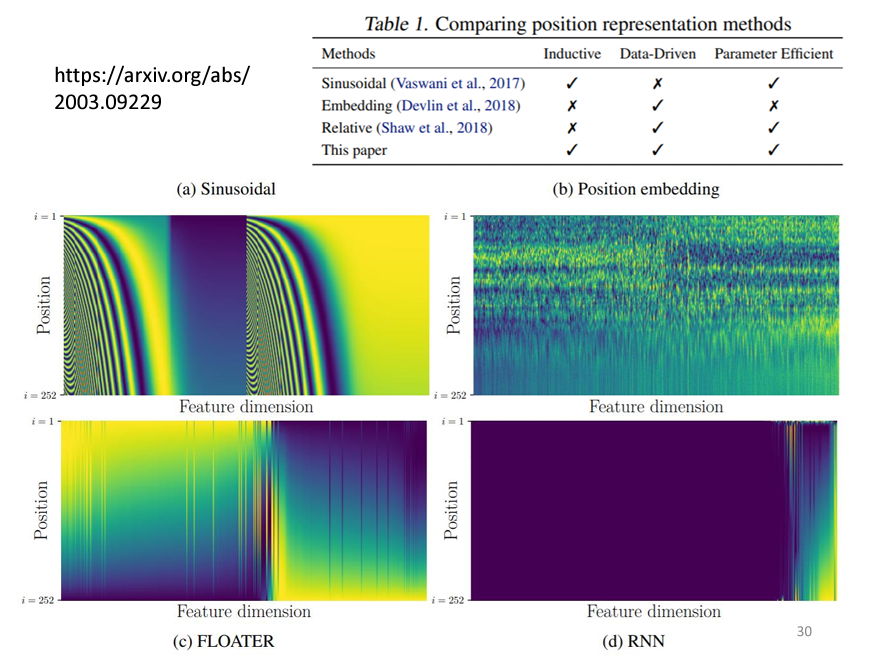
Self-attention 被 Transformer 模型發揚光大,被大量用於 NLP 任務中如機器翻譯、文本生成等。BERT 等模型也利用 Self-attention 來處理文本序列,讓模型能夠在句子中不同位置的詞之間建立關聯,並捕捉上下文信息。Self-attention 讓模型更容易學習長距離的依賴關係,相較於傳統的 RNN 和 LSTM,它能在不增加計算步驟的情況下平行處理輸入。
Self-attention 同樣在語音處理中發揮重要作用,尤其是在語音辨識或語音生成等任務中。不過,語音訊號通常會轉換成非常長的向量序列,這使得計算 Self-attention 的注意力矩陣變得昂貴。為此,語音處理中常使用 Truncated Self-attention,即僅考慮訊號的局部範圍,而不是整段語音的全局信息,這能有效減少計算負擔,並且在某些情境下局部信息就已足夠進行辨識。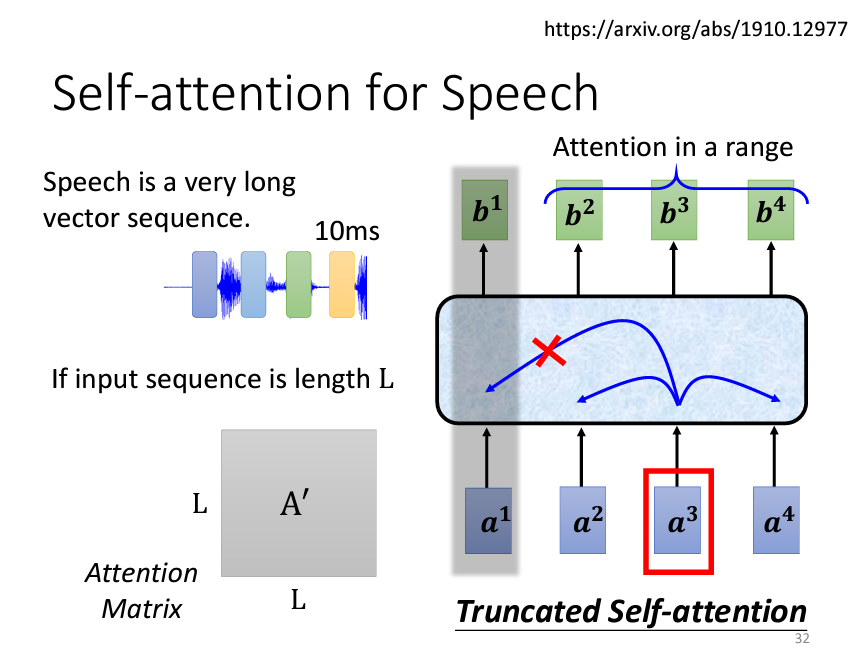
Self-attention 也被應用於影像處理。雖然影像傳統上使用卷積神經網路 (CNN) 來提取特徵,但近來的研究表明 Self-attention 可以提供更靈活的特徵提取方式,讓模型能夠全局考慮影像中所有像素的關聯性。例如,Google 的 "An Image Is Worth 16x16 Words" 研究將圖片分割成 16x16 個小區域(patch),並將每個區域視作類似 NLP 中的「詞」,進而應用 Self-attention 機制來學習這些 patch 之間的關聯性。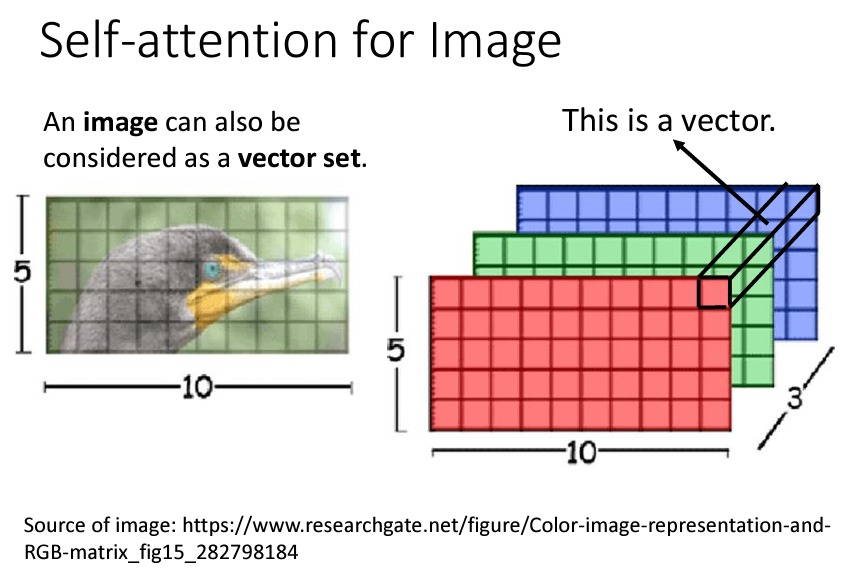
相比 CNN,Self-attention 更加靈活,因為 CNN 依賴於手動設置的 receptive field 來限制每個卷積核感知的範圍,而 Self-attention 則是通過學習自動決定哪些像素是相關的。
因此,可以認為 CNN 是 Self-attention 的簡化版,而 Self-attention 可以視為 CNN 的更高階形式,特別是在資料量充足時,Self-attention 通常能比 CNN 更好地捕捉影像中長距離的依賴關係。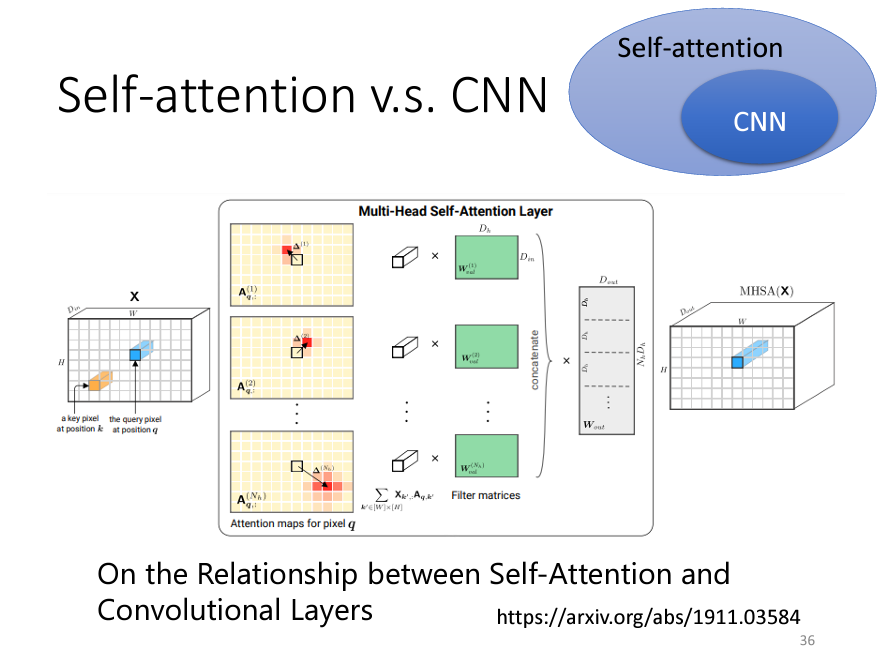
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。


 iThome鐵人賽
iThome鐵人賽