這次我們為了體驗BERT與我們最初學習的LSTM究竟有多少不同,今天依然使用IMDB這個資料集進行處理。而在本章節中,我們主要是讓你熟悉Hugging Face這家公司的預訓練模型的格式與使用方法。因此,程序碼介紹時,我會向你展示如何將之前的Trainer與Hugging Face的預訓練模型結合使用。在本章節中,程式碼應該是目前為止最簡單的,因為我們不需要自行處理模型,而是直接進行以下四個步驟:
話不多說,讓我們開始今天的內容吧。
在本次的內容中,我們會採用與Day 14相似的程式碼。然而這次我們會特別針對BERT模型及先前未補充的知識,在撰寫程式碼的同時進行補充。現在我們來看到以下步驟。
在今天我們將直接採用在Day 14時建立的CSV文件開始。在BERT模型中,其實有許多不同的版本,例如我們之前一直使用的bert-base-uncased就是原始BERT的base版本。由於該模型能接受的Token數量最多為512個,因此在使用tokenizer時,我們必須將max_length設定為512,否則程式會出錯。當然我們還有bert-large-uncased版本,它可以支援最多1024個Token,同時該版本的模型參數量也更加龐大。
模型後面的
uncased代表著其Tokenizer與模型不會區分大小寫;若標示為cased則會區分大小寫。
import pandas as pd
from transformers import AutoTokenizer
df = pd.read_csv('imdb_data.csv')
reviews = df['review'].values
sentiments = df['sentiment'].values
labels = (sentiments == 'positive').astype('int')
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
input_datas = tokenizer(reviews[:2].tolist(), max_length=10, truncation=True, padding="longest", return_tensors='pt')
print('Tokenizer輸出:')
print(input_datas)
# ----- 輸出 -----
Tokenizer輸出:
{'input_ids': tensor([[ 101, 22953, 2213, 4381, 2152, 2003, 1037, 9476, 4038, 102],
[ 101, 11573, 2791, 1006, 2030, 2160, 24913, 2004, 2577, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
上次我們沒有討論到 token_type_ids 這個特殊的輸入。這一點對應了BERT的Segment Embedding層。当Token為0時代表第一句,為1時則代表第二句。在BERT的Tokenizer中,這個功能已經被預先定義。如果我們想要輸入兩句話,可以這樣寫: tokenizer('句子A', '句子B')。這樣,模型在處理資料時就會將其轉換成 [CLS] 句子A [SEP] 句子B [SEP] 的形式,同時附上對應的 token_type_ids。
注意這次我們會將資料轉換成
int格式。這個問題其實由來已久詳細狀況可以參考這篇文章。
在這一步中,我們之前所建立的模型格式是根據 Hugging Face 的規定進行的。在這些模型中,參數定義包括由對應的 Tokenizer 產生的 input_ids、token_type_ids 和 attention_mask,並將其分別傳遞給模型。不過,其中只有 input_ids 是必須輸入的參數,其餘參數我們其實可以選擇不傳遞,但這可能會導致 Padding 等 Token 與句子訊息遺漏。儘管如此模型仍然可以進行訓練。
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import torch
class IMDB(Dataset):
def __init__(self, x, y, tokenizer):
self.x = x
self.y = y
self.tokenizer = tokenizer
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
def collate_fn(self, batch):
batch_x, batch_y = zip(*batch)
input_ids = self.tokenizer(batch_x, max_length=512, truncation=True, padding="longest", return_tensors='pt').input_ids
labels = torch.LongTensor(batch_y)
return {'input_ids': input_ids, 'labels': labels}
x_train, x_valid, y_train, y_valid = train_test_split(reviews, labels, train_size=0.8, random_state=46, shuffle=True)
trainset = IMDB(x_train, y_train, tokenizer)
validset = IMDB(x_valid, y_valid, tokenizer)
train_loader = DataLoader(trainset, batch_size=8, shuffle=True, collate_fn=trainset.collate_fn)
valid_loader = DataLoader(validset, batch_size=8, shuffle=True, collate_fn=validset.collate_fn)
這裡我們將 max_length 設定為 512,同時定義 labels。雖然 labels 參數不是每次都需要傳入,但在訓練模型時則必須傳遞。這樣模型會自動使用 NULLoss 計算損失值。如果我們想更換損失函數,只需在訓練時將模型的 Logit(我們之前定義的 output[1])與實際標籤進行損失值計算後在反向傳播即可。
由於這次的模型參數量較大
batch_size可以設置的小一些,以免產生OOM(Out-Of-Memory)的問題。
在BERT中,由於其線性分類器的設計需要根據任務進行調整,例如在進行QA任務時,我們需要從文本中找到答案,因此須建立兩個線性分類器,一個用於找尋答案的開頭位置,另一個則是結尾。而這次我們則需要使用文本分類的線性分類器。最麻煩的作法是先繼承BERT的基礎模型,然後手動建立一個線性分類器,並取得其[CLS]標籤的輸出進行訓練。這種方式能對模型做出更高自由度的改動,但其實我們不需要這樣做。在Hugging Face中,已經幫我們定義好了這些類別。比如說,這次的線性分類器,我們可以調用BertForSequenceClassification來進行文本分類。
from transformers import BertForSequenceClassification
import torch.optim as optim
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
optimizer = optim.AdamW(model.parameters(), lr=1e-4)
在這裡需要注意的是 num_labels 的設計。該值的預設值是2,如果我們有更多的選項,記得要進行修改,否則就會導致模型訓練錯誤。
在這裡我們同樣的使用Trainer進行訓練,而在這裡我們要注意一點若我們的Labels不是整數時,其計算的損失函數會有所變動,因此若發生ValueError: Target size (torch.Size([8])) must be the same as input size (torch.Size([8, 2]))這一類的錯誤時,請檢查在DataLoader時是否設定成LongTensor,以及原始的資料是否為整數狀態。
from Trainer import Trainer
trainer = Trainer(
epochs=10,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=[optimizer],
early_stopping=3
)
trainer.train()
# ----- 輸出 ------
Train Epoch 4: 100%|██████████| 1123/1123 [23:33<00:00, 1.26s/it, loss=0.004]
Valid Epoch 4: 100%|██████████| 281/281 [02:59<00:00, 1.56it/s, loss=0.003]
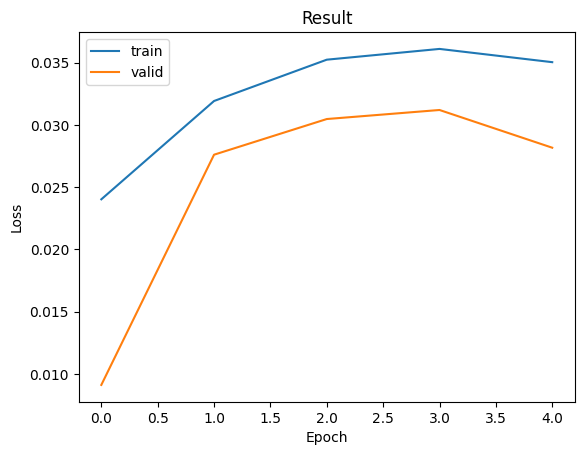
而我們可以從結果看出,模型在第一個週期就已經完成了訓練,後續反而會導致 Loss 升高現象。這是因為我們的模型在預訓練階段已經被有效訓練過了,因此通常線性分類器的調整也會在此期間完成。這正是為何在實際訓練 AI 模型時,會採用預訓練模型的原因。我們可以看到其損失值非常低,僅需短短的時間便可完成整個模型的訓練。
這次我們介紹了如何使用 Hugging Face 的預訓練模型來進行情緒分析,並與先前的 LSTM 模型做比較,檢視其損失值的結果。在這篇文章中,我們將看到只需簡單的四個步驟就能完成整個程式的訓練,不僅程式碼量大幅減少,效能上也有顯著提升。不過,由於這次任務較為簡單,且使用的是 Encoder 架構,因此變化不大(Encoder 架構通常較重視資料前處理,以符合模型的預期輸入)。明天,我會告訴你如何在只有 Decoder 架構的模型上進行操作,以及有哪些技術可以應用於這類模型。

