如果說BERT是Transformer的Encoder代表,那麼今天提到的GPT系列模型可以說是Decoder的代表。這些模型的架構與技術原理奠定了當今許多熱門的大型語言模型的基礎,後續的許多改進與技術都是從今天的內容中衍生而成的。講到這些與ChatGPT相關的技術,也意味著我們進入了學習的最終階段。今天我們就先來看看最早的GPT模型GPT-1,以及它的每一代模型究竟是怎麼練成的吧。
GPT-1 是由 OpenAI 於 2018 年推出的基於 Decoder 的語言模型,其發表時間比 BERT 稍早,是 GPT 系列的第一個版本。其訓練方式採用了基於無監督學習的自回歸方法,擺脫了傳統 NLP 模型依賴大量標註數據進行監督學習的限制。在訓練過程中,GPT-1 通過之前的輸出來預測下一個詞。具體來說,給定一個詞序列 x(1)、x(2)、x(3)...x(t-1),模型的目標是預測下一個詞 x(t),即最大化條件概率 P(x(t) | x(1)、x(2)、x(3)...x(t-1))。該模型透過維基百科和書籍等開放數據源的未標註文本數據進行訓練,這使 GPT 系列的模型能夠通過當前的文字序列來找出下一個最有可能出現的文字,以生成多領域的內容,而無需像 BERT 那樣必須經過微調才能使用。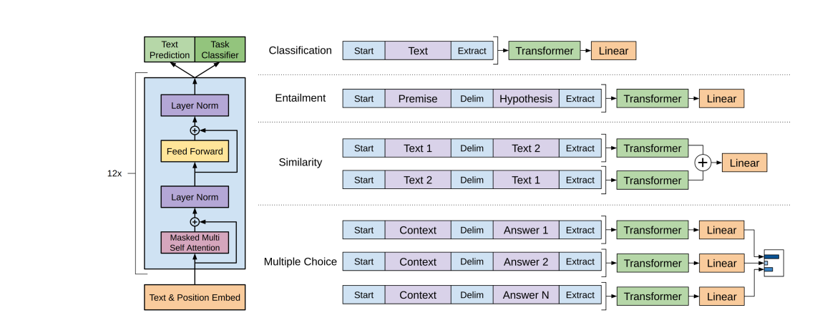
如同BERT的論文所述,儘管GPT-1具備一定的通用性,但由於它僅使用Transformer的解碼器部分,因此在語義理解方面相對較弱,特別是在處理複雜語義關係時顯得不足。同時自回歸方式需要依賴之前的所有輸入來預測下一個詞,在長文本生成中容易導致信息丟失和誤差累積,並且是一種單向的語言模型。雖然GPT-1的開發目的是成為一個通用模型,但最終還是需要經過微調才能在九項NLP資料集中取得SOTA表現,而未經微調的情況下,其泛化能力仍有所不足。
而在 2019 年OpenAI 推出了 GPT-2。相較於 GPT-1,GPT-2 的模型參數和訓練數據量均大幅增加。**GPT-2 的訓練數據量是 GPT-1 的八倍,而參數量則增加了四十倍。**這使得 GPT-2 在更多元化的任務上表現出色。GPT-2 的規模效應顯而易見,參數量的巨幅提升讓模型能夠捕捉到更豐富的語言結構和語義信息,甚至在未經過微調的狀態下,就在七項 NLP 資料集上達到了 SOTA 水準。
**然而在某些任務中進行微調後,GPT-2 的性能反而有所下降,這可能是由於微調數據的特異性導致模型過度擬合,從而損失了通用性。**這一點強調了預訓練和微調之間需要取得平衡,以在提升特定任務性能的同時保持模型的泛化能力。GPT-2 的推出也引發了關於 AI 生成文本潛在濫用的關注,例如生成假新聞和垃圾信息。出於這些擔憂,OpenAI 最初選擇不公開 GPT-2 的完整模型,這促使研究界更重視 AI 的安全和倫理問題。
而在GPT-2的架構與模型中並未有太大的創新,但在這次的模型訓練中,我們得知了兩件事情。第一件事是當模型的參數量與訓練資料量越大時,模型將會有更強大的能力,甚至可以在不進行微調的情況下取得優異的成績。第二件事是當模型參數量增加時,微調的效果反而可能變差,這讓我們需要找尋一些新的微調策略或是方法。
而 GPT-3 的出現標誌著模型規模的又一次飛躍,其參數量達到 1750 億,相較於 GPT-2 的 15 億提升了數個量級。如此龐大的模型需要處理海量數據,OpenAI 使用了約 45TB 的社群網路數據來訓練 GPT-3。而在 GPT-3 的訓練中,採用了元學習(meta-learning)的策略,元學習的概念就是將無標註的訓練結果當成一個新的結果已讓模型學習,而在GPT-3使用了 (這邊原文理解錯誤,GPT-3使用ICL的方式達成內循環,感謝hlb的勘誤)MAML(Model-Agnostic Meta-Learning)這一元學習技術。
MAML的主要概念是希望模型具備「學習如何學習」的能力,能夠快速適應在新任務上。具體而言MAML 的目標是訓練一個模型,使其能夠在接收到新任務時,僅通過幾次梯度下降就能取得良好的表現。
MAML 是一種元學習演算法,其訓練過程包含兩個主要部分:內部循環更新(Inner Loop Update和外部循環更新(Outer Loop Update)。首先MAML 從訓練數據集中隨機抽取一批任務,這些任務具有不同的數據分佈,可能涉及完全不同的問題類型,例如物體分類、數學題解、程式執行等。每個任務被分為支持集(Support Set)和測試集(Query Set)。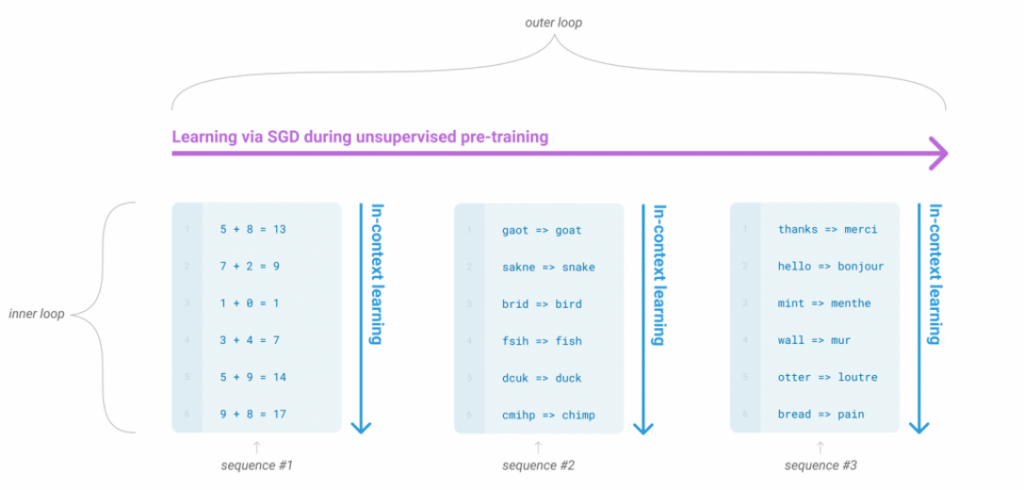
在內部循環更新中,模型基於當前參數,使用支持集進行多次梯度下降更新,目的是讓模型學習如何解決當前任務。這個過程可以採用各種適合的優化算法,如隨機梯度下降(SGD)或 Adam。這其實類似於我們在傳統訓練過程中對模型進行優化的動作,但在這裡,模型會針對不同的任務分別學習對應的數據集。每當訓練一組數據集時,模型會產生各自的權重與參數。
接下來,這些權重與參數會被用於外部循環更新。在這一步,模型**利用每個任務測試集計算內部更新後的損失,然後根據這些損失來更新模型的原始參數。**外部更新的目標是找到一組初始參數(Initial Parameters),使模型能夠在面對新任務時,通過少量的梯度更新快速適應並獲得良好的結果。
而在大量的資料與學習下 MAML 這一方法不僅學習如何解決具體任務,還通過了初始參數讓模型學習如何快速適應新任務,這賦予了它模型無關(Model-Agnostic)的特性。這意味著該方法可以應用於不同類型的任務。透過這種方法,模型能夠學習到更通用的特徵(Generalizable Features),使其在少量數據和有限次數的更新下,仍能取得卓越的表現。
GPT-3 的論文則是基於類似 MAML 的特性,提出了 Few-shot 和 Zero-shot 的概念,進一步擴展了模型的學習能力。Zero-shot 是指模型在未見過特定類別的訓練樣本的情況下,仍能對該類別進行準確預測;而 Few-shot 則是模型在僅有少量訓練樣本的情況下,能適應上下文並推理出正確答案。這兩種學習方式使 GPT-3 能夠通過上下文推理和學習,而無需對模型參數進行顯式調整,這種能力也被稱為 In-Context Learning。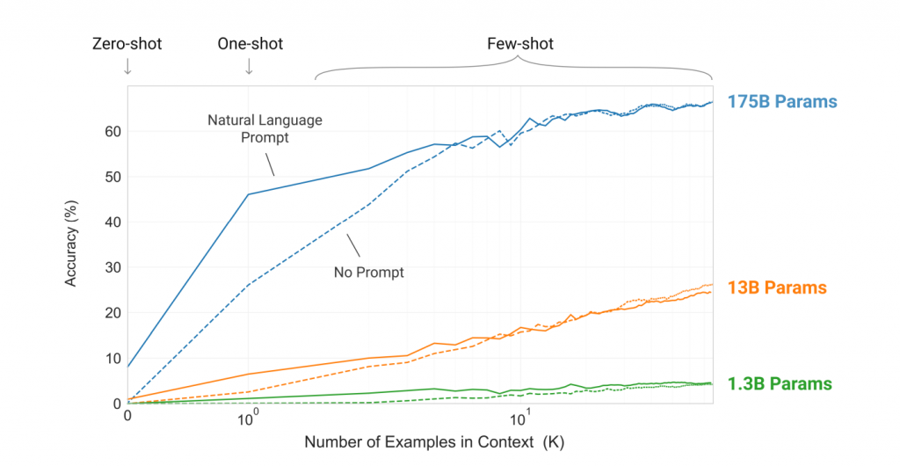
另一個關鍵概念是Prompting Learning,這項技術對於 GPT-3 性能的提升起到了重要作用。Prompting 是在模型的輸入中提供明確的上下文提示,以引導模型生成預期的回答。例如,在執行翻譯任務時,提供「請將中文翻譯為英文」這樣的提示,能幫助模型正確理解當前的任務是翻譯,從而生成更準確的結果,而這些技術也是當前大型語言模型中不可或缺的一環。
在今天的內容中,突然出現了一堆名詞,所以我在文章的最後做一些統整。首先,In-Context Learning是一個很廣泛的概念,基本上任何我們輸入一段文字以幫助模型推理的方式都可以叫做In-Context Learning。因此,Prompting Learning和Few-shot也能算是In-Context Learning的一環,但兩者之間又有差別。
Prompting Learning是指通過一個提示詞讓模型知道需要進行的任務,而Few-shot通常指的是我們的資料集內容。模型會通過Few-shot的內容作為上下文,以推理出我們想要的目標答案。以ChatGPT的使用範例來說,我們問GPT問題就是屬於Prompting Learning,而這時如果有一些歷屆答案我們把它有一同給予GPT那就是Few-shot。
不知道這樣子有沒有更了解這些名詞了呢?
在GPT-3使用了MAML(Model-Agnostic Meta-Learning)這一元學習技術。
請問資料來源是哪裡呢?你引用的 https://arxiv.org/pdf/2005.14165 沒有明確提到這件事情。
Few-shot 則是模型在僅有少量訓練樣本的情況下,能適應上下文並推理出正確答案。
Few-shot 應該是指在輸入(prompt)中加上少量的範例。這邊提到訓練樣本有點混淆唷。

