昨天我們談到Decoder的運作方式,它與Encoder有許多相似之處:同樣需要進行Positional Encoding、Multi-Head Self-Attention,以及Add & Norm(即Residual => 新output + 舊input加上Layer Normalization)。然而,Decoder多了一個關鍵部分,這部分我們稍後會詳細介紹。在這部分之後,處理過的向量也會送入一個全連接的Feedforward Network,然後再次經過Add & Norm。
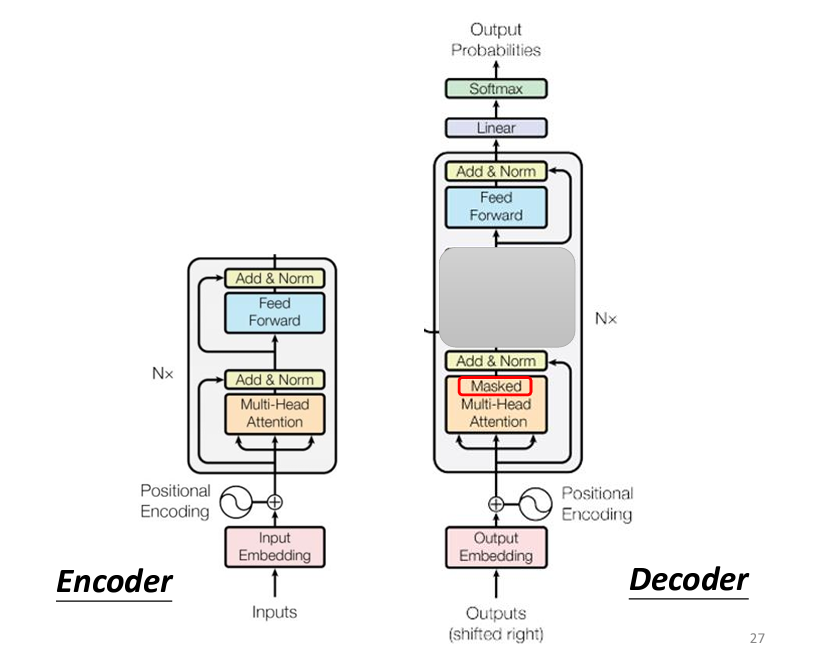
我們也提到,Decoder的Multi-Head Self-Attention與普通的Self-Attention不同,它是「Masked」的Self-Attention,這意味着模型在每一步生成輸出的過程中,只會考慮當前步驟之前的輸入。例如,當輸入語音【機器學習】並希望輸出對應文字【機器學習】時,Autoregressive Decoder會逐字生成:首先讀取特殊符號BEGIN並輸出【機】,然後將【機】作為新的輸入生成【器】,如此循環。在【BEGIN、機、器】階段,模型只會考慮這三個字,因為【學、習】尚未生成。
此外,所有輸出都以One-Hot Vector表示,我們會在向量中加入一個特殊符號。當經過Softmax函數後,若生成此特殊符號,模型將停止輸出,這使得模型能夠自動決定輸出序列的長度,這正是Seq2Seq模型的核心精髓。
我們這幾天探討了Transformer模型中的Encoder和Decoder的運作機制,但Decoder的關鍵部分尚未介紹。正如前面提到的,Decoder相較於Encoder多出的一部分,就是Cross Attention,這個部分至關重要,因為它是Encoder和Decoder之間的橋樑。接下來,我們將解釋Cross Attention的具體運作方式。
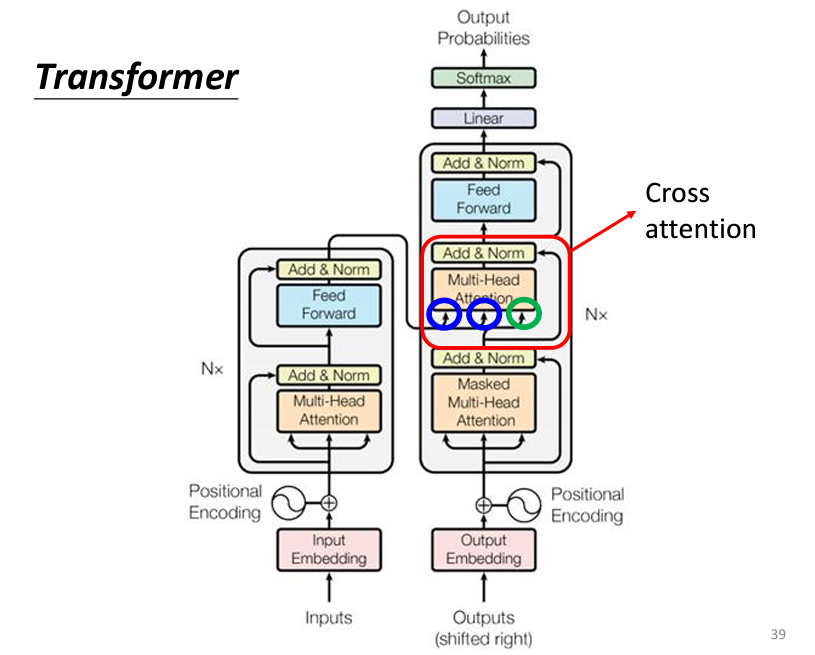
通過原始論文的架構圖,我們可以發現在Cross-Attention的部分,有兩個input是從Encoder來的,而有另外一個input是來自Decoder自己的:
Decoder的初始輸入:
Decoder 的輸入一開始是 BEGIN(BOS,Begin of Sentence)。這個特別的標記會經過 Self-Attention 層(有mask的,保證模型只關注已生成的詞),並生成一個初始向量。我們稱這個向量為q(Query)。這個q向量代表的是Decoder想要去查詢的信息。
Cross-Attention:
Key (k) 和 Value (v):這兩個都是來自 Encoder 的輸出。在Encoder的輸出向量中,對每個位置的詞(例如a1, a2, a3),都會計算出q向量對應的Key向量(k1, k2, k3)和Value向量(v1, v2, v3)。Key向量用來計算注意力分數,Value向量則用來進行加權求和(weighted sum)。
接下來,Decoder的q向量與Encoder產生的Key向量(k1, k2, k3)進行點積,計算Attention分數。具體的計算公式是: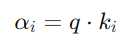 這個分數代表了Decoder對Encoder輸出中每個位置的關注程度。然後我們一樣將這個Attention Score乘上Encoder的每個
這個分數代表了Decoder對Encoder輸出中每個位置的關注程度。然後我們一樣將這個Attention Score乘上Encoder的每個v_i向量,最終我們得到了一個v向量。
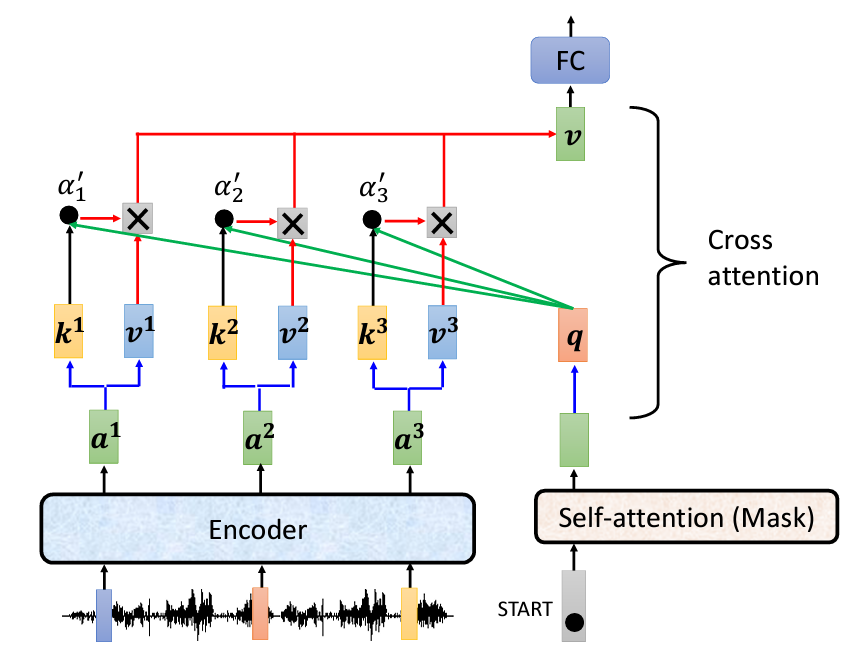
最後我們還會將我們得到的向量送進一個Feedforward的Fully Connected Network裏面,再做一次Add & Norm,然後我們就會進行 Softmax,這樣可以將分數標準化,保證它們的總和為1。這個過程確保了不同位置之間的權重分配,然後我們會將這個One-Hot Vector裏面機率最大的文字挑選出來,得到我們最終輸出的一個文字。
接下來我們繼續重複以上的步驟,將得到的向量稱作v'向量,周而復始,我們就會得到完整的輸出:
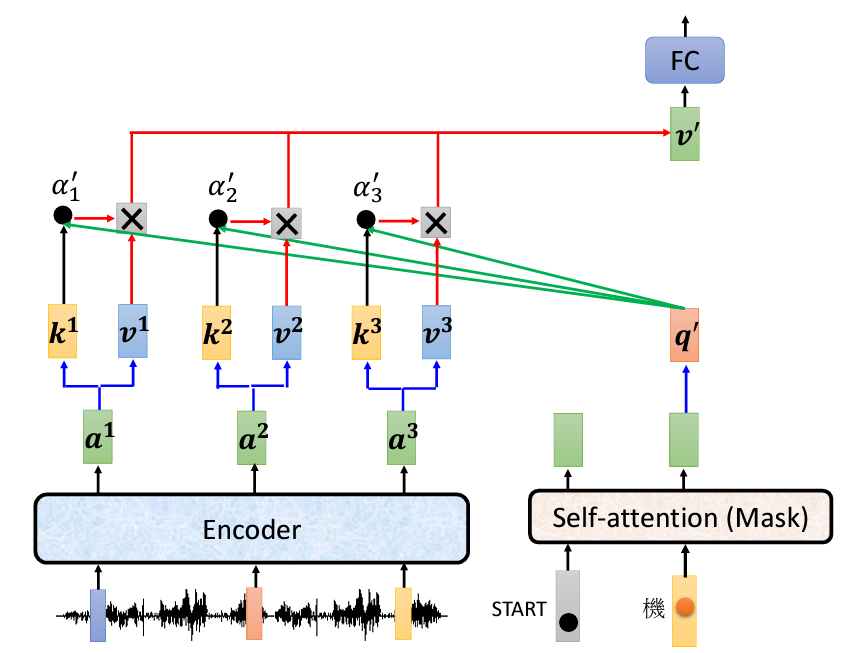
當生成第一個詞後,Decoder會將這個詞作為下一個輸入,重複上述的 Cross-Attention 過程。比如當Decoder生成「你」後,這個詞會成為下一個輸入,計算新的一個Query,再次和Encoder的Key、Value交互,繼續生成下一個詞。
這就是 Cross-Attention 如何在 Encoder-Decoder 架構中將Encoder的上下文信息傳遞到Decoder,從而幫助Decoder逐步生成正確的輸出序列。
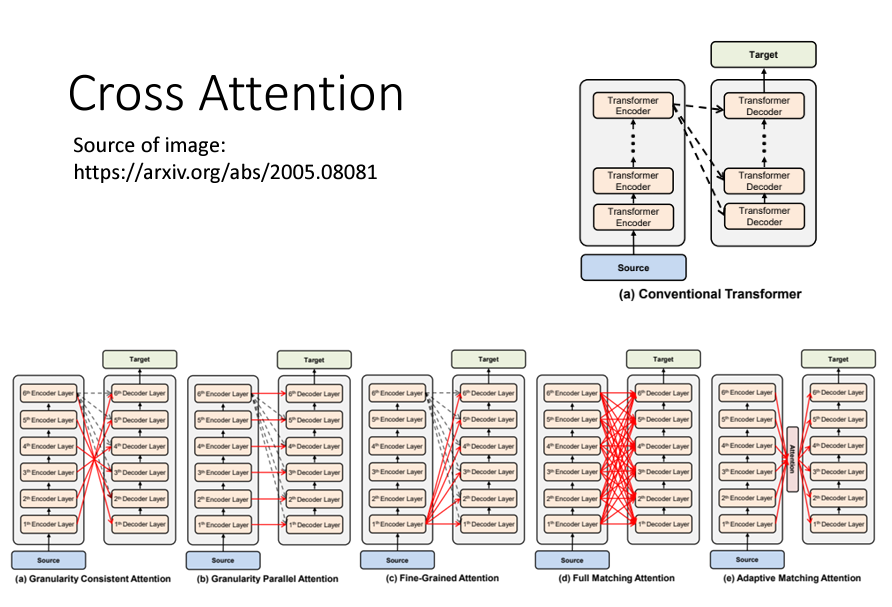
在原始的Transformer架構中,Encoder和Decoder都是堆疊了多層的Self-Attention和Feed-Forward層。每個Decoder層中的Cross-Attention,都是對應地使用 Encoder最後一層的輸出 進行計算:
這種設計之所以可行,是因為Encoder的最後一層已經包含了源序列的豐富上下文信息。這些信息經過多層Self-Attention的處理後,應該已經高度凝練了序列中每個詞的語義及其關係,因此將其提供給Decoder的每一層進行使用,能夠有效地幫助生成目標序列。
儘管原始的設計將Decoder的每一層都基於Encoder的最後一層輸出,但這不是唯一的選擇。可以嘗試各種不同的設計來進行研究,並且有研究表明可以通過不同的方式改進模型性能。例如:
這種架構的設計可以作為研究新模型的方向,甚至可以改善模型在某些特定任務中的表現。


 iThome鐵人賽
iThome鐵人賽