前篇已經完成資料集專屬代碼的複製,接下來,本章將從Google Colab的環境建置,到YOLO的訓練與預測,全流程的一步步學習AI視覺辨識模型訓練的流程。
Google Colab,全名是Google Colaboratory,它提供了免費的雲端運算資源、讓使用者可在雲端執行 Python 程式碼,也免去本地端較繁複的系統環境設定,只要擁有 Google 帳號,便能快速地開始進行部署。
首先,搜尋或開啟Colab頁面:https://colab.research.google.com/ 並新增筆記本。
圖9.1 Google Colab 起始頁面
Step1:接下來,就像在電腦中安裝各種軟體一樣,安裝YOLO套件。
# 1. 安裝 YOLO
!pip install ultralytics
Step2:安裝roboflow並匯入執行,以及貼上前篇的資料集專屬代碼。
# 2. 下載資料集
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="這裡填上你的key")
project = rf.workspace("你的工作空間名").project("你的專案名")
version = project.version(2)
dataset = version.download("yolov8")
在進入正式訓練模型之前,先來了解一下ultralytics yolo預設的已訓練模型,主要依資料量的大小有分為五類,分別是nano、small、medium、large和xlarge。由於本案例僅有少量的資料集,因此選擇yolov8n.pt這個預設模型來訓練。
Step3:預設模型選擇輸入"yolov8n.pt"。
# 3. 載入模型(訓練好的.pt 或官方預訓練)
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # 或 "runs/detect/train/weights/best.pt"
選擇模型之後,很重要的一步便是告訴電腦我的資料集放在哪個位置(如下圖9.2所示),因此可以使用以下的代碼來檢查路徑是否有誤。
Step4:檢查data.yaml路徑。
# 4. 檢查data.yaml路徑
import os
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
if name == "data.yaml":
print(os.path.join(root, name))

圖9.2 檢查data.yaml路徑結果
當一切都完備時,就可以開始訓練模型了,但要特別留意須將data路徑更改為上一步查詢的結果;另外在訓練輪數(epochs)建議可先設為5次左右,當確認沒有運行大問題時,再加以調整。
Step5:訓練模型。
# 5. 訓練
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # 可用yolov8n.pt或v8s.pt等
model.train(data="./乙丙級電繪-2/data.yaml", epochs=50, imgsz=640)
# data路徑記得根據上一步查到的結果修改
模型完成訓練後,需要使用訓練中最佳成果的模型best.pt,來應用驗證於非訓練集資料中的圖像,這也是AI模型應用最終的核心。另外同樣地要告訴電腦,我想要預測的圖像資料放在哪個位置,因此在source路徑記得替換修改。
Step6:使用模型預測。
# 6. 預測
results = model.predict(
source="./乙丙級電繪-2/test/images", save=True, save_txt=True, project="runs/detect", name="predict")
# source路徑記得根據替換修改
完成上一步預測後,Colab會自動設定存檔的位置,那要找出資料放置的地方,可以使用以下的代碼來查詢。
Step7:尋找預測資料夾位置。
# 7. 自動尋找最新資料夾
import os
def get_latest_folder(base_dir, prefix):
folders = [
os.path.join(base_dir, f)
for f in os.listdir(base_dir)
if os.path.isdir(os.path.join(base_dir, f)) and f.startswith(prefix)
]
if not folders:
print(f"找不到 {base_dir} 下的 {prefix}* 資料夾")
return None
latest_folder = max(folders, key=os.path.getmtime)
print(f"最新 {prefix} 資料夾:{latest_folder}")
return latest_folder
detect_dir = "runs/detect"
predict_folder = get_latest_folder(detect_dir, "predict")
train_folder = get_latest_folder(detect_dir, "train")
如果找到預測資料夾位置,想先瀏覽一下成果,則用以下代碼以方格預覽方式呈現(如圖9.3)。
Step8:預覽預測結果。
# 8. 批次方格預覽
import matplotlib.pyplot as plt
import glob
from PIL import Image
image_paths = sorted(glob.glob(os.path.join(predict_folder, "*.jpg")))
# [使用者可自訂]
n_cols = 2 # 欄
n_rows = 2 # 列
n_images = n_cols * n_rows
if len(image_paths) == 0:
raise FileNotFoundError(f"{predict_folder} 下沒有找到任何 jpg 檔案,請確認推論結果")
plt.figure(figsize=(n_cols*4, n_rows*4))
for i, img_path in enumerate(image_paths[:n_images]):
img = Image.open(img_path)
plt.subplot(n_rows, n_cols, i+1)
plt.imshow(img)
plt.title(os.path.basename(img_path))
plt.axis('off')
plt.tight_layout()
plt.show()
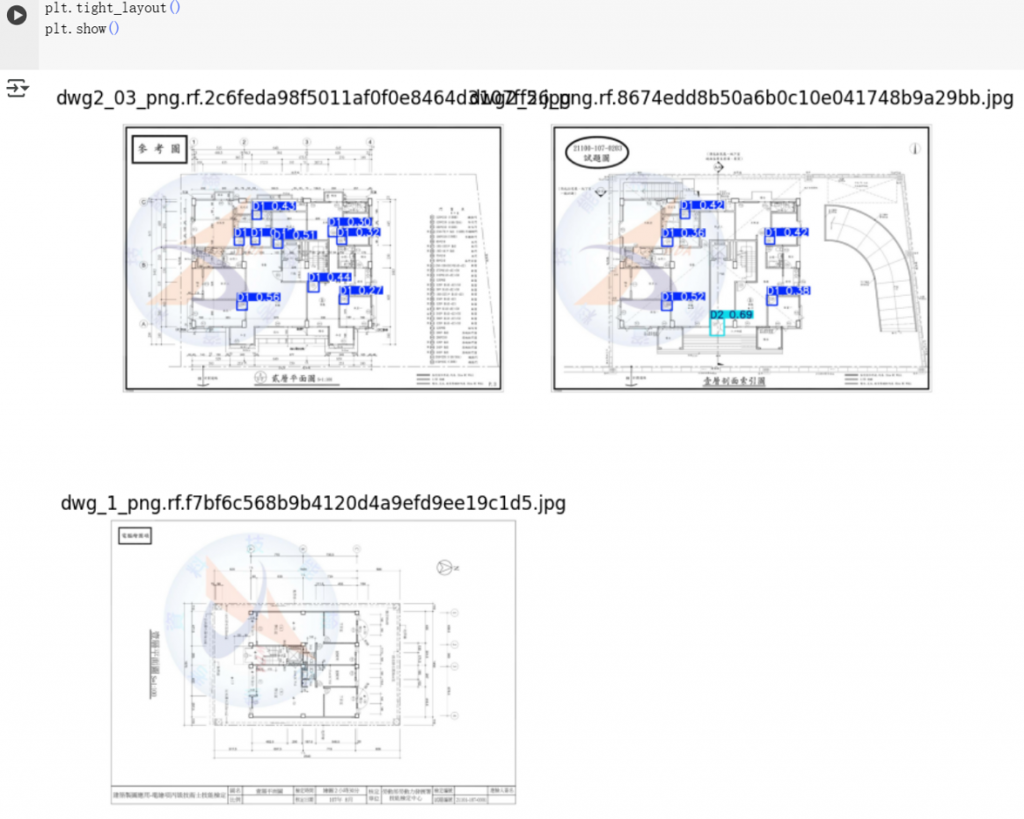
圖9.3 方格預覽結果
最後,我們可以使用以下代碼將結果下載。
Step9:壓縮結果。
# 9. 合併並壓縮
import shutil
all_dir = "/content/all_results"
# 先清空舊的 all_results 資料夾
if os.path.exists(all_dir):
shutil.rmtree(all_dir)
os.makedirs(all_dir, exist_ok=True)
# 複製預測資料夾
if predict_folder and os.path.exists(predict_folder):
shutil.copytree(predict_folder, os.path.join(all_dir, os.path.basename(predict_folder)))
# 複製訓練資料夾
if train_folder and os.path.exists(train_folder):
shutil.copytree(train_folder, os.path.join(all_dir, os.path.basename(train_folder)))
# 壓縮 all_results
zip_name = "all_results.zip"
shutil.make_archive(zip_name.replace('.zip', ''), 'zip', all_dir)
print(f"已壓縮全部成果到 {zip_name}")
Step10:下載檔案。
# 10. 下載
from google.colab import files
if os.path.exists("all_results.zip"):
files.download("all_results.zip")
今天我們學習如何從Google Colab的環境建置,再到YOLO模型訓練、預測的全流程,明天我們將學習預測結果所代表的各項意義,以便學習應當如何來優化訓練的結果。

