IMDB情緒分析資料集是NLP領域中的入門磚,該資料集從IMDB網站抽取的電影評論,並以正面(positive)或負面(negative)方式標註。它包含50000條電影評論,其中25,000條用於訓練與驗證,另外25,000條則用於測試。由於資料量龐大且任務相對簡易,因此非常適合學習和優化模型的方向,同時也有助於更好地理解自然語言處理的模型架構。在今天的內容中,我們可以前往其資料的官方網站下載該資料集。
今天我們會使用 HuggingFace 公司的分詞器對 IMDB 影評資料集進行切割。這樣做的原因是,使用空白斷詞法會產生大量的 Tokens,並且會出現相似詞彙被識別為不同詞彙的問題。HuggingFace 的分詞器提供了一個很好的解決辦法。
今天我們要使用的 BERT 分詞器是通過分析文本並運用 BPE 算法獲取的詞彙表,這種方式更能達成我們的目標。現在讓我們看看自然語言處理模型如何進行分詞、填充、訓練,最後我們還會介紹如何使用 Warmup 排程器來改善模型性能,以提升最終表現。
由於我們下載的 IMDB 的影評資料是一個非常大型的.txt 檔案,因此我們在讀寫資料時必須不斷地使用open函數將其開啟,這一點在讀取資料時就會顯得異常緩慢,因此我們可以先通過讀取資料後將其轉換成一個 CSV 檔案,這樣做的好處是可以利用 Pandas 來方便地處理數據已加後續資料讀取的速度,而大多的自然語言處理資料集也都是使用CSV檔案進行保存的。
import pandas as pd
import os
def convert_IMDB_to_csv(directory, csv_file_path):
data = []
labels = []
for label in ['pos', 'neg']:
for subset in ['train', 'test']:
path = f"{directory}/{subset}/{label}"
for file in os.listdir(path):
if file.endswith(".txt"):
with open(f'{path}/{file}', 'r', encoding='utf-8') as f:
data.append(f.read())
labels.append('positive' if label == 'pos' else 'negative')
df = pd.DataFrame({'review': data, 'sentiment': labels})
df.to_csv(csv_file_path, index=False)
convert_IMDB_to_csv('aclImdb', 'imdb_data.csv')
我們下載下來的aclImdb資料夾中,有train與test資料夾,它們的標籤是通過pos與neg資料夾分割的。因此我們可以使用 os.listdir 去開啟這些文件,並存成一個列表,最後通過pd.DataFrame轉換其資料型態,儲存成CSV資料。
在進行優化實驗時,隨機性的影響常常導致每次驗證結果的差異,因此確保結果的可重現性至關重要。為了解決這一問題,我們可以通過固定隨機種子來確保每次模型訓練的結果一致。所以我們需要設定 Python 標準亂數生成器、NumPy 和 PyTorch 的亂數種子,從而有效控制訓練過程中的隨機性,方便重現實驗結果。
import torch
import numpy as np
import random
def set_seeds(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_seeds(2526)
接下來我們需要讀取 CSV 檔案中的影評資料,並使用 BERT 的 AutoTokenizer 導入期分詞器,已幫助我們進行填充與分詞的工作
import pandas as pd
from transformers import AutoTokenizer
df = pd.read_csv('imdb_data.csv')
reviews = df['review'].values
sentiments = df['sentiment'].values
labels = (sentiments == 'positive').astype('float32')
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
input_datas = tokenizer(reviews[:2].tolist(), max_length=10, truncation=True, padding="longest", return_tensors='pt')
print('Tokenizer輸出:')
print(input_datas)
# ----- 輸出 -----
Tokenizer輸出:
{'input_ids': tensor([[ 101, 22953, 2213, 4381, 2152, 2003, 1037, 9476, 4038, 102],
[ 101, 11573, 2791, 1006, 2030, 2160, 24913, 2004, 2577, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
這裡我們能看到他返回了三個參數。第一個參數 input_ids 代表文字經過斷詞後轉換成數字的結果,第二個參數 token_type_ids 則代表的是該文字是第幾句,第三個參數 attention_mask 則表示被填充的序列,其中 0 代表該位置被填充。而在這裡我們只會使用 input_ids 的部分,後續兩個參數的實際用途會在講解 BERT 模型時詳細說明。
由於先前我們都是通過直接使用Pytorch官方提供的Dataset類別,因此今天是我們第一次手動建立資料型態。其方式類似於我們之前重新包裝CIFAR10的Dataset類別,但需要注意的是,這裡每個批次中的文字長度不盡相同,因此我們還需要定義一個collate_fn函數。這個函數會在DataLoader中被調用,以完成動態填充的功能。
在DataLoader這一類別中其動作順序會先通過__getitem__取得其批量資料,接下來交給collate_fn進行輸出或轉換的動作,而這一條件就將在達到len(self.x)時停止,因此我們定義collate_fn其實就是將其批量取出,並通過self.tokenizer將我們輸入的文字轉換成Tokens並對其進行填充與截斷的功能
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
class IMDB(Dataset):
def __init__(self, x, y, tokenizer):
self.x = x
self.y = y
self.tokenizer = tokenizer
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
def collate_fn(self, batch):
batch_x, batch_y = zip(*batch)
input_ids = self.tokenizer(batch_x, max_length=128, truncation=True, padding="longest", return_tensors='pt').input_ids[:,1:-1]
labels = torch.tensor(batch_y)
return {'input_ids': input_ids, 'labels': labels}
x_train, x_valid, y_train, y_valid = train_test_split(reviews, labels, train_size=0.8, random_state=46, shuffle=True)
trainset = IMDB(x_train, y_train, tokenizer)
validset = IMDB(x_valid, y_valid, tokenizer)
train_loader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=trainset.collate_fn)
valid_loader = DataLoader(validset, batch_size=32, shuffle=True, collate_fn=validset.collate_fn)
而在這裡我們除了建立一個DataLoader之外,我們還使用了train_test_split這一個函數,將資料分成8:2的比例,已進行訓練與驗證的動作。
由於 RNN 和 LSTM 都是時間序列模型,所以我們可以將它們一起討論。在過程中,我們使用了 bidirectional=True 這個參數,該參數表示時間序列模型是否要進行雙向運算。如果這個參數設為 True,意味著每個輸入序列都會經過兩個 LSTM 層:一個是前向 LSTM,另一個是後向 LSTM。這兩個 LSTM 層分別產生各自的隱藏狀態,然後將它們拼接在一起作為最終的輸出。因此,當我們設定這個參數為 True 時,隱藏狀態特徵的數量將會是原來的兩倍。
而經過時間序列模型的輸出會返回兩個變數:output 和 h_n。output 是所有時間步的隱狀態輸出,在設置 batch_first=True 和 bidirectional=True 的情況下,其資料維度是 (batch_size, time_step, hidden_size * 2)。h_n 代表最後一個時間步的運算(在 LSTM 中則是 c(t) 的輸出),其資料維度為 (1 * 2, batch_size, hidden_size),因此我們可以從output中的最後一個time_step的資料,這樣子就代表的是LSTM最後的運算結果了。
import torch.nn as nn
class TimeSeriesModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_size, padding_idx, num_layers=1, bidirectional=True, model_type='LSTM'):
super().__init__()
self.criterion = nn.BCELoss() #定義損失函數
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx)
# 切換模型
rnn_models = {'LSTM': nn.LSTM, 'RNN': nn.RNN}
self.series_model = rnn_models.get(model_type, nn.LSTM) (
embedding_dim,
hidden_size,
num_layers=num_layers,
bidirectional=bidirectional,
batch_first=True
)
# 如果是雙向運算則最終的hidden state會變成2倍
hidden = hidden_size * 2 if bidirectional else hidden_size
self.fc = nn.Linear(hidden, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, **kwargs):
# 取得輸入資料
input_ids = kwargs['input_ids']
labels = kwargs['labels']
#轉換成詞嵌入向量
emb_out = self.embedding(input_ids)
# 時間序列模型進行運算
output, h_n = self.series_model(emb_out)
# output: (batch_size, seq_len, hidden_size * 2)
h_t = output[:, -1, :]
# h_t: (batch_size, 1, hidden_size * 2)
y_hat = self.sigmoid(self.fc(h_t))
# h_t: (batch_size, 1)
# 返回loss與logit
return self.criterion(y_hat.view(-1), labels), y_hat
在程式中,我們發現輸入是經過一層Word Embedding進行轉換的。實際上給予的Tokens會先通過Embedding層將其轉換到更高的資料維度,再交由LSTM進行運算。在這裡需要注意的是,由於Padding Tokens的存在,Word Embedding在反向傳播時會計算這些Tokens的梯度。因此我們需要設定padding_idx,以忽略這些梯度的運算。
接下來我們要使用排程器來訓練模型,今天我們將使用Warmup(暖身)這個排程器進行優化。該優化器的概念是,當我們一次輸入較大量的批量資料時,可能無法立即得知當前這組資料的方向。假設我們知道右邊路徑是最佳解,但當前的這個批量資料卻往左邊移動,這樣模型在一開始學習的方向就會錯誤。因此我們需要在一開始還沒確認方向時,先給予很小的學習率,直到暖身結束。這樣就能讓模型逐漸掌握資料的方向性。
import torch.optim as optim
from torch.optim.lr_scheduler import LambdaLR
from Trainer import Trainer
# 自定義 Warmup Scheduler
def get_warmup_scheduler(optimizer, warmup_steps, total_steps):
def lr_lambda(current_step):
# 計算 warmup 比例
if current_step < warmup_steps:
return float(current_step) / float(max(1, warmup_steps))
# 隨後開始隨著 total_steps 逐漸減小學習率 (線性衰減或其他方法)
return max(0.0, float(total_steps - current_step) / float(max(1, total_steps - warmup_steps)))
return LambdaLR(optimizer, lr_lambda)
# 模型、優化器和其他設置
model = TimeSeriesModel(
vocab_size=len(tokenizer), # Embedding的總大小等同於詞彙表大小
embedding_dim=50,
hidden_size=32,
model_type='LSTM',
padding_idx=tokenizer.pad_token_id
)
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=0.001)
warmup_steps = len(train_loader) * 0.2
total_steps = len(train_loader) * 10
scheduler = get_warmup_scheduler(optimizer, warmup_steps, total_steps)
而在排成器上我們選擇使用在train_loader的總步數(Step)上取0.2的比例進行暖身找到方向,並且總訓練步數為10個週期,因此total_steps為 len(train_loader) * 10,這時我們同樣的使用Trainer進行訓練並會驗證模型在驗證集上的表現,並使用早停法則來防止過擬合。
# 訓練過程中的 Trainer 設置
trainer = Trainer(
epochs=10,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=[optimizer],
scheduler=[scheduler], # 加入學習率排成器
)
# 訓練過程
trainer.train(show_loss=True)
# ----- 輸出 -----
Train Epoch 9: 100%|██████████| 1250/1250 [00:27<00:00, 45.54it/s, loss=0.450]
Valid Epoch 9: 100%|██████████| 313/313 [00:05<00:00, 60.19it/s, loss=0.631]
Saving Model With Loss 0.39172
Train Loss: 0.31513| Valid Loss: 0.39172| Best Loss: 0.39172
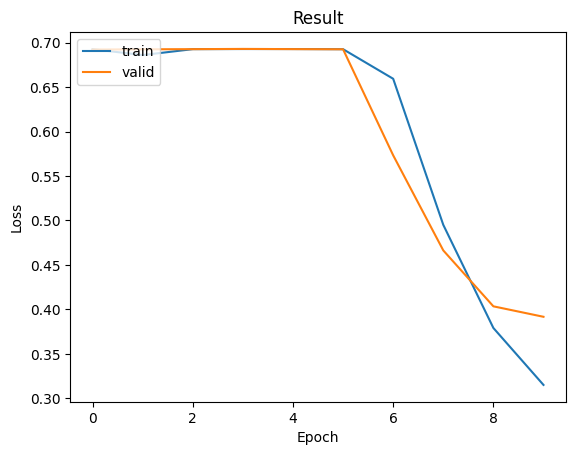
而這時我們將能看到模型在訓練的後期已經達到很漂亮的收斂結果其訓練損失值與驗證損失值也並無太大的差異,因此在這裡我們可以在撰寫一個函數來去觀看這個訓練出來的準確率
現在我們先載入表現最佳的模型,並且修改Trainer中的驗證函數。在這裡我們將超過0.5的數值視為正標籤,小於0.5的則視為負標籤,然後統計結果集以進行最終的驗證,計算模型的準確度:
model.load_state_dict(torch.load('model.ckpt'))
model.eval()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
total_correct = 0
total_samples = 0
with torch.no_grad():
for input_data in valid_loader:
input_datas = {k: v.to(device) for k, v in input_data.items()}
_, y_hat = model(**input_datas)
pred = (y_hat > 0.5).long()
labels = input_datas['labels']
total_correct += torch.sum(pred.view(-1) == labels).item()
total_samples += labels.size(0)
accuracy = total_correct / total_samples
print(f'Validation Accuracy: {accuracy*100:.3f} %')
# ----- 輸出 -----
Validation Accuracy: 82.920 %
在這裡我們可以看到驗證數據已經達到了82.92%。不過這個結果仍有優化空間。我們發現在collate_fn中,輸入的Token只有128個就被截斷了,同時這些資料的相似性也相當高。因此我們可以用L2正則化的方式來處理這些高度相似的資料。此外,在我們的模型經過學習率調整後,也可以加入其他的排程器邏輯,使其能夠更佳地收斂。
今天我們從頭到尾完成了一個自然語言處理的任務,同時進行了模型優化。為了保證每次模型訓練結果的一致性,我們特別強調了設置隨機種子的必要性。我們手動創建了 Dataset 並自定義了 collate_fn 函數,以實現動態填充的功能。這些功能在自然語言處理和模型優化中都是非常重要的技術。
當然我們可以不使用動態填充資料,但這樣會導致增加太多的Pandding Tokens使模型運算時間大幅增加。在最後我還提到了一些可以進一步優化的建議,這些為你提供了進一步學習和改進模型的方向,通過這些策略你可以嘗試將模型的準確率優化到 90% 以上看看吧~

