我們昨天提到了 Transformer 的架構,我們知道 Transformer 是由 Encoder 和 Decoder 組成的,其中的 Encoder 我們在昨天也講解過了,主要是讓 input 的 sequence 通過許多層 block,然後最後一層 block 的輸出就成爲 decoder 的輸入,而這個 block 的内部結構,就是通過一個 Multi-Head Self-Attention,并且加上 Residual 之後做 Layer Normalization,送進Fully Connected Network 後再做一次 Residual 和 Layer Normalization,這樣就是一個block的處理過程,input 會在 encoder 裏面經歷許多 block,最終才被輸出到 decoder。
Decoder 分別有兩種,以語音轉文字爲例,一個是一個一個生成文字的,這種叫做 Autoregressive Decoder(AT),另外一種是一次過生成所有文字的,叫做 Non-Autoregressive Decoder(NAT)。
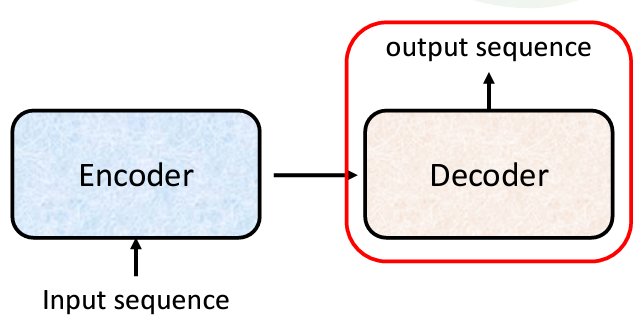
接下來我們要深入了解 Decoder 的部分,我們今天只會解釋 Autoregressive Decoder 的運作原理。這種 Decoder 在語音辨識和機器翻譯等應用中非常常見,他們的原理是相似的,都是輸入一些信號,然後生成對應的輸出。
我們知道 Decoder 是需要先從讀取 Encoder 的輸出當作輸入,但是怎麽從 Encoder 讀取數據,具體情況我們先不説,我們先假設 Decoder 已經把數據讀進來,在一步一步解釋 Encoder 的輸出在這其中的作用
Decoder 開始運作時,會需要一個特殊的符號來標識輸出的開始,這個符號通常稱為 Begin Of Sentence (BOS)。在實際的運作中,每個 Token 會以 One-Hot 向量的形式表示,其中一維為 1,其他維度為 0。接下來,Decoder 會輸出一個 Vector,這個 Vector 的長度跟所有的 Vocabulary 的 Size 加起來是一樣的,意思是説假設我們今天做的是中文的語音辨識,我們 Decoder 輸出的是中文,那 Vocabulary 的 Size 就是中文的方塊字的數目,常用的中文的方塊字大概兩、三千個, 一般人可能認得的四、五千個,所以就看看說要讓 Decoder 輸出哪些可能的中文的方塊字就把它列在這邊。在產生這個向量之前,通常會先跑一個 Softmax 就跟做分類一樣,所以這個向量裡面的分數是一個 Distribution,也就是這個向量裡面的值全部加起來總和會是 1。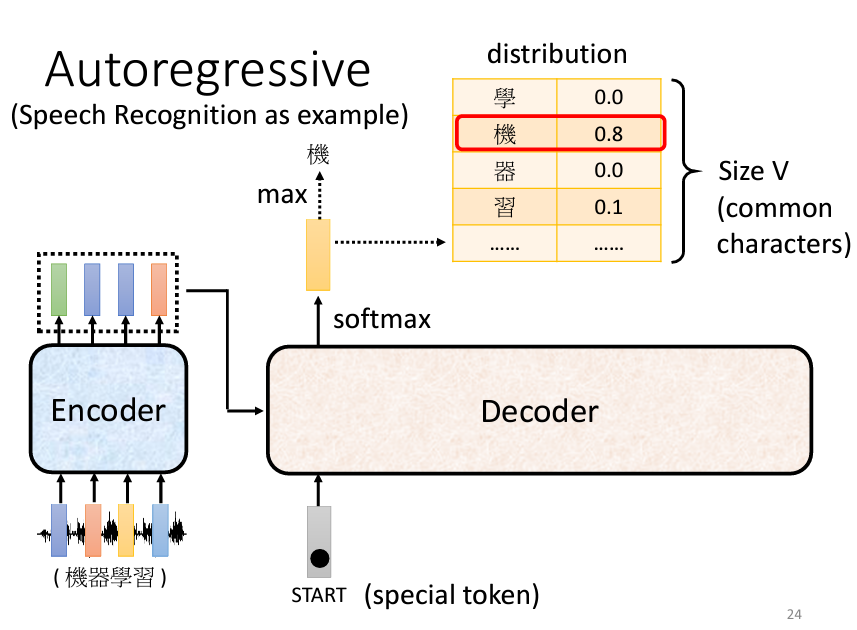
得到這個向量以後,分數最高的那一個中文字就是最終的輸出。在這個例子裡面機的分數最高,所以機就當做是這個 Decoder 第一個輸出,接下來把機當做是 Decoder 新的 Input ,原來 Decoder 的 Input 只有 BEGIN 這個特別的符號,現在它除了 BEGIN 以外,它還有機作為它的 Input 。【機】這個字也是表示成一個 One-Hot 的 Vector 當做 Decoder 的輸入,所以 Decoder 現在有兩個輸入,一個是 BEGIN 這個符號一個是【機】這個字。以此類推地接龍下去。所以其實 Decoder 會把自己的輸出當作是自己的下一個輸入。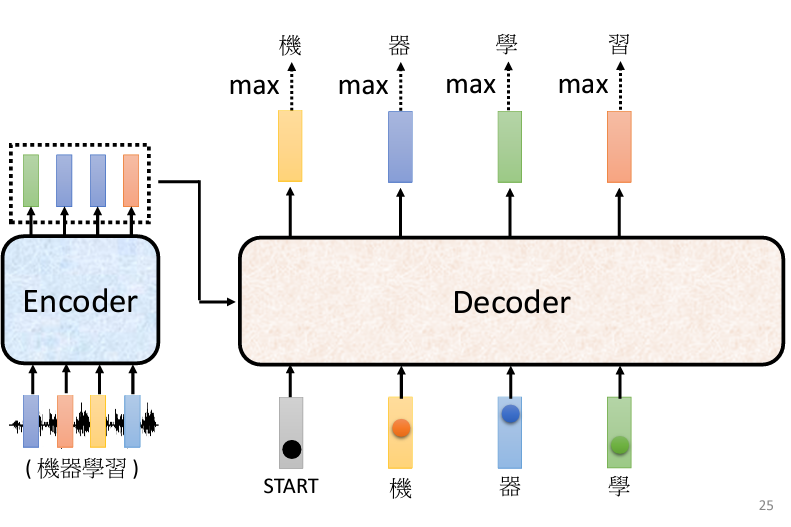
現在我們來看看 Decoder 的内部結構: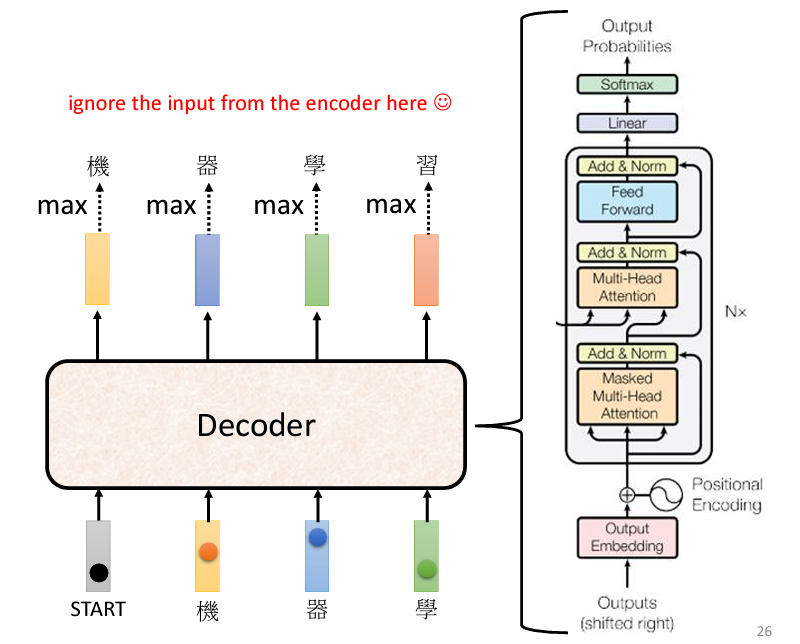
看起來很複雜,但是我們把 Encoder 和 Decoder 拿出來互相比較,并且把 Decoder 中間一部分遮住,會發現其實 Decoder 和 Encoder 是十分相似的: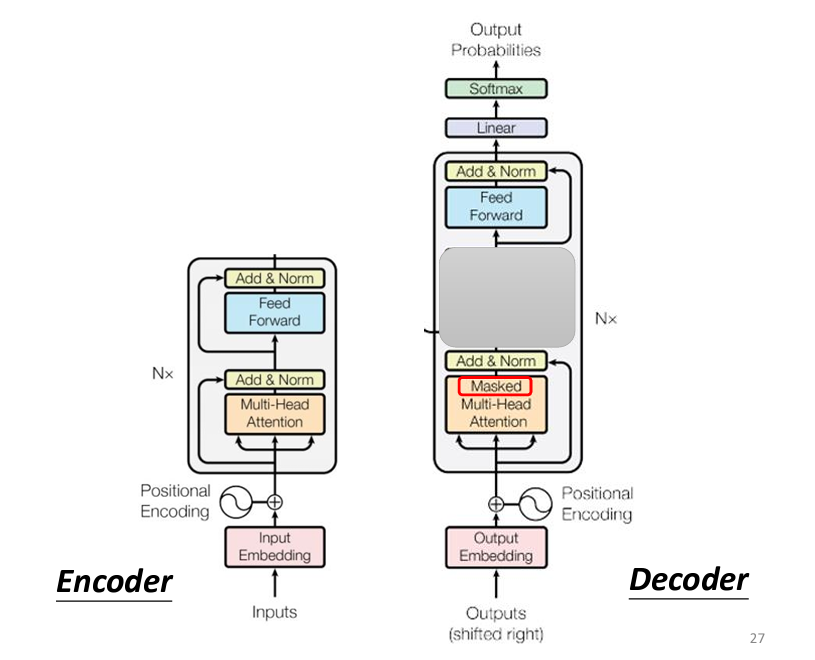
觀察 Decoder 的架構圖,可以看到最終的輸出是經過一個 Softmax,跟我們上面説的一樣。那麽再看 Self-Attention 的部分,可以看到 Decoder 這邊多了一個 Masked 字眼,這代表和我們之前學到的 Self-Attention 是略有不同的,我們先來看原本的 Self-Attention: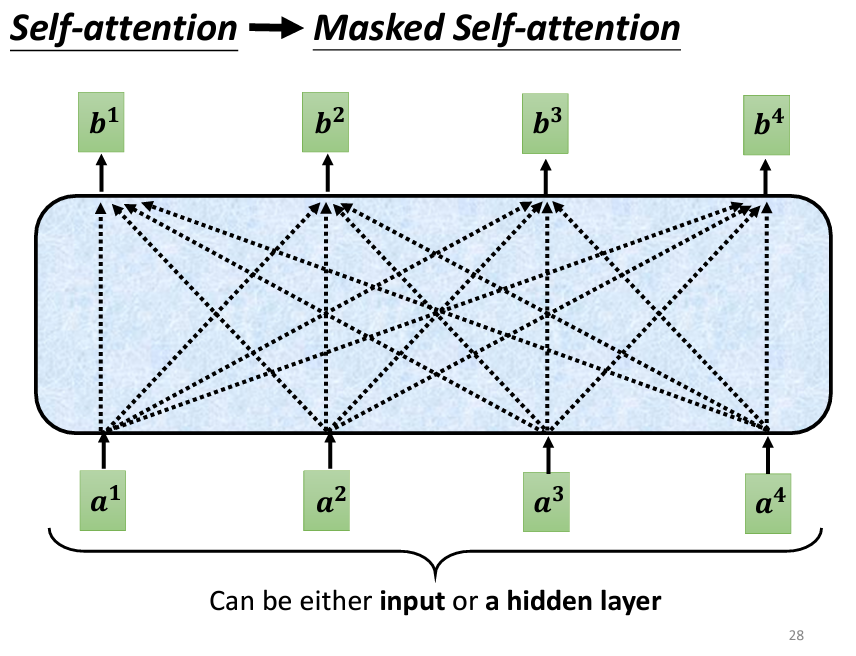
所謂的Masked的意思,原本的Self-Attention是每一個輸出都考慮了所有的輸入,但是加上Mask以後,我們只看自己和自己之前的輸入,也就是左邊的輸入: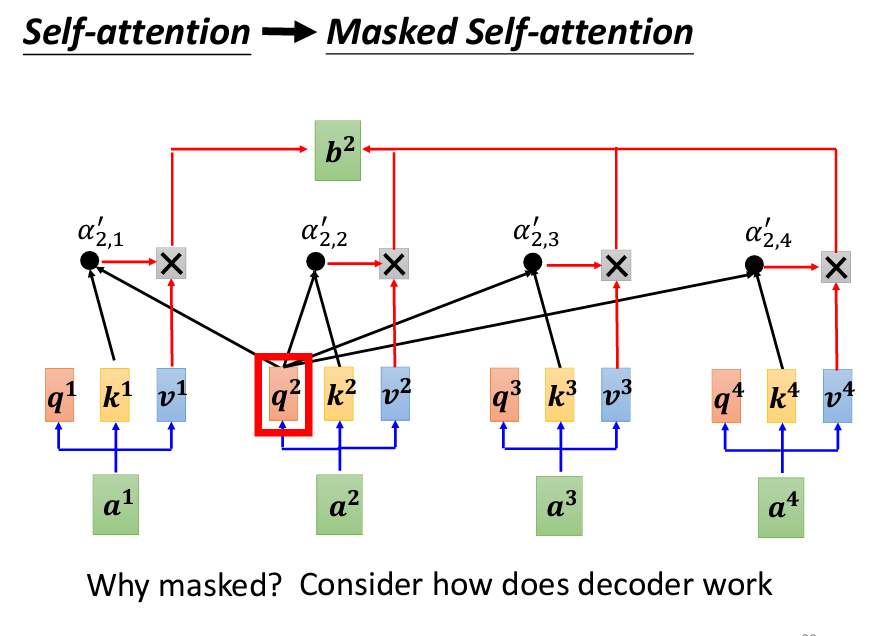
爲什麽要這樣做呢?因爲Autoregressive Decoder是一個一個字產生的,所以在還沒有產生下一個字之前,當然不能考慮還沒產生出的字。
現在我們還有一個問題,那就是我們需要Model自己決定要輸出多少的文字,但是我們看到這邊其實還不知道要怎麽讓Model自己中斷輸出: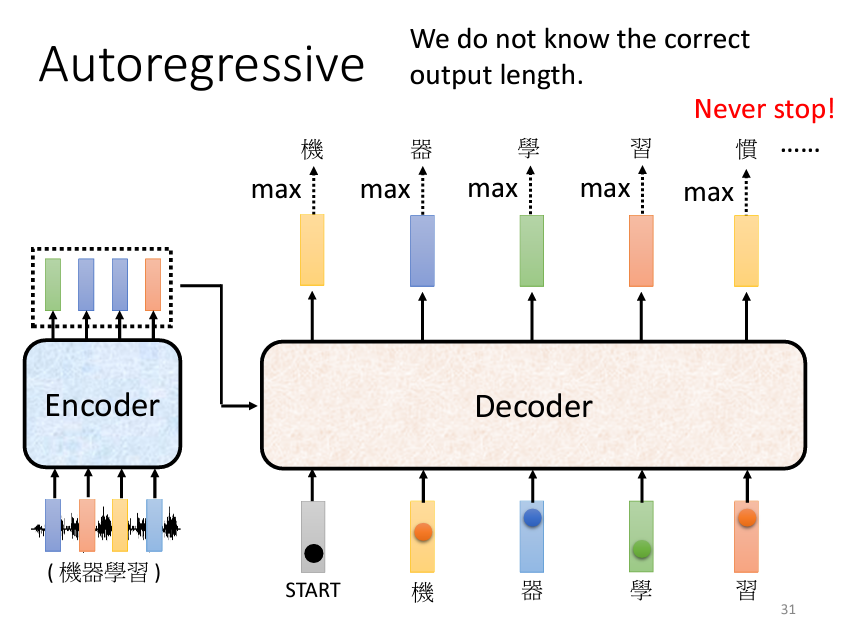
所以有一個方法,就是我們在我們的 One-Hot Vector 裏面加入一個代表結束的特殊符號,當生成到這個特殊符號的機率最大時,我們就終止我們的輸出。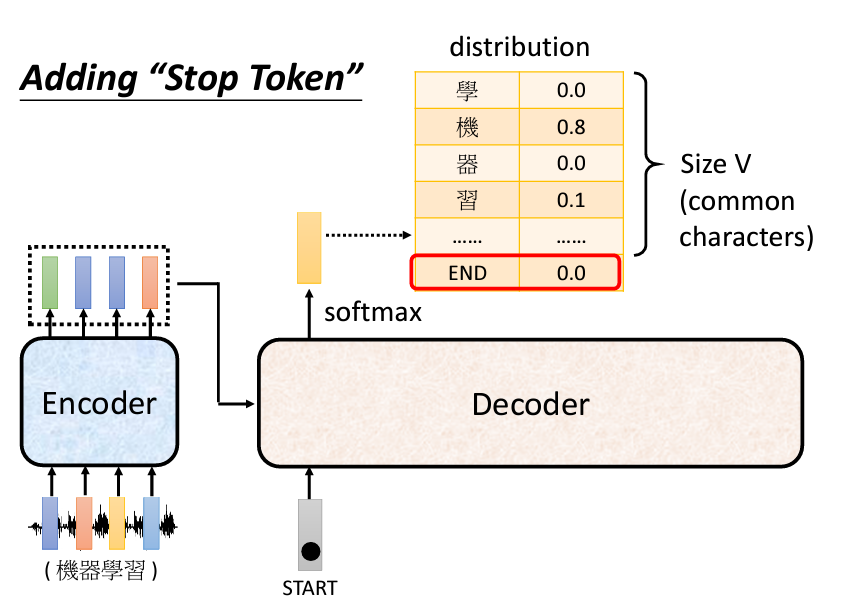
那麽,我們今天就到這邊,讓我們明天再繼續講解有關Decoder的運作,和整體的運作。
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。


 iThome鐵人賽
iThome鐵人賽