上一篇實作PaddleOCR的辨識成果可以發現,一行一行雜亂無序的資料是難以進行分析的。今天,我們將實作規劃出OCR結構化資料所需的關鍵欄位,使每一個項目在資料標準化及自動化流程中都有其功能,以利進行後續的分類、詞庫比對與分析。
為了能夠定位出原本文字辨識框的位置點、作為後續語意判斷依據,我們會需要以下這些基本資訊:
我們在Day12操作流程的Step3中,已經有將文字辨識框的中心點資訊同步下載為json檔,以下的步驟即是匯入json資料格式後,解析計算為上述資料結構列表:
Step1:首先,上傳 OCR JSON。
# 1. 上傳 OCR JSON
from google.colab import files
import json
uploaded = files.upload()
json_files = list(uploaded.keys())
print("已上傳:", json_files)
Step2:處理轉換(中心點、左上、右下座標)。
# 2. 處理轉換(中心點、左上、右下座標)
import pandas as pd
all_data = []
for json_file in json_files:
with open(json_file, 'r', encoding='utf-8') as f:
data = json.load(f)
for obj in data:
text = obj.get('text', '')
box = obj.get('box', [])
center = obj.get('center', [None, None])
confidence = obj.get('confidence', None)
# 取左上與右下
if box and len(box) == 4:
x1, y1 = box[0]
x2, y2 = box[2]
else:
x1 = y1 = x2 = y2 = None
all_data.append({
"檔名": json_file,
"文字": text,
"信心分數": confidence,
"中心點_x": center[0],
"中心點_y": center[1],
"左上_x": x1,
"左上_y": y1,
"右下_x": x2,
"右下_y": y2
})
df = pd.DataFrame(all_data)
df.head(10) # 預覽前10筆
Step3:下載檔案。
# 3. 下載檔案
df.to_excel("OCR標註標準化表格.xlsx", index=False) # 匯出成 Excel
from google.colab import files
files.download("OCR標註標準化表格.xlsx")
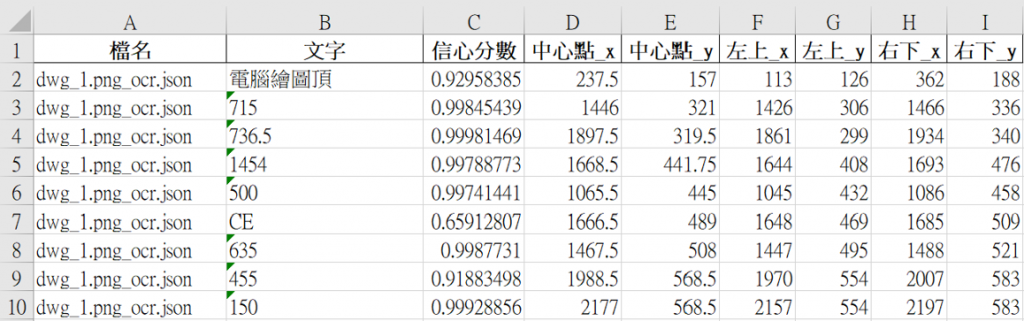
圖14.1 文字資料結構化示例
今天我們將原本一行一行文字轉化為具有位置點資訊的資料。下一篇,我們將更進階的來處理文字語意的部分,明天見!

