前言
今天簡單來介紹一個東西,它是我在查詢若想要深入學習 TensorFlow ,還需要什麼基本概念中的一個。
基本介紹
自編碼器(autoencoder)也稱自動編碼器,是一種人工神經網絡,主要用於學習無標籤數據的有效編碼,適合用於降維、特徵學習和數據去噪等,是一種無監督學習。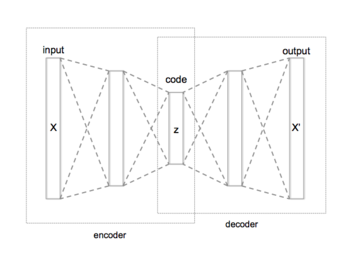
這是自編碼器的圖,可以看到它輸入進來,經過編碼器對輸入的資料做壓縮,再經過解碼器重建原始輸入後,輸出結果。
主要組成
上面有提到它輸入到輸出主要經過兩個東西,它主要就是由這兩個部分組成,
1.編碼器(Encoder):這部分將輸入數據壓縮為較低維度的表示,通常稱為潛在空間,目的是捕捉數據的基本特徵,同時捨棄噪聲和無關的資訊。
2.解碼器(Decoder):這部分從潛在表示中重建原始輸入,其目標是最小化原始輸入和重建輸出之間的差異,通常使用均方誤差等損失函數。
主要概念
訓練的部分,自編碼器在沒有標籤輸出的數據集上進行訓練,模型學會將輸入編碼為緊湊的形式,然後解碼回去,調整其參數以最小化重建誤差。
應用則是:
最後要介紹一下自編碼器的幾種變體,每種都有特定的應用和優勢,以下是四種主要類型的自編碼器: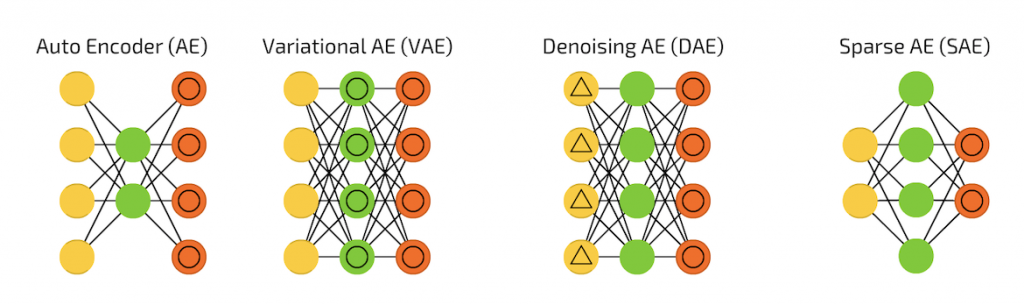
1.基本自編碼器(Basic AutoEncoder 簡稱 AE):
這是最基本的自編碼器結構,包含編碼器和解碼器兩部分,它主要目的是將輸入數據壓縮為較低維度的潛在表示,再重建回原始數據,訓練過程中通過最小化重建誤差來調整參數。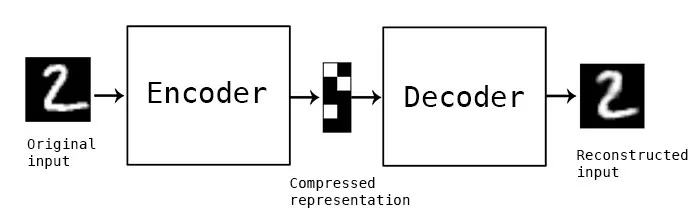
2.去噪自編碼器(Denoising AutoEncoder 簡稱 DAE):
這個變體的目的是從帶有噪聲的輸入中重建乾淨的數據,訓練時會將輸入數據隨機損壞,例如隨機屏蔽一些數據,模型則學習如何從這些損壞的數據中重建原始數據,這種方式有助於提高模型的穩健性。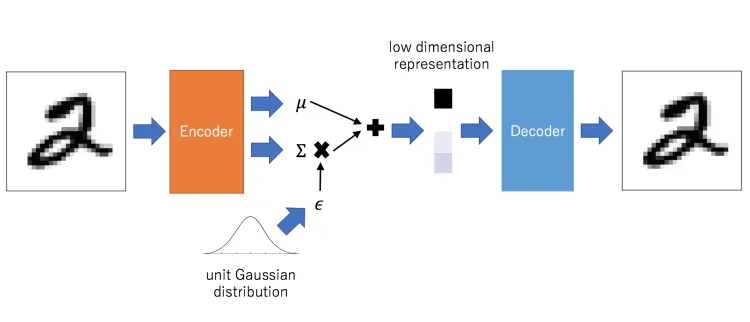
3.變分自編碼器(Variational AutoEncoder 簡稱 VAE):
VAE結合自編碼器和概率模型,學習潛在空間的分佈而非單一的潛在表示,它通過強制編碼器的輸出遵循某種已知分佈,讓它在生成新數據時更靈活,適合用在生成模型和數據合成。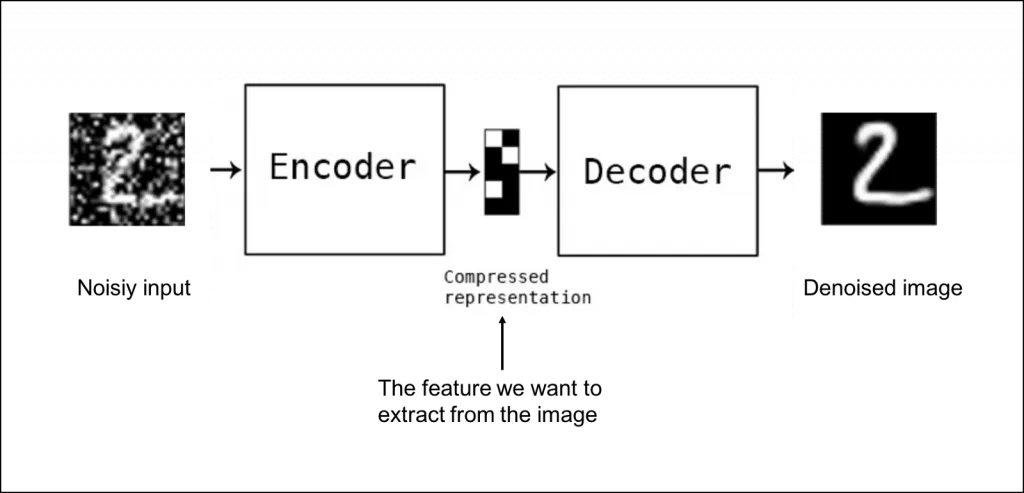
4.稀疏自編碼器(Sparse AutoEncoder 簡稱 SAE):
這個自編碼器的特點是鼓勵潛在表示的稀疏性,通常用額外的稀疏性正則化項,這表示在任何給定時間點,只有少數幾個神經元會被激活,這有助於模型學習更具辨識性的特徵,適合用在特徵學習和分類任務。


 iThome鐵人賽
iThome鐵人賽