

在 Day 5 提到的 Index Scan & Bitmap Scan 中,我們知道透過 Index 讀取資料時,通常會有兩個步驟:
但每一次查詢,都需要 Heap Fetch 嗎? 其實並不一定。今天要介紹的 Index-Only Scan,就只需要 Index Lookup ,就能返回查詢結果啦。
An Index-Only Scan is a type of index scan where PostgreSQL retrieves all required columns directly from the index without accessing the actual table (heap). This improves performance by avoiding unnecessary disk I/O.
這是因為 Index 內存的內容剛好是查詢需要的結果時,就不用再多一步 Heap Fetch 的步驟,可以解少 I/O 讓效能變快。
測試:用 Index-Only Scan 加速查詢
product table 來舉例:CREATE TABLE products (
id SERIAL PRIMARY KEY,
category TEXT NOT NULL,
name TEXT NOT NULL,
price NUMERIC NOT NULL,
stock INT NOT NULL
);
category 來篩選資料,但查詢時只需要 price 這個欄位,可以用 INCLUDE 來建立(INCLUDE 是什麼意思我們待會會來看看)CREATE INDEX idx_category_price ON products(category) INCLUDE (price);
EXPLAIN ANALYZE
SELECT price FROM products WHERE category = 'Electronics';
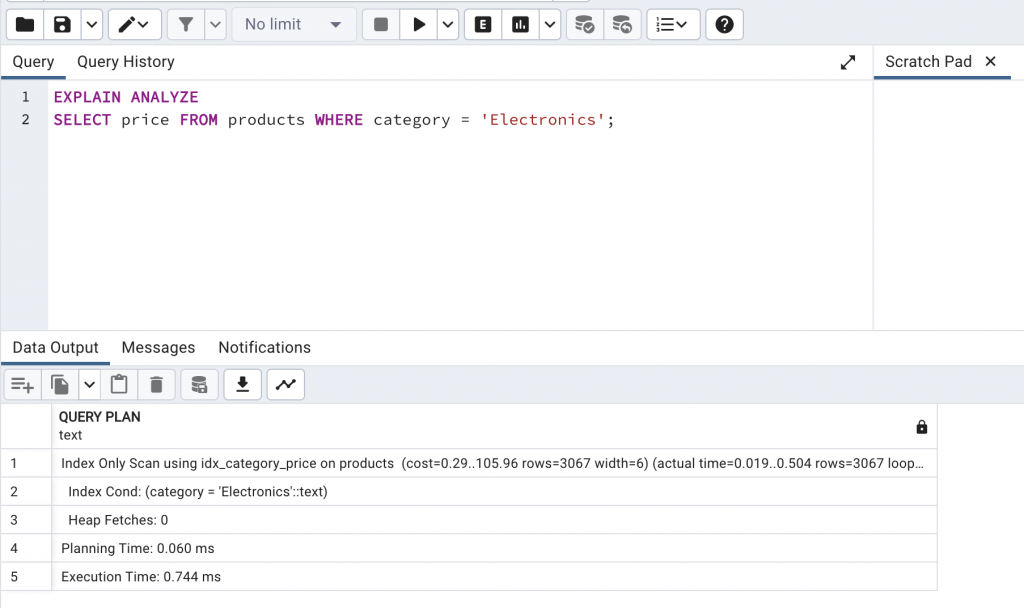
這裡可以看到成功的使用到 Index-Only Scan 了!因為這樣查詢時,只使用到 category 和 price,都已經在 Index 中,避免了 Heap Fetch。
INCLUDE 是什麼意思?
當我們想有效利用 Index-Only Scan 的功能時,可以選擇建立 Covering Index。它是特別用來設計包含某個常用查詢所需要的所有欄位(在我們的舉例中需要的欄位為 price ,查詢常用欄位為 category)。由於查詢通常不只需要搜尋條件中的欄位,PostgreSQL 允許你在 Index 中額外加入一些「附帶」欄位,這些欄位不屬於搜尋(search key),純粹是為了讓查詢能直接從 Index 取得所需資料。
要這麼做,只需要在建立 Index 時使用 INCLUDE,列出那些額外的欄位即可。
To make effective use of the index-only scan feature, you might choose to create a covering index, which is an index specifically designed to include the columns needed by a particular type of query that you run frequently.
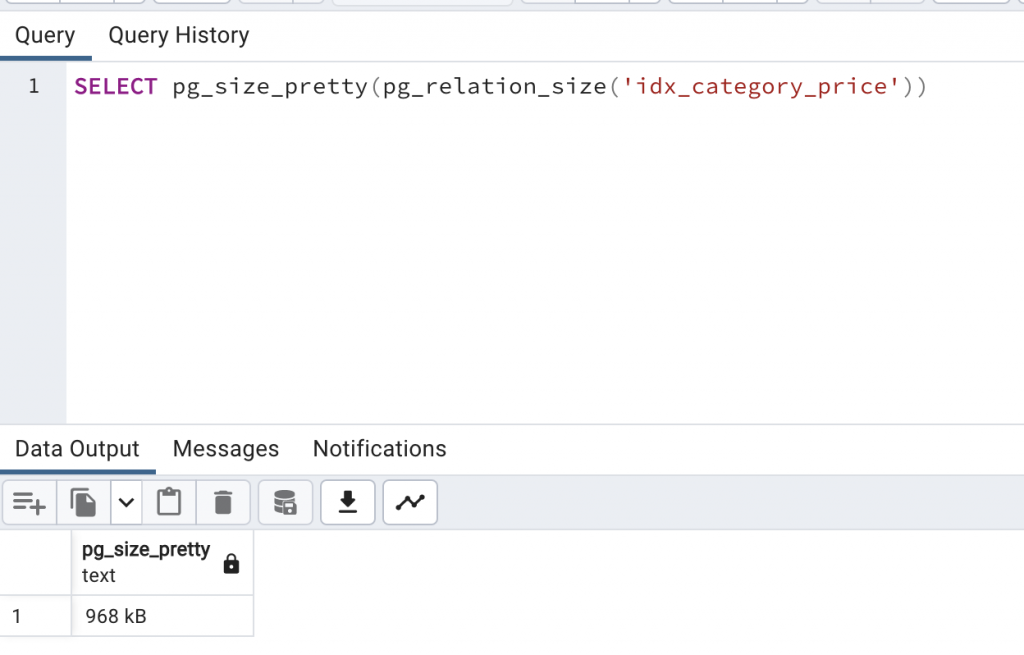
在這裡我們先記錄一下 Index 的大小,總共是 968 KB。
SELECT pg_size_pretty(pg_relation_size('idx_category_price'))
比較:使用 INCLUDE vs 沒有使用 INCLUDE
如果我們沒有使用 INCLUDE 以及 Index-Only Scan,而是讓搜尋時需要 Heap Fetch,他的速度以及 Index 的大小會是如何呢?我們就接著來看看。
DROP INDEX idx_category_price
INCLUDE
CREATE INDEX idx_category_price ON products(category)
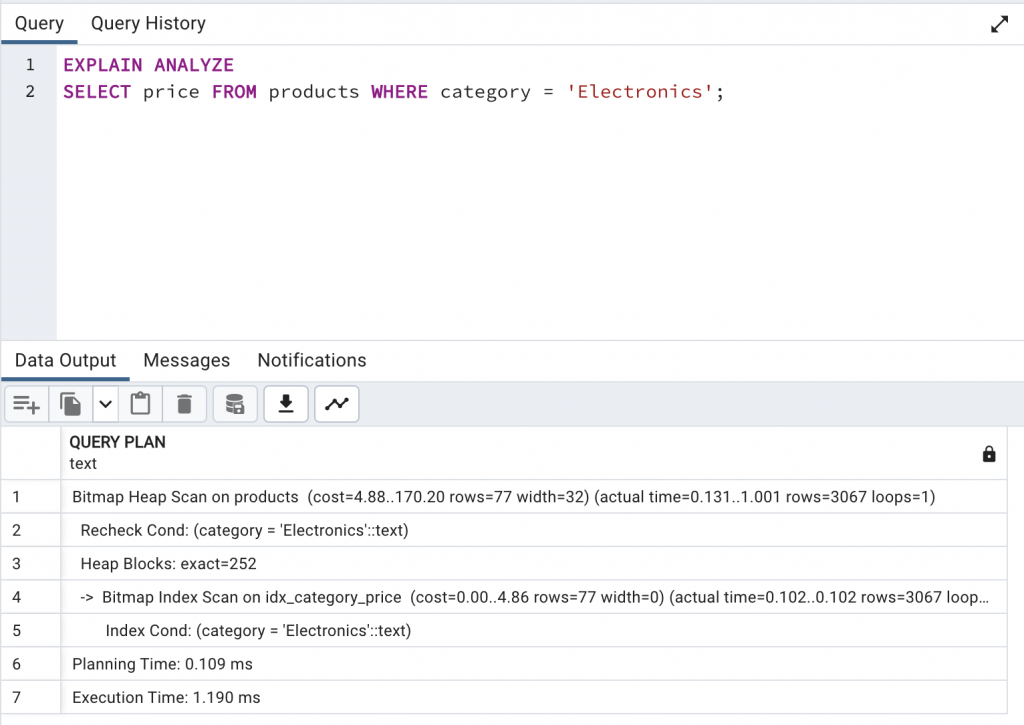
這次沒有 Index-Only Scan 了,使用的是 Bitmap Scan,因為 price 欄位沒有在 Index 中,所以要再回 Heap 找到資料。搜尋速度為 1.190 ms ,比第一種方法稍微慢一些些(0.744 ms)。
那麼再來看一下第二種方式的 Index 大小:
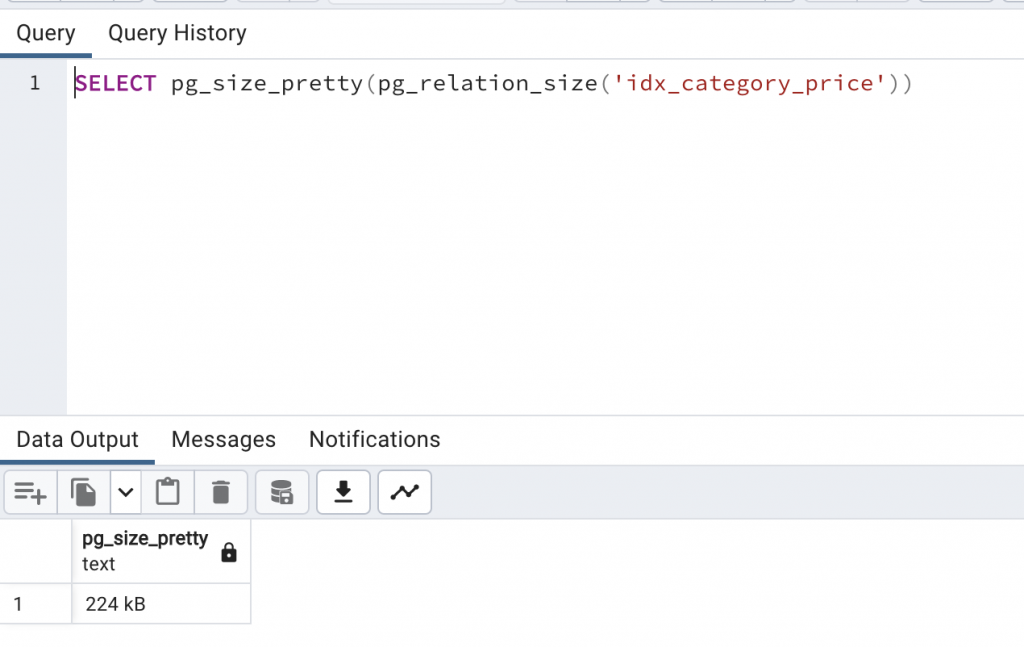
| Type | INCLUDE | 沒有 INCLUDE |
|---|---|---|
| Size | 968 KB | 224 KB |
可以發現使用 INCLUDE 的 Index 比較大,看到這裡,大家應該都能知道為什麼了吧?因為第一個版本的方式將查詢資料的欄位也都存在 Index 內了,雖然少了 Heap Fetch 速度比較快,但是儲存空間就會比較大。我們又再一次驗證了 Index 是用「空間換取時間」的概念!也因此想要使用 Index-Only Scan 的話,就要記得使用時的這些取捨。
CREATE INDEX tab_x_y ON tab(x) INCLUDE (y)
https://www.postgresql.org/docs/current/indexes-index-only-scans.html

 iThome鐵人賽
iThome鐵人賽