接續前一篇的 Reactivity 核心概念講解內容,我們透過這一篇的內容帶大家釐清 Pull-based 與 Push-based 這兩個模式差異。
在細顆粒度(fine-grained)reactivity 裡:
我以百貨公司美食街的購物情境為例子,當我們買完餐後,會拿到一個圓盤。
對應 reactivity:來源改變就沿依賴鏈立即重算並通知後續節點。
我以買手搖茶的購物情境為例子,當我們點完餐後,會拿到一個單子上面有號碼。
對應 reactivity:寫入時只標記髒標記,讀取時才做必要的計算與更新。
| 名稱 | 行為焦點 | 簡化流程 |
|---|---|---|
| Push-based | 寫入即計算:資料一改動就沿依賴鏈立刻遞迴重算 | set() → propagate → compute → effect |
| Pull-based | 寫入只標記:先把依賴節點標成 dirty,真正重算延後到被讀取 | set() → markDirty ⏸ read() → if dirty then compute → effect |
重點觀念: 兩者都會「推送」訊號,但 push 推的是『計算』,pull 推的是『標記』。
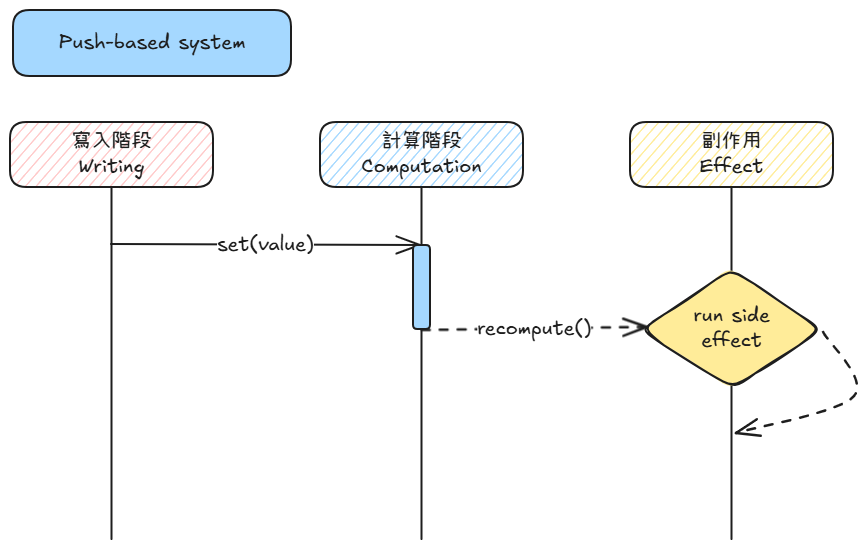
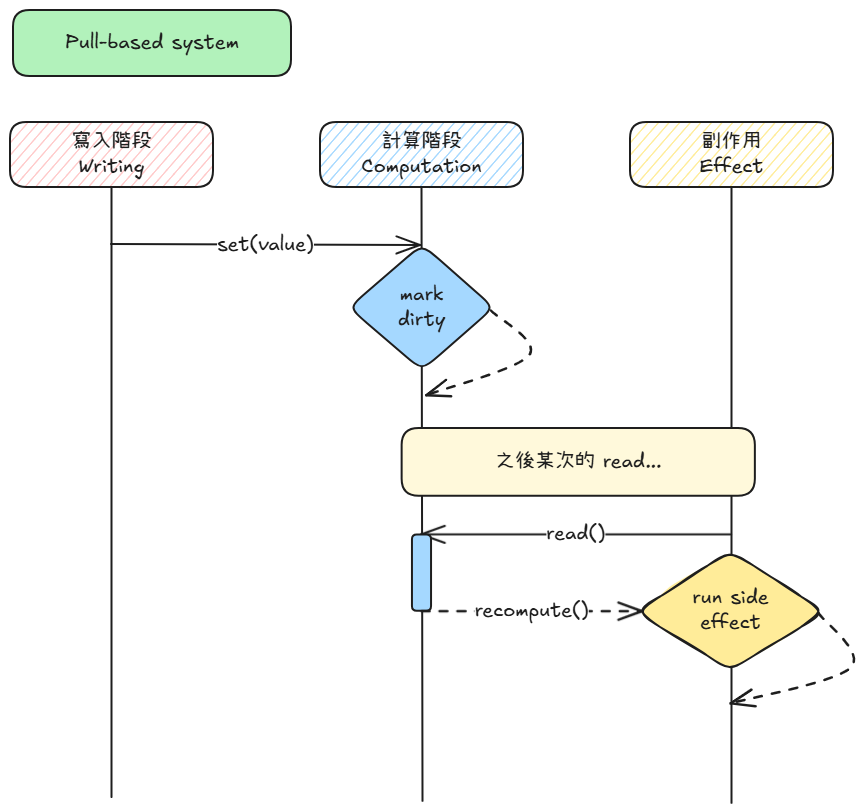
| 面向 | Push-based | Pull-based |
|---|---|---|
| 讀取延遲 | 最低,資料永遠新 | 若節點已髒,第一次讀取需重算 |
| 寫入成本 | 潛在大,O(依賴深度 × 寫入次數) | 較小,幾乎 O(依賴度 x 1),僅標記 |
| 過度計算 | 多,即使結果沒被讀取 | 少,只在實際讀取時才算 |
| 批次化 | 較難:事先已算完 | 天生適合:可一次性 flush |
| 除錯可觀測 | 依賴鏈一次展開 | 需 DevTools 追蹤何時 pull |
| 適合場景 | 高寫入頻率、低讀取 —— 例如協同編輯游標位置 | 低寫入、高讀取 —— 例如資料儀表板、視覺化 |
實務上仍需考慮「標記」時,沿依賴樹向下走一次,但通常只設
dirty=true而非重算。
還是要看開發場景和需求來決定,現在主流的 library 提供的解法,就是盡量結合這兩者之間的好處。
| 典型需求 | 建議模式 | 說明 |
|---|---|---|
| 即時共同編輯、遊戲狀態同步 | Push | 每次寫入都應立即反映,避免視覺延遲;依賴鏈淺、節點少 |
| 大型監控面板、圖表篩選 | Pull | 寫入少但讀取密集;Pull 把算力花在「真正被看見」的數值上 |
| 行為-驅動動畫(timeline、scroll-based) | Pull + Scheduler | Pull 延遲計算,加上排程器可保證同一 frame 只重算一次 |
| 資料科學 Pipeline(overkill 算一次可 reuse) | Push-on-Commit | 一次性執行、產物被多方重用;先算完再分發 |
以 React 為例,本質上屬於 Pull + Scheduler 的模式,這部分可以回想一下官方提及的 batching update 章節,我這裡就不再贅述了,至於 Push-on-Commit 的典型範例就是 Rxjs / MobX 了。
為什麼 Fine-grained Reactivity 要討論 Push vs. Pull?
在 coarse-grained(React V-DOM)世界,整棵樹 diff 已經足夠抽象。
但進到 signal-based 細顆粒度,一行 set 可能波及數百個微小 derivations。
此時,「計算發生的時機」 直接決定:
搞懂 Push 與 Pull 的本質對照,你就有了評估與選型的底圖。
下一篇,我們來看看主流框架如何處理 Reactivity 的解決方案。

