在Day13我們發現文字辨識結果中,字形相近與名詞拆分的誤判,很大部分原因應該來自簡繁體共存所造成的影響;另外在Day14雖然已經解析每筆資料的定位點,但要如何進一步還原圖紙空間呢?今天我們一起來看看:
前篇已將文字辨識結果的定位Excel資料下載,接下來依以下操作步驟繼續處理:
Step1:首先,新增Colab筆記本,並安裝必要套件。
# 1. 安裝必要套件
!pip install opencc-python-reimplemented openpyxl
Step2:上傳Excel檔。
# 2. 上傳Excel檔
from google.colab import files
uploaded = files.upload()
Step3:讀取Excel檔及預覽資料。
# 3. 讀入Excel
import pandas as pd
import opencc
excel_file = list(uploaded.keys())[0]
df = pd.read_excel(excel_file)
print(df.head()) # 預覽前5行
Step4:簡體轉繁體。
# 4. 強制簡體轉繁體(針對「文字」欄)
converter = opencc.OpenCC('s2tw')
df['文字'] = df['文字'].apply(lambda x: converter.convert(str(x)))
print('轉換完成')
以偵測門物件為例,在建築平面中標示會以Door縮寫D作為前墜,例如D1代表是編號1的門,並另以門窗圖做細部材質、尺寸等標示。
因此,我們可以透過這樣特定的規則,篩選分析出指定的物件項目,也縮小在龐大資料行中搜尋的範圍;另外,在工程圖上,同一物件的相關標註通常都集中在偵測物件的附近,因此以中心點作為定位分群依據,可以將空間鄰近的資訊聚合為一組,而DBSCAN是一種「基於距離」的自動分群演算法,它只需要你設定一個「最大鄰近距離」(eps),能在不需預先指定群數的情況下,將空間鄰近的點自動歸為同群,所以能較直覺地還原圖紙上的文字分布情形。
以下就是用程式定義這套篩選規則的步驟範例:
Step5:語意分類與空間分群。
# 5. 語意分類及圖紙空間還原
import re
# 篩選「門編號」Dxx(自動容錯全形D、小寫、空白、全轉大寫)
def normalize_text(t):
t = str(t).replace('D', 'D').replace('d', 'D').strip().upper()
t = re.sub(r"\s+", "", t)
return t
regex = re.compile(r'^D\d+$')
df['正規化文字'] = df['文字'].apply(normalize_text)
door_df = df[df['正規化文字'].apply(lambda x: bool(regex.match(x)))].copy()
# 只分析有中心點的資料
door_df = door_df.dropna(subset=['中心點_x', '中心點_y'])
# DBSCAN分群
from sklearn.cluster import DBSCAN
import numpy as np
X = door_df[['中心點_x', '中心點_y']].astype(float).values
db = DBSCAN(eps=50, min_samples=1).fit(X) # eps需依你圖面調整
door_df['分群編號'] = db.labels_
Step6:分群結果匯出及下載。
# 6. 分群結果匯出及下載
door_df.to_excel('門編號分群結果.xlsx', index=False)
files.download('門編號分群結果.xlsx')
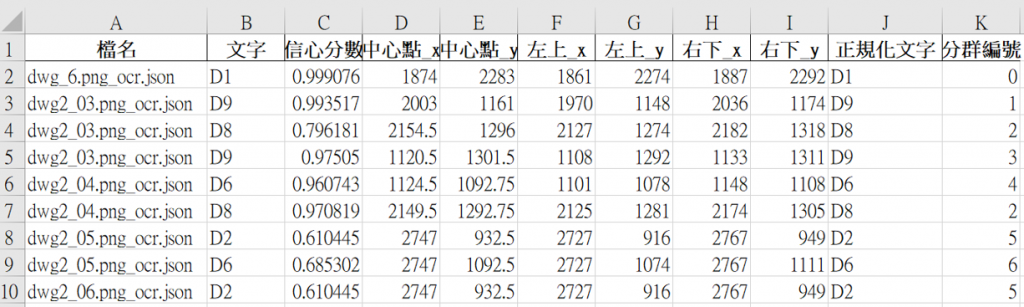
圖15.1 門編號分群結果示例
本系列採OCR應用於建築圖實作,從圖說中擷取文字資料、文字資料的清理與重塑、取得文字框定位,再到今天的語意分類,這些技術步驟能大幅提升資料處理的自動化與效率,為後續BIM建模與工程數據整合打下基礎。
當然,進一步應用於不同類型的工程圖面與案例優化,還是需要依各專案的資料型態與實務的專業經驗來判斷,雖然本範例中的實驗結果並非最佳,但對於整體流程應用的可行性,增添了進一步想像。
那介紹OCR的篇章就到這裡結束啦!明天起,我們將進入BIM與IFC資料建構的世界,探索更高階的建築智慧化建模方法!

