今天有了些進展,原來昨天訓練一直無法收斂,很可能是observation沒有做正規化,我忘記了把observation轉換成tensor後是直接作為PPO等RL模型的輸入;所以不管是balance, position還是價格與技術指標的數值都必須要做數值的正規化。
以下是訓練十幾秒後的結果,能夠看出有稍微學到低買高賣的策略,只是交易的非常頻繁,因此還是虧損: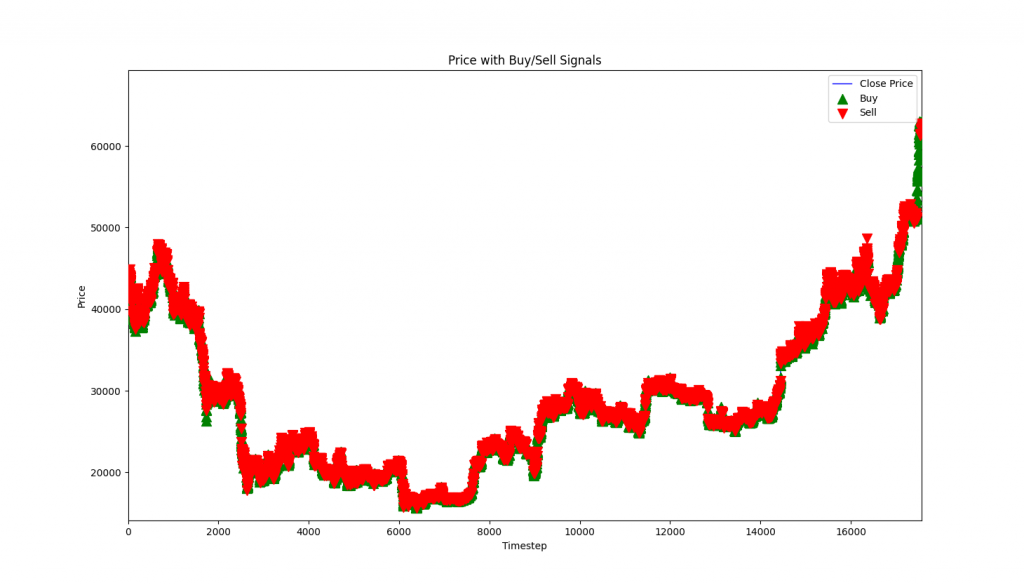
問題還是沒有完全解決,過度頻繁的交易並沒有獲利,而是虧損,雖然在訓練持續接近一小時後,虧損有明顯降低很多有時會有一些獲利;但結果仍然跟我期待的相差懸殊;所以看來我是沒有辦法在今天完成這個專案了。
今天是鐵人賽的最後一天,雖然最後還是開天窗了,沒有完成目標;不過藉由這三十天的時間,我確實在工作之餘,學習到了許多自動交易相關的知識,雖然每天被時間追著跑,常常擔心不小心忘記發文,不過確實因此增加了在下班時看文章,做實驗的動力;我會接著努力直到完成自己的自動交易機器人。


 iThome鐵人賽
iThome鐵人賽