Transformer 是一種序列到序列 (Sequence-to-Sequence, Seq2Seq) 的模型, Sequence-to-Sequence 是前面幾篇提到的 Self-Attention 的其中一種 output, 還記得我們説 Self-Attention 的 output 一共有三種,輸入和輸出一樣長的叫做 Sequence Labeling; 第二個輸入一段 sequence 只給你一個 label; 第三個由model自己決定要輸出多少長度的sequence, 就叫做Sequence-to-Sequence, 也就是我們今天的主角——Transformer了。
Transformer經常用於處理自然語言處理 (NLP) 任務,例如語音辨識、機器翻譯和聊天機器人。我們今天將介紹 Transformer 的基本概念。
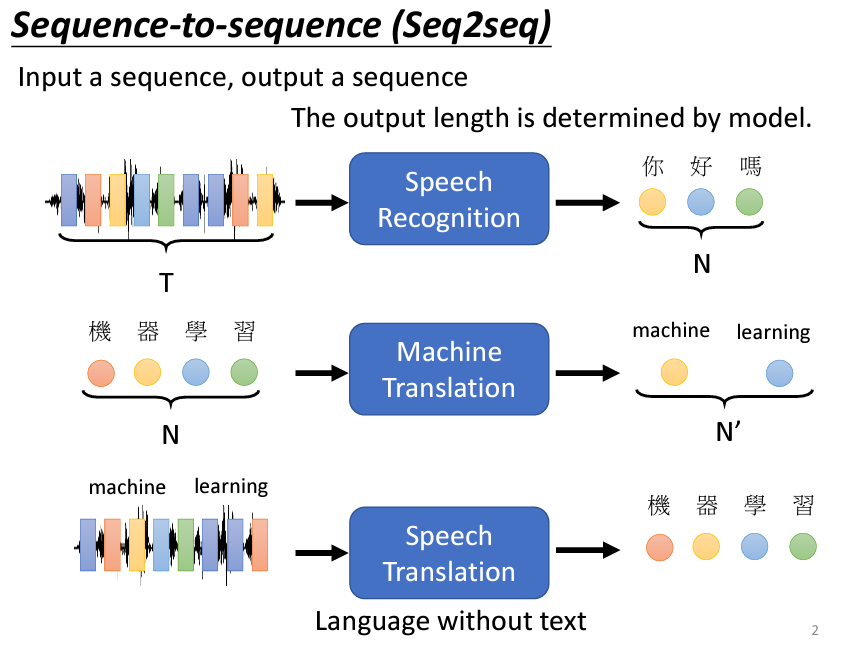
Transformer 被用來處理輸入與輸出皆為序列的問題。例如,在語音識別中,輸入是一段聲音信號,輸出是其對應的文字,這兩者的長度不固定,因此需要模型自行決定輸出的長度;在機器翻譯任務中,輸入是一句語言的句子,而輸出則是其翻譯後的句子。模型需要根據輸入的句子決定輸出的長度,這種特性對於多語言翻譯來説非常重要;語音翻譯是一種更為複雜的任務,要求模型同時進行語音識別和翻譯。例如,當用戶說出一個英文短語時,模型需要將其轉換為另一種語言的文字,這對於那些沒有文字書寫系統的語言尤為重要。
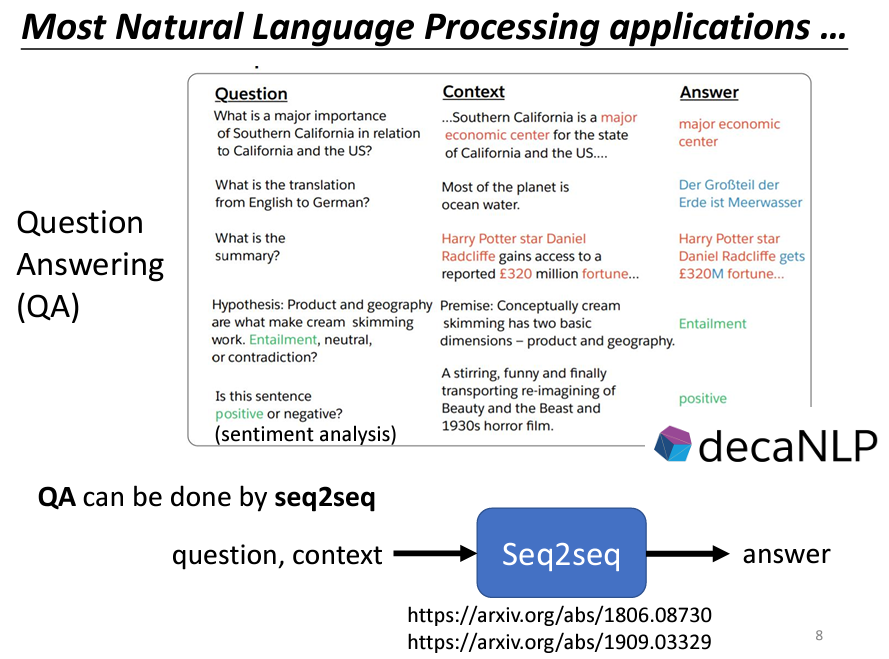
許多自然語言處理(NLP)任務實際上可以被視為問答(QA)任務。所謂的問答,就是讓機器閱讀一段文字後,回答我們提出的問題。許多看似與問答無關的任務,其實也能被想像成 QA。例如,假設我們的任務是翻譯,機器所閱讀的文本是一個英文句子,而問題則是「這個句子的德文翻譯是什麼?」機器的輸出就是該句子的德文翻譯。
再如,自動摘要的任務中,機器需閱讀一篇長文,並將其要點提煉出來。在這種情況下,我們可以提出問題:「這段文字的摘要是什麼?」期望機器能給出一個合適的摘要。
此外,情感分析(Sentiment Analysis)也是一個與問答相關的應用。情感分析的目的是自動判斷一個句子的情感屬性是正面還是負面。例如,當一個產品上線後,想了解網友的評價,就可以建立一個情感分析模型。當發現某篇文章提到該產品時,可以將該文章輸入模型,以判斷其情感是正面還是負面。在這裡,我們的問題是:「這個句子是正面還是負面?」期待機器給出明確的答案。
因此,各種NLP任務都可以被視為問答問題,而這些問答問題可以利用Seq2Seq模型來解決。具體來說,可以將問題與文章結合在一起作為Seq2Seq模型的輸入,並輸出問題的答案。由於Seq2Seq模型的特性,它能夠處理這種輸入輸出格式,實現從一段文字生成另一段文字的功能。
不過,需要強調的是,對於大多數NLP任務或語音相關任務,為這些任務量身打造的客製化模型通常能取得更好的效果。將所有問題都用Seq2Seq模型解決,就像用瑞士刀處理各種任務一樣,雖然瑞士刀功能多樣,但並不一定是最優解。因此,針對不同任務設計專屬模型,往往能獲得比單一使用Seq2Seq模型更佳的結果。
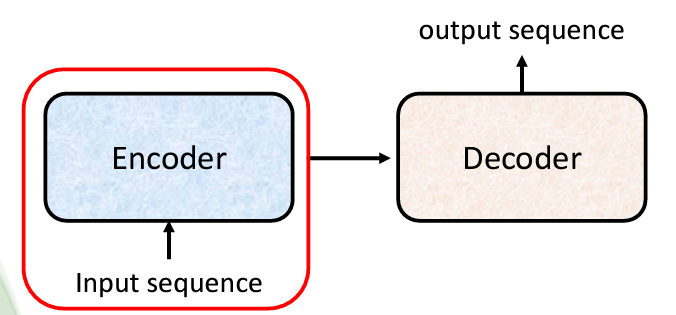
總之,Seq2Seq 模型是一個非常強大且有用的模型,我們現在就要學習如何構建 Seq2Seq 模型。一般而言,Seq2Seq 模型分為兩個部分:Encoder 和 Decoder。當你輸入一個序列時,Encoder 負責處理這個序列,然後將處理結果傳遞給 Decoder,由 Decoder 決定輸出什麼樣的序列。稍後我們將更詳細地探討 Encoder 和 Decoder 的內部架構。
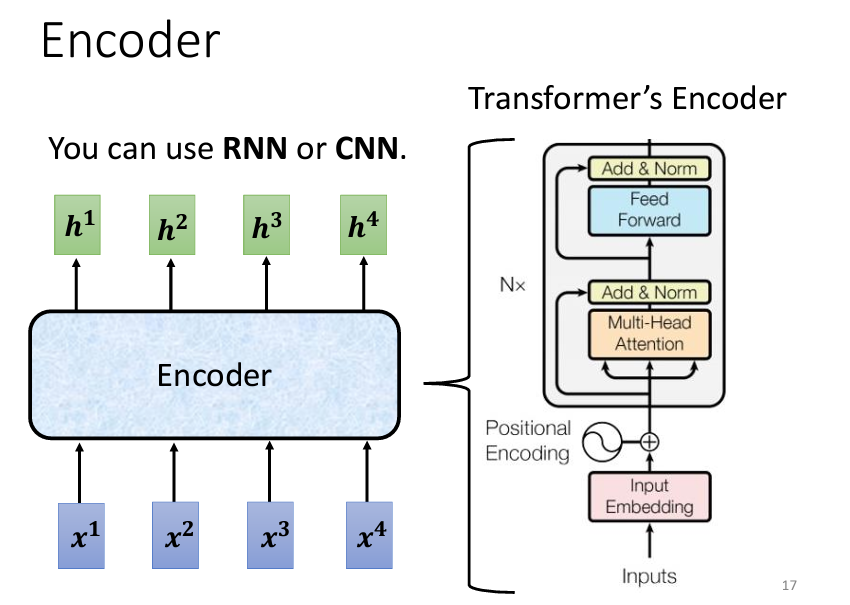
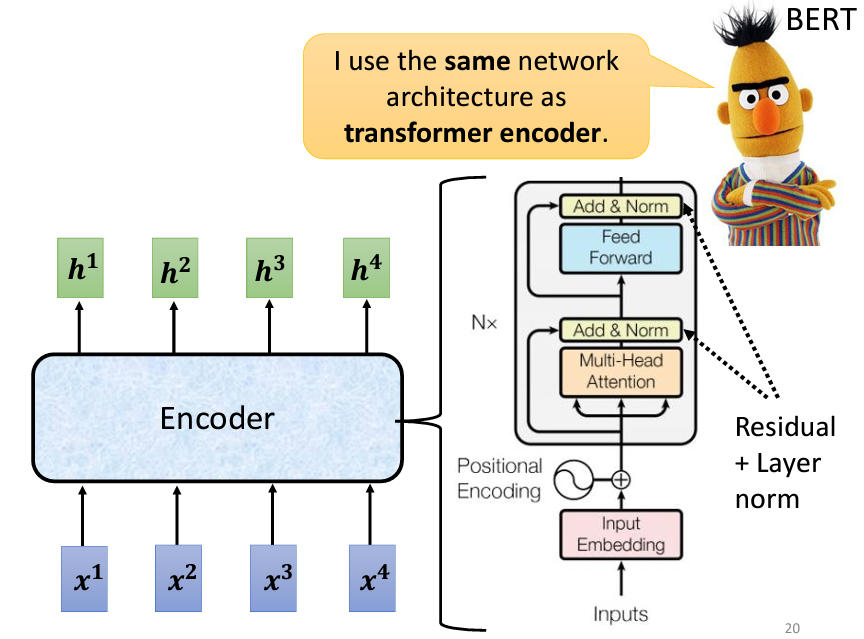
Seq2Seq 模型的起源可以追溯到2014年9月,當時有一篇將 Seq2Seq 模型應用於翻譯的論文發表在 Arxiv 上。可以想像,那時的 Seq2Seq 模型相對簡單。如今,提到 Seq2Seq 模型,大家首先想到的可能就是我們今天的主角——Transformer。Transformer 具備 Encoder 和 Decoder 架構,並包含許多精妙的模塊。下面為 Transformer 架構圖和一開始的 Seq2Seq 架構圖對比:
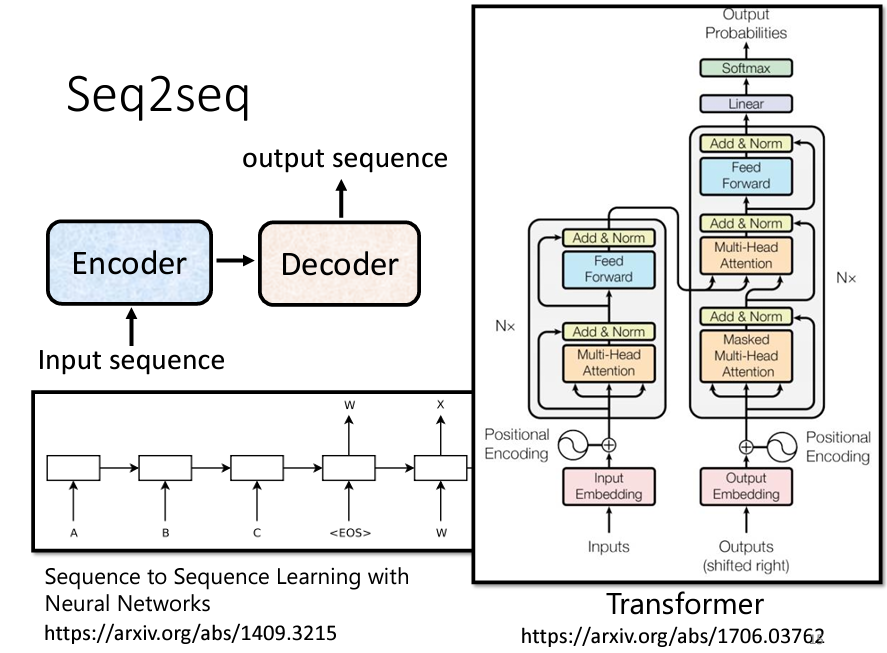
Seq2Seq 模型的 Encoder 負責將一組向量轉換為另一組向量。這個功能有很多模型都可以實現,例如 Self-Attention、RNN 和 CNN 都可以將一組向量輸入並輸出另一組同樣長度的向量。在 Transformer 中,Encoder 使用的正是 Self-Attention。這裡的架構看起來可能有些複雜,因此我們會用另一張圖來詳細解釋 Encoder 的結構,並與原始 Transformer 論文中的圖進行比較。
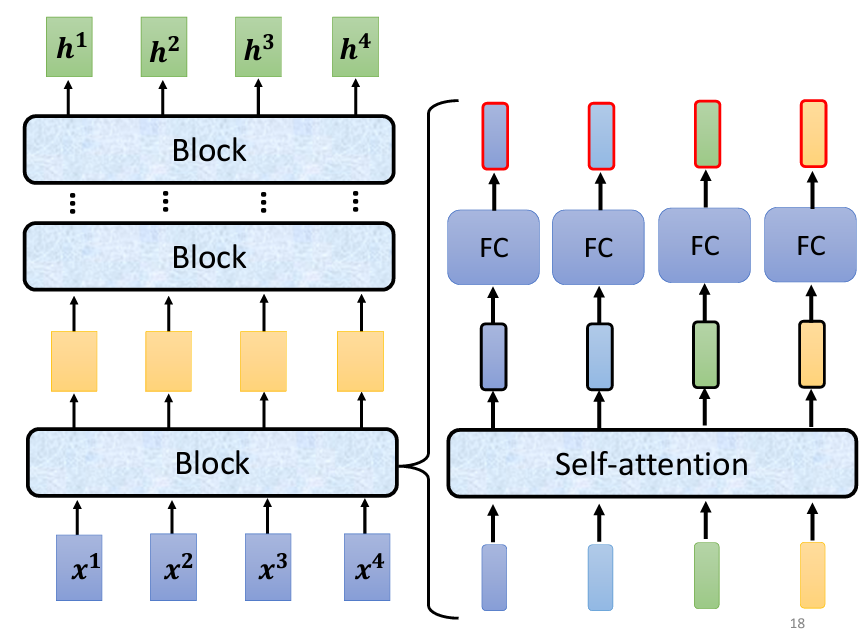
在 Transformer 的 Encoder 中,整體結構由多個 Block 組成。每個 Block 都會接收一組向量作為輸入,並輸出另一組向量。具體來說,第一個 Block 接收輸入向量並輸出一組新的向量,然後這組向量會傳遞給下一個 Block。最終,最後一個 Block 的輸出就是最終的向量序列。需要注意的是,這裡的 Block 並不是神經網絡的一層,而是包含多層的運算。
在 Transformer 的 Encoder 中,每個 Block 的處理流程大致如下:首先進行 Self-Attention,該過程會考慮整個序列的信息,然後輸出一組新的向量。接著,這組向量會傳遞至一個全連接(FC)的 Feed Forward Network (FFN),並輸出另一組向量,這就是 Block 的輸出。
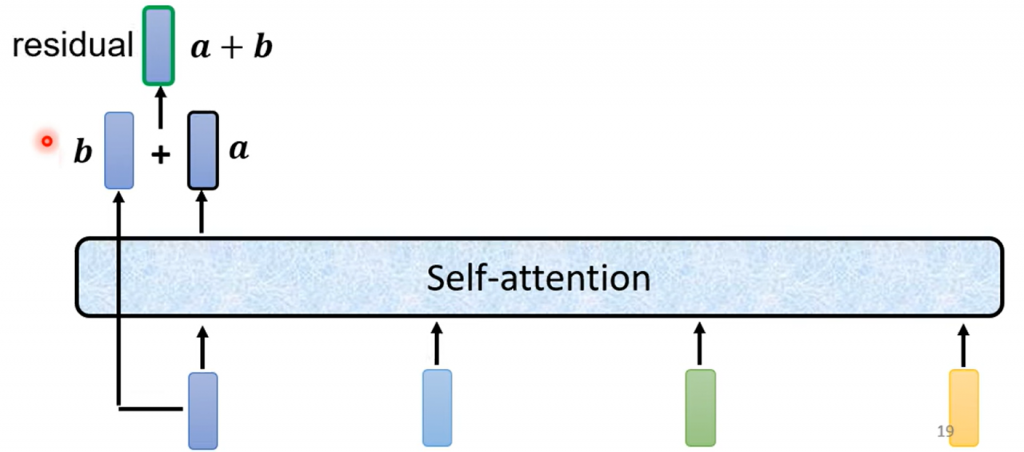
實際上,在原始的 Transformer 架構中,這個過程會更加複雜。在 Self-Attention 過程中,輸入的每一個向量都是基於所有輸入向量計算得出的。此外,Transformer 引入了一個設計,即在輸出向量中加入輸入向量,形成新的輸出。這一過程稱為 Residual Connection,這是一種在深度學習領域廣泛應用的結構,將輸入與輸出相加,以獲得更好的效果。
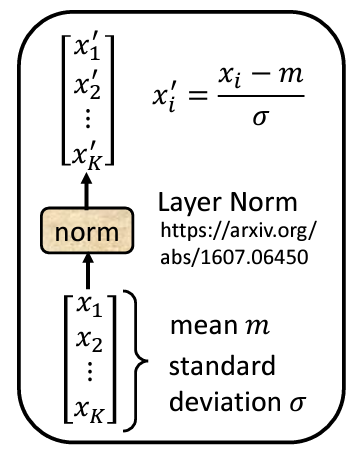
接下來,Residual Connection 之後會進行 Layer Normalization,而非 Batch Normalization。Layer Normalization 的作用是計算輸入向量的均值和標準差,並根據這些數值對輸入向量進行標準化。與 Batch Normalization 不同,Layer Normalization 不需要考慮 Batch 的信息,而是針對同一特徵中的不同維度進行計算。這樣做的結果是將原始輸入向量中的每個維度減去均值,並除以標準差,最終輸出進入 FFN 的向量。
在 FFN 中,仍然會使用 Residual Connection,並將輸入和輸出相加,最後進行一次 Layer Normalization。這樣,經過一系列的處理後,Block 的輸出就完成了。
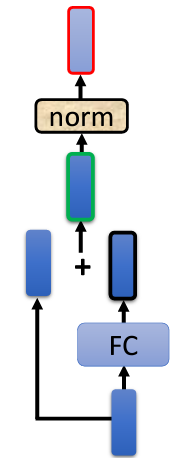
完整架構圖:
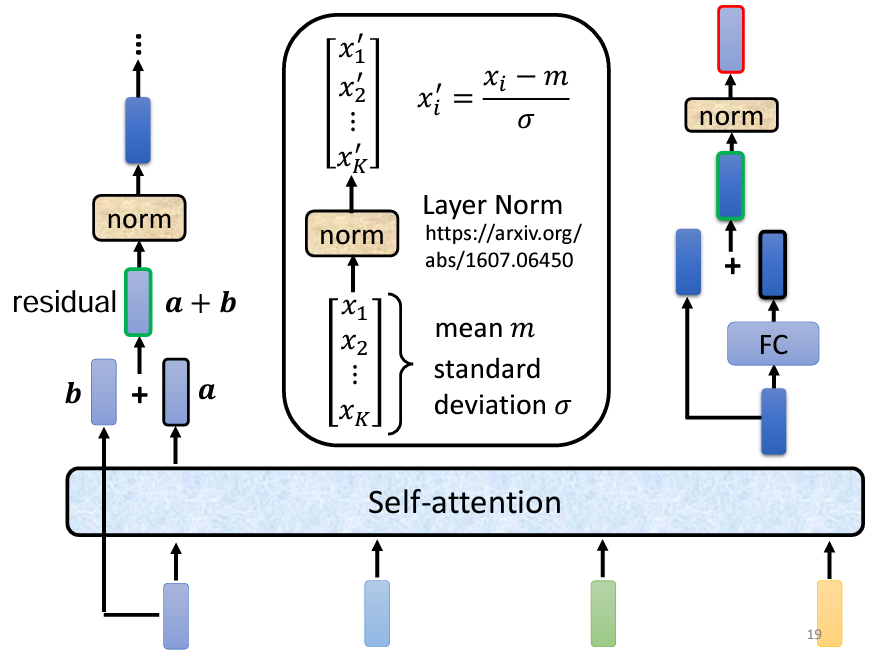
上述過程在圖示中具體表現為:
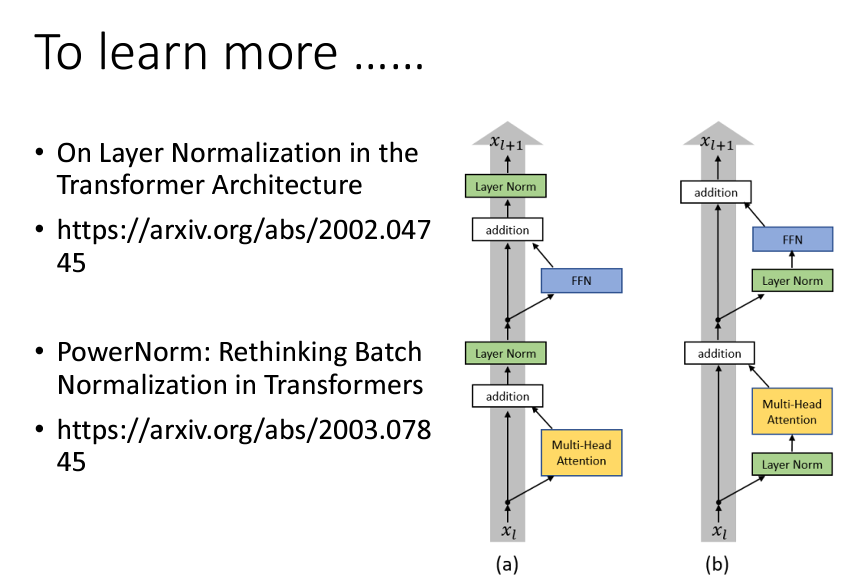
實際上,Transformer 的 Encoder 架構並不是唯一的或最優的設計。比如,有一篇名為《On Layer Normalization in the Transformer Architecture》的文章探討了 Layer Normalization 放置的位置,提出了不同的結構設計可以提高性能。圖示中左側是原始 Transformer,右側則是經過修改後的結構,改變順序後的效果會更好,顯示出原始架構並不是最佳設計。
另外,有關於為什麼選擇 Layer Normalization 而非 Batch Normalization 的問題,可以參考《Power Norm: Rethinking Batch Normalization in Transformers》這篇文章。該文章指出 Batch Normalization 在 Transformer 中的性能表現不如 Layer Normalization,並提出了一種名為 Power Normalization 的方法,其性能優於 Layer Normalization,或至少相當接近。
那麽,我們今天就到這邊,讓我們明天再繼續講解有關Decoder的運作,和整體的運作。
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。


 iThome鐵人賽
iThome鐵人賽