在過去,單核心CPU再提升效能的部分,都會聚焦在提升時脈(Clock Speed),但提升時脈會導致:
Multicore Processor指的是在一顆實體CPU中,整合了多個處理核心(Core)。每個core都可以獨立執行指令。而這些core彼此同時運作(這就是concurrent),共享記憶體與其他硬體資源,以提升整體運算效能,並節省空間與功耗。
但就算是Multicore Processor,也是會有記憶體速度跟不上CPU的一個問題。那我們就來進一步討論:
當 CPU 執行程式時,需要存取資料(例如讀取變數、陣列元素、指令本身),如果這些資料沒有在快取(Cache)中命中,就必須從主記憶體(RAM)載入。而由於主記憶體的存取速度遠慢於 CPU,因此 CPU 必須閒置等待資料返回,這種情況就稱為Memory Stall。
而為何Memory Stall是一個需要背出來討論的問題呢?
第一,即使 CPU 運算能力很強,一旦遇到 Memory Stall,它只能閒置等待(Idle),等資料回來再繼續跑。
第二,Memory Stall 通常意味著 Cache Miss(快取失誤)。命中率低 → Cache Miss 多 → Memory Stall 次數暴增。
第三,在多核心處理器中,若多個核心同時存取主記憶體,會加劇 記憶體爭用(Contention),導致 Memory Stall 更嚴重。
而一個有效的解法是多執行緒核心(Multithreaded Core):當一條執行緒在等資料(Memory Stall),CPU 立刻切換去執行另一條已經準備好指令的執行緒,避免浪費等待時間。這種技術也叫 Chip Multithreading(CMT)。
以Intel來說,這樣的技術便叫Hyper-Threading(超執行緒)
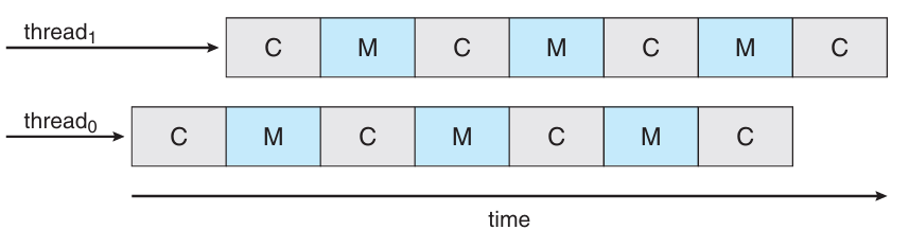
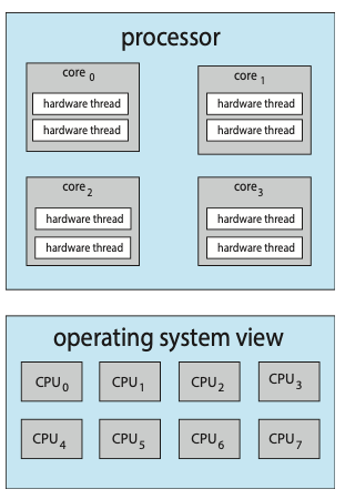
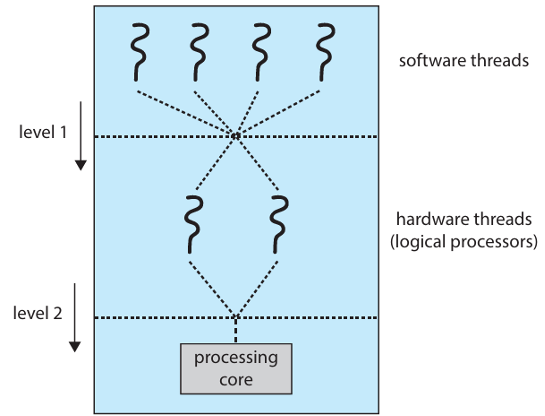
基於現代CPU核心支援多個硬體執行緒,CPU Scheduling也變等更加複雜。因此就有了Two-Level Scheduling的機制。Two-Level Scheduling指的是OS與CPU都要處理他們各自的Scheduling。金一步來說:
Level 1:由OS所處理,OS要決定哪條「軟體執行緒」要跑在哪個邏輯 CPU(hardware thread)。
Level 2:由CPU內部的core處理,每個核心內部決定執行哪一條硬體執行緒。
接下來,在多核心系統中,我們當然會希望讓所有處理核心的工作量盡量平均,避免某顆核心超級忙碌、其他核心閒著沒事做,這便是Load Balancing。作業系統在排程時,若只集中把所有任務排到某幾個核心。則會導致:core A 100% 使用率(CPU temperature 高、延遲大),coreB/C/D:閒置或僅 10~20% 使用率。對於結果而言,就是任務等待時間(waiting time)上升,整體 throughput 下降。
而針對Load Balancing目前的兩種策略如下:
第一,推式遷移(Push Migration):主體為核心管理器(scheduler),定期檢查每個核心負載,將過載核心上的任務「推」到其他核心。優點是主動調整,缺點是成本高且可能誤判空閒程度
第二,拉式遷移(Pull Migration):主體為閒置的核心,閒置的核心主動去別的核心「拉任務」過來執行。優點是被動但即時,可避免空轉。缺點是無法主動發現過載,反應稍慢
Processor Affinity是指「藉由讓thread或process偏好在同一個處理器核心上執行,以提升效能」。這個策略是為了充分利用該核心中的快取資料(特別是 L1/L2 cache),減少 context switch 後的 cache miss。
現代的處理器都有多層快取記憶體(L1/L2/L3),一條 thread 若換到其他核心執行,原來的 cache 資料就不在(發生cache miss)。而cache miss相當於重新讀資料進 cache(會讓費更多時間)。因此,若讓同一條 thread 儘量待在同一核心,快取中仍保留其資料,命中率高,執行速度快。
Affinity可以分成兩種形式:
第一,Soft Affinity:OS 傾向將同一 thread 排在同一核心上,但可彈性調整。
第二,Hard Affinity:明確指定 thread 只能執行在特定核心。
在傳統的對稱多處理(SMP)系統中,所有的處理器共用一個主記憶體,從任一個 CPU 存取記憶體的速度基本上是相同的。但這種設計在系統變大(例如有很多個核心)時會變得沒效率,因為所有的 CPU 都要搶同一個記憶體資源。因此,現代高效能的多處理器系統使用了一種架構叫做 NUMA。NUMA = Non-Uniform Memory Access(非一致性記憶體存取)。系統中每一顆 CPU(或 CPU 群組)會擁有自己的本地記憶體。也就是說,CPU0 擁有記憶體 A,CPU1 擁有記憶體 B,等等。而記憶體存取有快慢差別:
這就是「非一致性」的由來:不同位置的記憶體有不同的存取速度。當系統執行程式時,作業系統會將 thread 排程到某顆 CPU 上執行。這個 thread 用到的資料也會被配置在與該 CPU 靠近的本地記憶體。但如果為了「負載平衡」,作業系統把 thread 從 CPU0 移到 CPU1 執行:
解法:
Real-Time System 指的是一種對時間有「嚴格要求」的作業系統。其目標是確保特定任務在限定時間內完成。像是汽車防鎖死煞車系統(ABS)、飛機飛行控制系統、醫療儀器(如心律調節器)。
這種系統如果沒有在規定時間內完成,後果會發生什麼事....
Real-Time System可以分為兩大類:
一種是Hard Real-Time:必須絕對準時完成任務,超過 deadline 視為失敗。
另一種是Soft Real-Time:盡量準時完成任務,允許偶爾延遲,只要不影響整體系統功能。
那也因此,Real-Time Scheduling 的需求必須具備:
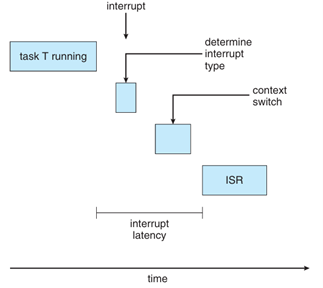
事件延遲(Event latency)是指事件發生(如輸入或感測器變化)到系統開始對此事件做出回應之間的時間延遲。在 real-time 系統 中,這段延遲時間必須儘可能短,否則可能造成危險或性能下降。其中,Dispatch latency是指作業系統將「CPU 從一個 process 移交給另一個 process」所花的時間。Dispatch latency的核心是「上下文切換時間(Context Switch Time)」。這一段時間包含:
中斷發生 →
[1] CPU 完成當前指令 →
[2] 確認並辨識中斷來源 →
[3] 儲存目前 process 的上下文(context) →
[4] 跳轉並執行對應的 ISR(Interrupt Service Routine)
耶~~CPU Scheduling終於寫完了


 iThome鐵人賽
iThome鐵人賽