當模型訓練和預測完成後,如何知道這個模型是好是壞呢?本篇將延續上一篇,從訓練過程指標圖,進一步解讀模型優劣,以及預測成果所代表的意義。
在前一篇最後的預測成果中,我們將下載檔案開啟,可以看見YOLOv8 所匯出訓練過程中的各種曲線圖、辨識成果快照等,如下圖10.1。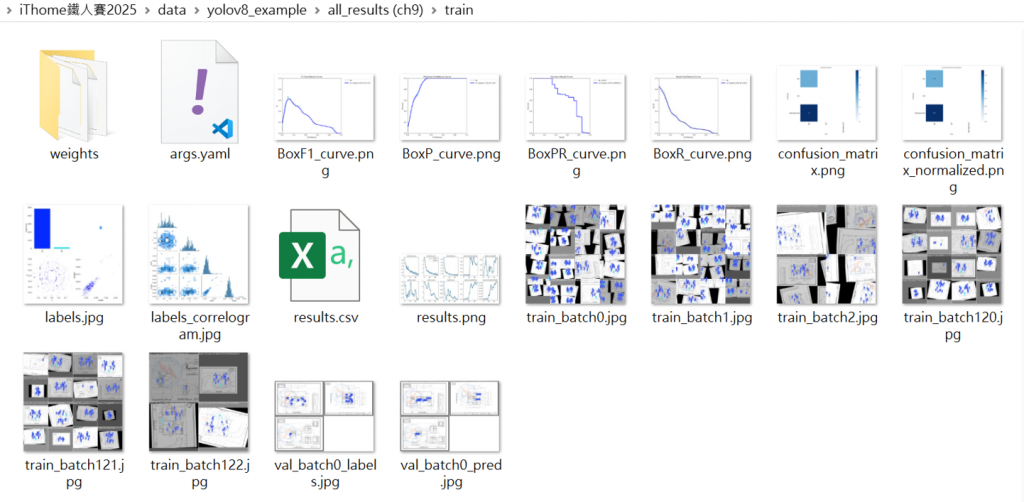
圖10.1 訓練過程匯出成果
首先,我們在訓練過程中會看見每次訓練迭代(Epoch)都會輸出如下圖10.2的數據。其中,我們可以簡單了解主要四個常見的重要指標、以及results曲線圖所代表的涵義: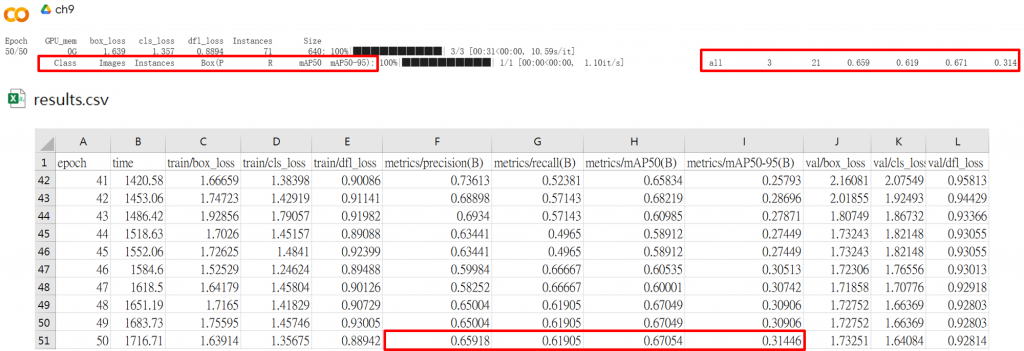
圖10.2 訓練迭代輸出數據
「模型猜對的比例有多少?」
例:模型抓到10個門,裡面有8個是真的門,precision 就是 8/10 = 80%。
「應該要抓到的門,模型漏掉多少?」
例:照片中有10個門,模型只找到6個,recall 就是 6/10 = 60%。
這個指標是根據「模型預測框」和「正確答案框」的重疊程度(IoU)來判斷,就像你畫一個框,看跟正確答案重疊多少。完全重疊是100%,完全沒碰到就是0%。
總之,mAP 分數越高,代表模型不只會抓對目標,連位置都標得很準~
F1-score是精確率(precision)和召回率(recall)的綜合平均分數,是反映「兩邊都兼顧」的整體表現。舉例來說,假設圖像裡有 10 扇門都正確標記,模型只抓到了 2 扇門,且沒有誤抓(沒有把不是門的東西當成門):
雖然這個模型的精確率很高,但實際上遺漏了許多應該要抓到的門,所以用 F1-score 綜合評分後,結果只有 33.3 分(若以 100 分為滿分),可以說「分數被拖低了」,因為只重視其中一個指標是不夠的。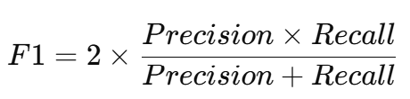
圖10.3 F1-score公式
最後,若要綜觀整個模型的訓練狀況,例如本案例中results曲線圖,其部分曲線有呈現局部上下起伏的情況, 這通常是在某些訓練迭代時,資料集裡剛好出現比較難辨識的影像,讓 loss 暫時升高;反之,若遇到容易的資料則 loss 會暫時降低。
因此,曲線偶爾上下起伏是正常的,只要整體趨勢是「loss 下降、mAP 上升」,就不用太在意小幅起伏。但若長時間無法改善、或指標反常,就應該檢查資料集或調整訓練參數。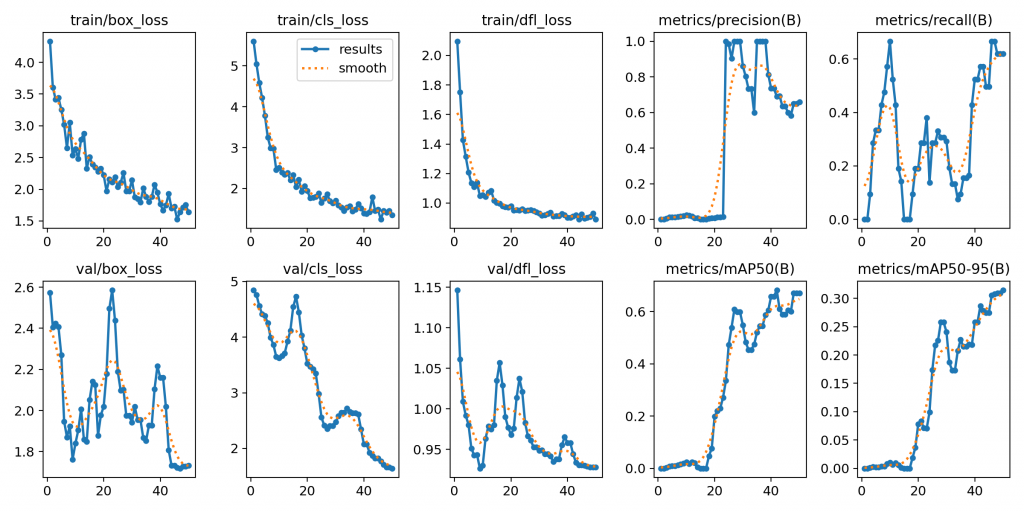
圖10.4 results曲線圖
我們在前篇已有將訓練成果下載為壓縮檔,要進一步驟證模型效能,可以在Colab新增筆記本並按以下操作步驟:
Step1:安裝YOLO套件。
# 1. 安裝 YOLO
!pip install ultralytics
Step2:上傳已訓練best.pt權重檔。
# 2. 上傳 best.pt
print("請上傳你的 best.pt 權重檔案")
uploaded = files.upload()
Step3:上傳訓練資料集壓縮檔並解壓縮。
# 3.上傳並解壓縮資料集壓縮檔
print("請上傳你的資料集壓縮檔 (例如 dataset.zip)")
uploaded = files.upload()
import zipfile
# 自動抓取上傳的第一個zip檔案名稱
for filename in uploaded.keys():
if filename.endswith('.zip'):
zip_path = filename
break
else:
raise ValueError('請上傳一個 zip 檔案!')
# 解壓縮到 /content/
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall('/content/')
print(f'已自動解壓縮 {zip_path} 到 /content/')
Step4:自動搜尋best.pt位置(再次確認路徑)。
# 4.自動搜尋 best.pt
from ultralytics import YOLO
import os
def find_bestpt(start_dir='/content'):
for root, dirs, files in os.walk(start_dir):
if 'best.pt' in files:
return os.path.join(root, 'best.pt')
raise FileNotFoundError("找不到 best.pt!")
bestpt_path = find_bestpt()
print(f'自動找到 best.pt 路徑:{bestpt_path}')
Step5:驗證模型。
# 5. 驗證模型 (假設你的 data.yaml 也在 /content)
model = YOLO(bestpt_path)
results = model.val(data='data.yaml', split='val')
print("Precision(Box(P)):", results.box.p)
print("Recall(R):", results.box.r)
print("mAP50:", results.box.map50)
print("mAP50-95:", results.box.map)
今天我們學習到預測結果所代表的各項意義,這是我們再優化調整訓練的關鍵基準,明天的內容,將進一步以大數據訓練過的案例成果,和現有模型做一個明確對照,帶你實際感受「調整後的成效」有多大差異。

